RCurl中这么多get函数,是不是一直傻傻分不清!!!

你想知道R语言中的RCurl包中一共有几个get开头的函数嘛,今天我特意数了一下,大约有十四五个那么多(保守估计)!
所以如果对这个包了解不太深入的话,遇到复杂的数据爬取需求,自然是摸不着头脑,心碎一地~_~
实际上很多我们都不常用,常用的不超过五个,而且这些函数命名都很有规律,一般是类似功能的名称中都有统一的关键词标识,只要理解这些关键词,很好区分,下面我对9个可能用到的get函数简要做一个分类。
第一类是get请求函数(参数直接写在URL里面)
getURL #get请求的一般形式 getBinaryURL #get请求二进制资源 getURLContent #get请求(可以根据返回状态的ContentType决定返回内容是文本格式还是二进制格式, #所以说它其实就是前两个函数的结合体,可以根据返回内容类型做智能判断) getURIAsynchronous #这个函数文档给的解释是可以实现请求的异步发送和多并发,需要计算机的cpu支持多核性能,至今尚未尝试过!以下两个也是get请求函数(参数可以写在单独的查询参数中)
getForm #单独提交查询参数的get请求函数 getFormParams 可以根据带参数的URL,分解出原始参数对容错与配置句柄函数
getCurlErrorClassNames #排错函数,可以根据请求错误信息得到错误类型,方便后期排错 getCurlHandle #curl句柄函数(是请求回话维持与进程管理的最重要部分,所有登录操作、身份认证都都需要该函数的支持) getCurlInfo #根据curl句柄的记录信息,返回各项目信息详情接下来我们逐个尝试一遍上述函数的用法。
getURL
getURL函数是一个基础get请求函数,其核心参数主要有URL、.opt、curl、.encoding。
URL就是请求的对应网址链接。
curl参数是一个句柄函数,它的参数指定对象是一个内嵌函数,通常是curl = getCurlHandle(),getCurlHandle()函数内同样是配置信息,不过curl句柄函数内的所有配置信息是可以提供给全局使用的,多次携带,维持整个回话状态,相对于一组初始化参数,而.opt参数内的各项配置信息是当前get请求使用的,它会覆盖和修改curl句柄函数内的初始化信息(当没有提供.opt参数时,get请求仍然使用curl中的初始化参数。)
.opt是一个配置参数,它就收一组带有命名的list参数,这些通常包括httpheader、proxy、timeout、verbose、cookiefile(cookiejar)等配置信息。
.encoding是字符集编码,这个通常可以通过请求的相应头ContType获取。
使用getURL发送一个完整的请求一般形式是这样的:
library("RCurl")
library("XML") debugInfo <- debugGatherer() #错误信息收集函数
headers<-c("User-Agent" = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36") ###curl句柄函数
handle <- getCurlHandle( debugfunction = debugInfo$update, followlocation = TRUE, cookiefile = "", verbose = T ) url<- "https://edu.hellobi.com/"
response<-getURL(
url, ###URL地址
#局部配置参数(作用于本次请求)
.opts=list(header=TRUE,httpheader = headers),
curl=handle, ###curl句柄,初始化配置参数(.opts内的声明的配置参数会覆盖curl中的默认参数)
.encoding="utf-8" ###编码参数
)
请求成功!
