使用模仿学习攻克Atari最难游戏!DeepMind新论文解读
文:CreateAMind陈七山
论文名:Playing Hard Exploration Games by Watching YouTube
https://arxiv.org/pdf/1805.11592.pdf
DeepMind上周发布的论文,在几个公认对AI来说难度极大的Atari游戏:Montazuma's Revenge, Pitfall, 和 Pirate Eye上都表现出了超越人类的水平。
以下两张图为论文方法的效果,可以感受一下AI行云流水般的操作:


1关于模仿学习
模仿学习(Imitation Learning)是智能体学习的关键部分,从小孩学习发声说话,到学写字临摹字帖,都是通过模仿来学习某种技能。对于很多复杂的强化学习任务,探索空间庞大,奖励稀疏因而难以学习。这时如果引入一些专家示范,指引模型一步步的行为,就能极大减少探索空间,从而完成复杂任务。
模仿学习的思路大概分为两种:一种是逆向强化学习(Inverse Reinforcement Learning)[1],关注如何从专家的示范中抽象出目标函数;另一种则是行为复制(Behavioral Cloning)[2],让模型遇到相近的情形时,做出与专家相同的反应。
考虑一个马尔科夫决策过程(Markov Decision Process, MDP)的序列 (State1, Action1, State2, Action2 ... )。最简单的行为复制,就是让模型拟合专家的决策序列,使其在遇到专家示范过的State时,有产生对应Action的能力。
这篇文章也是采取了行为复制的思路,而专家示范取材于YouTube上的人类玩家游戏的视频。但如果直接应用最简单的行为复制模仿学习,是存在以下两个问题的:1. 如下图所示,由于尺寸,分辨率等原因,测试时的画面与学习的视频有细微不同,观察抽象得到的State也不同。2. 视频中并没有动作信号(键盘操作),所以不能直接拟合Action。
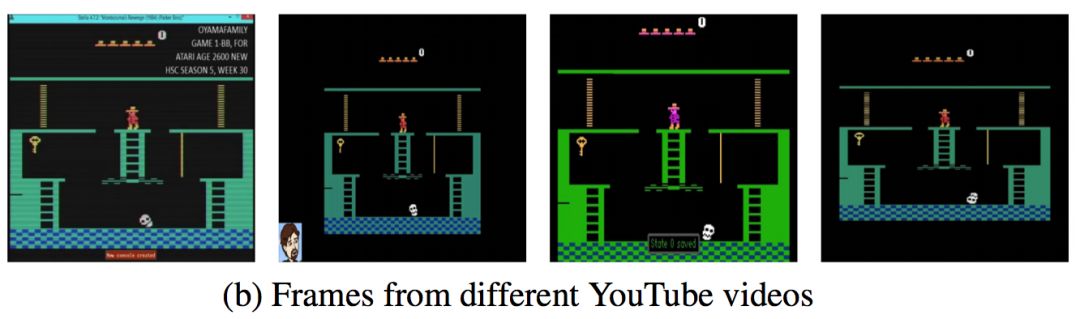
对应的解决方法是:1. 通过游戏状态相关的视频图像投影,来消除视频画面差异的影响。2. 在模仿学习中结合强化学习来探索Action。接下来我将详细介绍这两个方法。
2游戏状态相关的视频图像投影
对于上述第一个问题,一种方法是与Third-Person Imitation Learning[3]中的方法类似,设计一种变换将环境目标环境直接变换过来,从而修正环境的差异。但本文作者创造性地设计了时序距离分类(Temporal distance classification, TDC)的附加任务,得到游戏状态相关的视频图像投影,将游戏状态相近的视频Frame投影到相近的State。
考虑多个不同来源的游戏视频图像,图像中的游戏状态(主人公和怪物的位置,道具的有无等)是关键的要素,而画面噪点,颜色的微小差异都应该被忽略掉。也就是说,如果将这些游戏图像投影到低维空间里时,投影只与图像中的游戏状态相关,而与画面颜色尺寸差异无关,那么不同视频来源之间的画面颜色和尺寸差异就成功地被忽略了。
正是基于这个思想,作者提出构建一种保持图像游戏状态信息的投影方法。如下图,图b中4个来源不同的游戏视频的投影用4种颜色表示在c和d中,图c是作者提出的投影方法,而图d是直接使用源图像源像素直接做投影。可以看到,图a中红色的角色移动路径在c中也是一条路径,说明c是保留了游戏状态信息,而忽略了画面差异的投影。而在d中,视频来源相同的图像聚类在了一起,不能表示出a中的游戏路径,说明主要聚类依据是视频来源的画面因素。
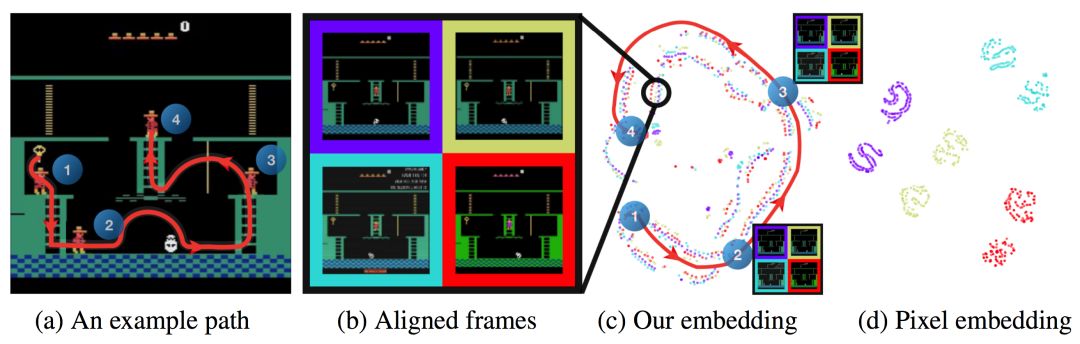
形成与游戏状态相关的投影的具体做法是,定义一个时序距离分类(Temporal distance classification, TDC)辅助任务。如下图,φ函数表示投影函数,v和w为视频中任意提取的两帧。训练一个分类器τ,τ(φ(v), φ(w)) 的作用是分类出v帧和w帧之间的时间差是多大,例如图中红框标出的[3 - 4],即是说v帧和w帧之间的时间差3在[3, 4]这个区间内。

为了分类出任意两帧之间的时间差,模型需要理解图像中角色和道具的运动和变化规律,这就使得投影函数φ拥有了表示游戏状态的能力。有了游戏状态相关的投影函数φ,就能够得到游戏状态序列供模仿学习参考。作者通过设计一个看似无用的辅助分类任务,就得到了游戏状态相关的投影函数,方法十分巧妙。
3与强化学习(RL)结合
对于之前第二个问题,即是说视频中并没有包含操作信号(键盘输入),不能直接拟合Action的问题,解决方法较为简单。虽然没有Action,但是有待模仿的状态序列,就可以使用一个简单的强化学习去探索出这些Action。具体来讲,Reward设置如下式:
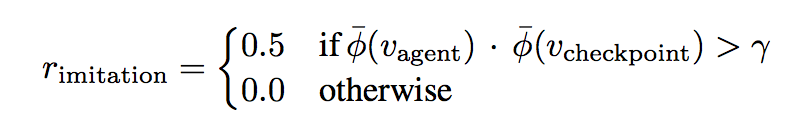
