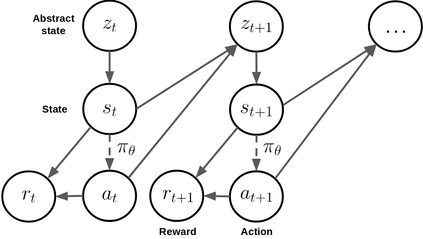
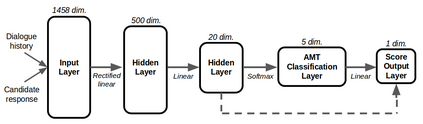
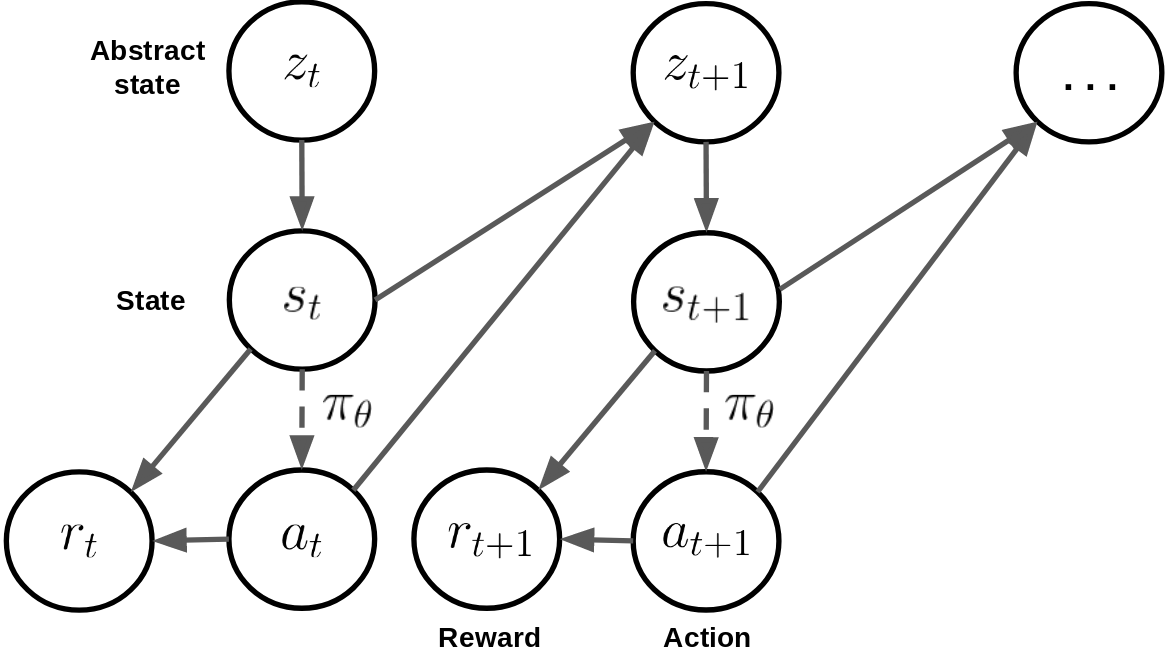
Deep reinforcement learning has recently shown many impressive successes. However, one major obstacle towards applying such methods to real-world problems is their lack of data-efficiency. To this end, we propose the Bottleneck Simulator: a model-based reinforcement learning method which combines a learned, factorized transition model of the environment with rollout simulations to learn an effective policy from few examples. The learned transition model employs an abstract, discrete (bottleneck) state, which increases sample efficiency by reducing the number of model parameters and by exploiting structural properties of the environment. We provide a mathematical analysis of the Bottleneck Simulator in terms of fixed points of the learned policy, which reveals how performance is affected by four distinct sources of error: an error related to the abstract space structure, an error related to the transition model estimation variance, an error related to the transition model estimation bias, and an error related to the transition model class bias. Finally, we evaluate the Bottleneck Simulator on two natural language processing tasks: a text adventure game and a real-world, complex dialogue response selection task. On both tasks, the Bottleneck Simulator yields excellent performance beating competing approaches.
翻译:深层强化学习最近取得了许多令人印象深刻的成功。然而,将这种方法应用于现实世界问题的一个主要障碍是它们缺乏数据效率。为此,我们建议采用基于模型的强化学习模拟器:一种基于模型的强化学习方法,该方法将一个已学的、因素化的环境过渡模型与推出模拟结合起来,以便从几个例子中学习有效的政策。学习的过渡模型使用一种抽象的、离散的(瓶颈)状态,通过减少模型参数的数量和利用环境的结构特性来提高抽样效率。我们用学习政策的固定点来提供对博特勒内克模拟器的数学分析,该模拟器揭示了四个明显的错误源是如何影响业绩的:一个与抽象空间结构有关的错误,一个与过渡模型估计差异有关的错误,一个与过渡模型估计偏差有关的错误,以及一个与过渡模型等级偏差有关的错误。最后,我们评估了两个自然语言处理任务:文字探险游戏和真实世界、复杂的对话反应选择任务。关于这两个任务,博特伦·西姆拉托托的出色业绩竞拍。