以上是getURL的一般形式,当然实际使用时,可以酌情调整参数,通常情况下,无需维持回话的话,curl不需要自己构造,函数会默认帮我们构造以个curl句柄。但是.opts参数使我们在当前请求中实际应用的配置参数信息,需要特别注意。
cat(debugInfo$value()[1]) #服务器地址及端口号
cat(debugInfo$value()[2]) #服务器返回的相应头信息
cat(debugInfo$value()[3]) #返回的请求头信息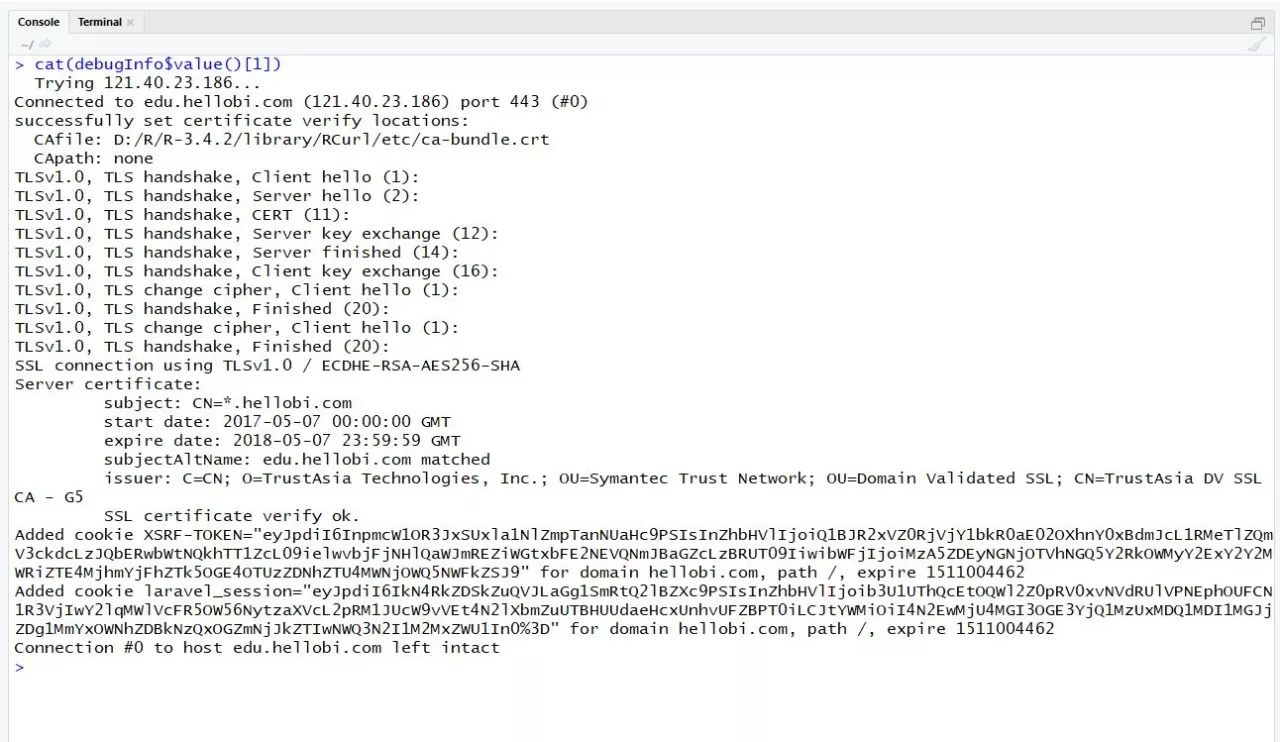
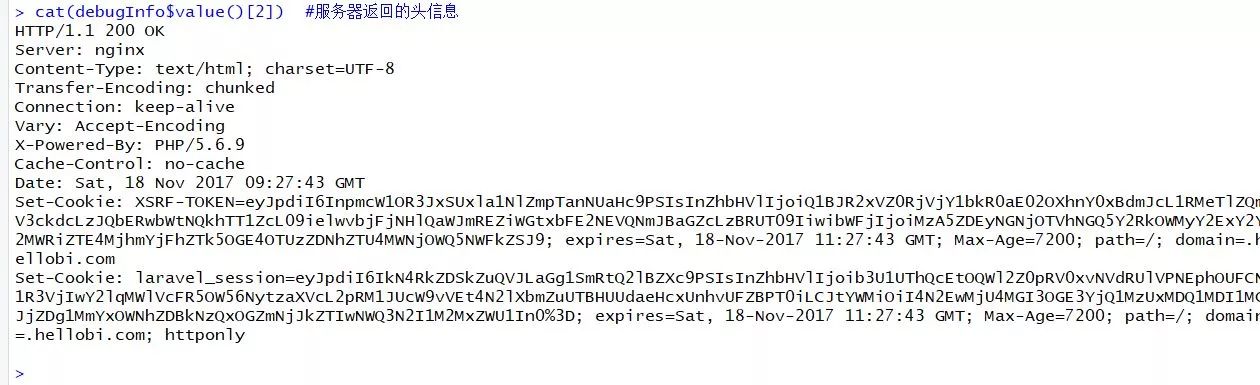
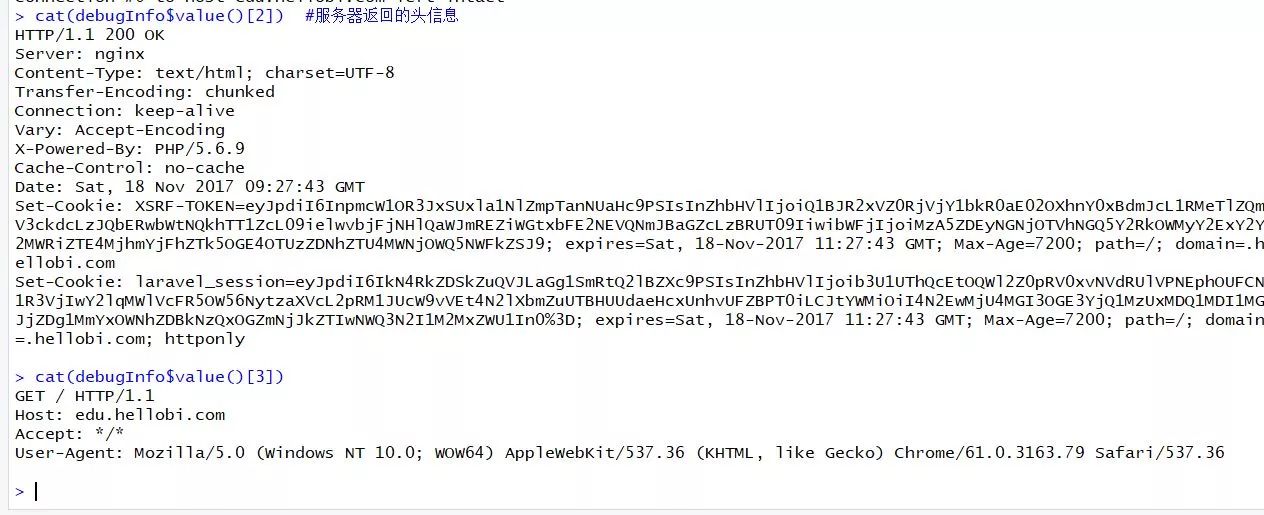
debugGatherer函数收集的请求与相应信息对于后期的错误判断与bug修复很有价值!