φ函数表示投影函数,这个Reward设计的意思是,如果Agent在执行Action后得到的结果状态φ(agent),与模仿序列中的某个状态足够相似,则获得奖励。checkpoint是模仿序列的一个时间指针,表示当前到达模仿序列哪一个位置了。如果Agent的结果状态与序列第 (checkpoint + i)个位置的状态最相近,且相近程度大于阈值γ,那么就给与Agent奖励,并将新的checkpoint设置为 (checkpoint + i)。这样就结合强化学习实现了模仿学习。
4模型实验结果
为了更好地探索游戏环境,作者在模仿学习的奖励的基础上,也加入了游戏环境本身得分Reward,这样能得到更好的性能,实验结果如下表:
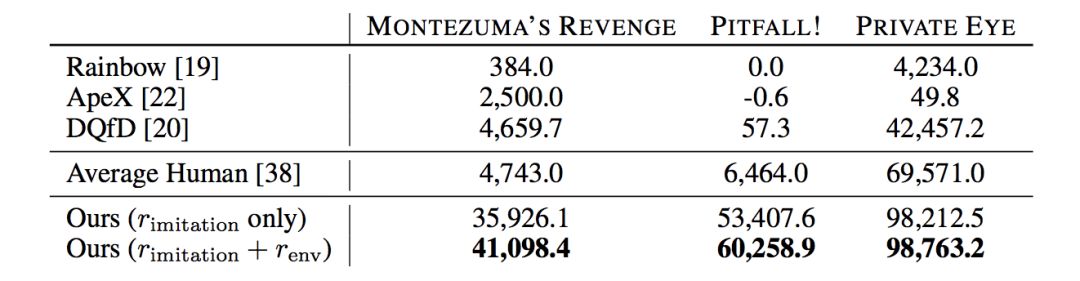
其中Rainbow[4],和ApeX[5]是非模仿学习的方法,DQfD[6]是一个带专家Action信息的模仿学习方法,公众号之前介绍的层次强化学习的方法也只能达到Average Human的水平。可以看到该模型的性能远远超过了之前的模型。
5总结
模仿学习近期出现了很多令人兴奋的结果,包括学习武术动作的DeepMimic[7],与Planning结合以完成复杂机械臂寻路的UPN[8],以及拓展为Conditional Imitation Learning来学习自动驾驶[9]等。
然而,模仿学习基础上的强化学习探索较为困难,迁移能力也相对较差[10]。模仿学习如何理解模仿内容的含义,而不再简单地鹦鹉学舌;抑或是如何在模仿学习基础上拓展,做到青出于蓝。这些都有待我们进一步探索。
[1] Pieter Abbeel and Andrew Y Ng. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the twenty-first international conference on Machine learning, page 1. ACM, 2004.
[2] Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation. arXiv preprint arXiv:1805.01954, 2018.
[3] Bradly C Stadie, Pieter Abbeel, and Ilya Sutskever. Third-person imitation learning. arXiv preprint arXiv:1703.01703, 2017.
[4] Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improvements in deep reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence, 2017.
[5] Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado van Hasselt, and David Silver. Distributed prioritized experience replay. International Conference on Learning Representations (ICLR), 2018.
[6] Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Horgan, John Quan, Andrew Sendonaris, Gabriel Dulac-Arnold, et al. Deep q-learning from demonstrations. Proceedings of the AAAI Conference on Artificial Intelligence, 2017.
[7] Peng, Xue Bin, et al. "DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills." arXiv preprint arXiv:1804.02717 (2018).
[8] Srinivas, Aravind, et al. "Universal Planning Networks." arXiv preprint arXiv:1804.00645 (2018).
[9] Codevilla, Felipe, et al. "End-to-end driving via conditional imitation learning." arXiv preprint arXiv:1710.02410 (2017).
[10] Dosovitskiy, Alexey, et al. "CARLA: An open urban driving simulator." arXiv preprint arXiv:1711.03938 (2017).
我们是骥智智能科技上海有限公司。我们致力于通用人工智能的无人驾驶研发,关注强化学习方法,视觉无监督语义级特征的生成模型技术,以及深度学习认知研究。




