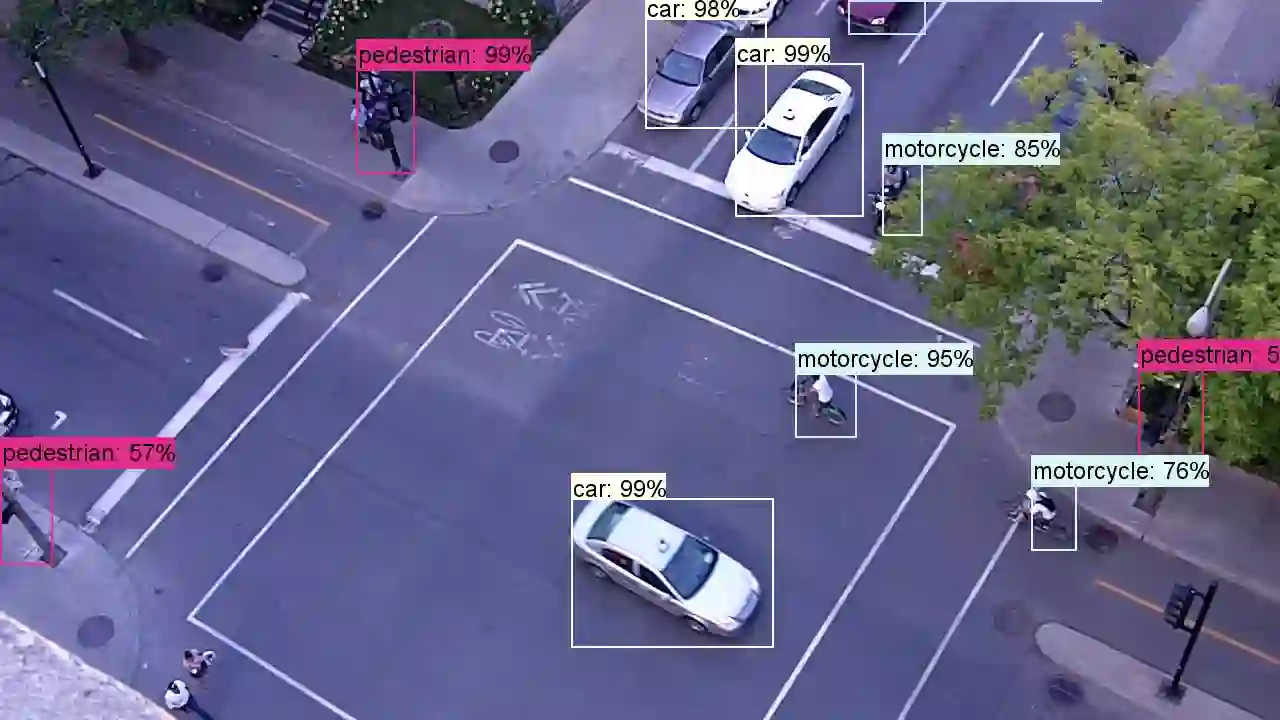
Multiple object tracking (MOT) in urban traffic aims to produce the trajectories of the different road users that move across the field of view with different directions and speeds and that can have varying appearances and sizes. Occlusions and interactions among the different objects are expected and common due to the nature of urban road traffic. In this work, a tracking framework employing classification label information from a deep learning detection approach is used for associating the different objects, in addition to object position and appearances. We want to investigate the performance of a modern multiclass object detector for the MOT task in traffic scenes. Results show that the object labels improve tracking performance, but that the output of object detectors are not always reliable.
翻译:在城市交通中,多物体跟踪(MOT)旨在生成不同道路使用者的轨迹,这些道路使用者以不同方向和速度跨视域移动,其外观和大小各异。由于城市公路交通的性质,预计不同物体之间的排斥和互动是常见的。在这项工作中,除了目标位置和外观外,还使用一个使用从深层学习探测方法获得的分类标签信息的跟踪框架将不同物体联系起来。我们要调查交通现场交通交通交通任务中现代多级物体探测器的性能。结果显示,物体标签改善了跟踪性能,但物体探测器的输出并不总是可靠。