getBinaryURL
二进制资源一般是指网络服务器上的二进制文件、图像文件、音视频等多媒体文件。这些资源通常可以直接通过download函数进行请求下载,但是getBinaryURL函数可以添加更多配置信息,在 请求资源是更加安全。
url<-"https://pic3.zhimg.com/720845d4f960c680039dbf7cc83ec21a_r.jpg"
response<-getBinaryURL(url) writeBin(response,"720845d4f960c680039dbf7cc83ec21a_r.jpg")
你可以使用%>%管道函数把两句封装在一起,使用起来非常方便,比自带的download函数代码参数还少。除了图片之外,csv文件、xlsx文件、pdf文件、音视频文件都可以下载。
response<-getURLContent("https://pic3.zhimg.com/720845d4f960c680039dbf7cc83ec21a_r.jpg") response<-getURLContent("https://edu.hellobi.com/") class(response) [1] "raw"
[1] "character"使用getURLContent请求网页时,返回的是字符串(未解析的HTML文档),请求图片时,反回的是bytes值。不那么讲究的场合,getURLContent可以替代getURL或者getBinaryURL,但是通常为了便于记忆,一般请求网页使用getURL,请求二进制文件使用getBinaryURL,实际上三个函数仅仅是返回值的差异,通过参数设置的转换,基本可以相互替代。
getURIAsynchronous函数运行执行多并发任务,具有异步请求的功能,但是这一块我还没有研究透彻,至今尚未涉足,感兴趣的小伙伴儿可以自己试一试,将请求URL作为一个多值向量,闯进去就可以了,勇于探索才能学到好玩的东西。
getForm
getForm发送单独携带查询参数的get请求,这在之前的趣直播数据抓取中已经演示过了。
library("magrittr") url<-"http://m.quzhiboapp.com/api/lives/listOrderByPlanTs"
header=c(
"Accept"="application/json, text/plain, */*",
"User-Agent"="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36"
) debugInfo <- debugGatherer() handle<-getCurlHandle(debugfunction=debugInfo$update,followlocation=TRUE,cookiefile="",verbose = TRUE) content<-getForm(url,.opts=list(httpheader=header),.params=list("limit"=30),.encoding="utf-8",curl=handle) %>% jsonlite::fromJSON() ###请注意这里getForm函数与getURL函数的区别
###(多了一个.params参数,它就是用于存放get请求的参数的,getFrom可以提供专门的查询参数)
head(content %>% `[[`(2))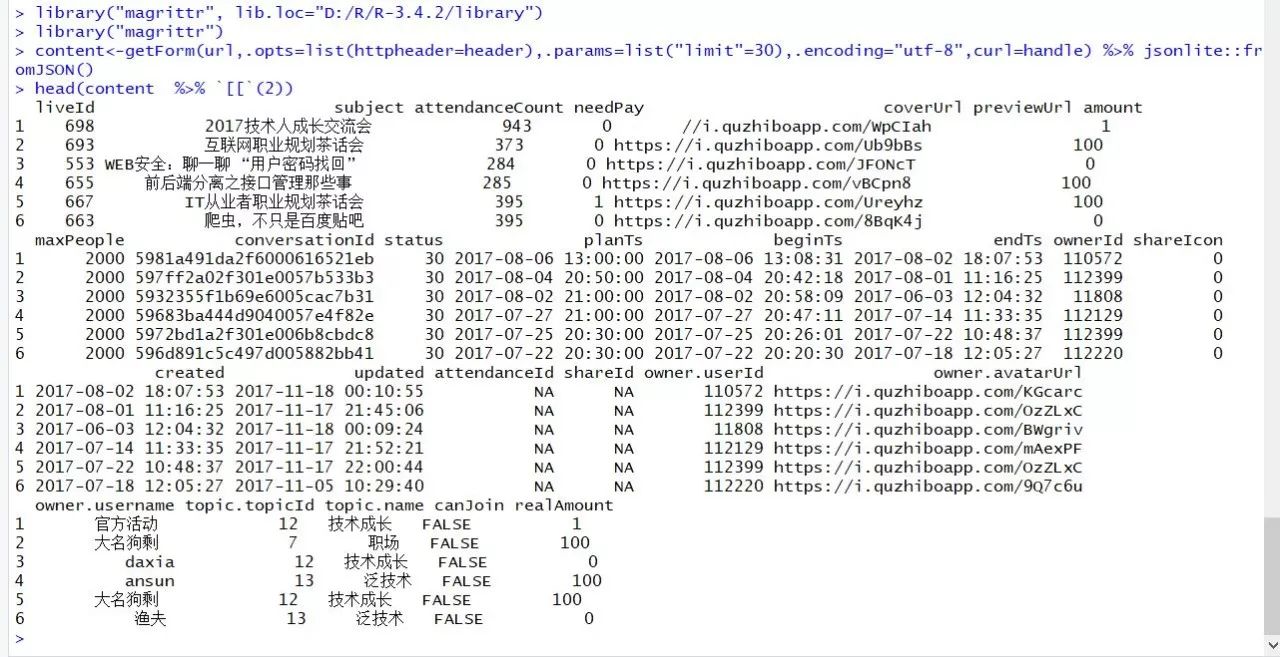
getFormParams
getFormParams函数可以还原URL中的查询参数。
url<-"https://www.baidu.com/s?wd=writeBin&rsv_spt=1&rsv_iqid=0xe52332670003a3de&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&rsv_t=222fgx%2FjxyaSTATqTxa8ljEv1u8i5TvyENqvcB1Ku1QcP3ZUR2pqIQ2sntZFOTlA4NJx&oq=writeBin%2520%25E4%25B8%258B%25E8%25BD%25BD%25E5%259B%25BE%25E7%2589%2587&inputT=1300&rsv_sug3=13&rsv_pq=e9db342c0003c543&rsv_sug1=6&rsv_sug7=100&rsv_sug2=0&rsv_sug4=1940&rsv_sug=1"
getFormParams(url)
还原结果是一个带有命名的字符串向量。
getCurlErrorClassNames 函数是一个排错函数,具体怎么用我也不知道,目前还没有用过,感兴趣的自己探索!
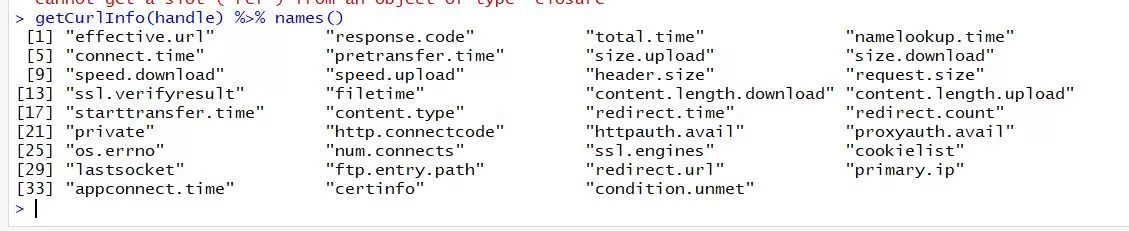
getCurlHandle\getCurlInfo
getCurlHandle 函数是全局的curl句柄函数,包含所有请求、相应以及本地终端与web服务器之间的通讯记录。它用于构建初始化配置函数。它通常与getCurlInfo 搭配使用。
debugInfo <- debugGatherer()
#错误信息收集函数
headers<-c("User-Agent" = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36") handle <- getCurlHandle( debugfunction = debugInfo$update, followlocation = TRUE, cookiefile = "", verbose = T ) url<- "https://edu.hellobi.com/"
response<-getURL(url,.opts=list(header=TRUE,httpheader = headers),curl=handle,.encoding="utf-8")比如可以通过getCurlInfo 函数获取handle中的所有信息。
getCurlInfo(handle) %>% names() cat(getCurlInfo(handle)$effective.url) https://edu.hellobi.com/ cat(getCurlInfo(handle)$response.code)200cat(getCurlInfo(handle)$content.type) text/html; charset=UTF-8cat(getCurlInfo(handle)$cookielist) .hellobi.com TRUE / FALSE 1511007061 XSRF-TOKEN eyJpdiI6IkRLcndIcW0raVF3aDNkbjJRRVJwTHc9PSIsInZhbHVlIjoiRkFDMWdCdEJ4dGFOYTJBaWV2c3pHZm1IOHZoOW81eisxaFJENzJSRnVGXC9TQnZKTDRjZFQ3NlpicnVoODF3N0U3VTZuNXJHREtYbDR5SDc5YkREMGVnPT0iLCJtYWMiOiIzNWI2OTYyYWNlZmQwMDc1N2Q1Y2I5NTY4NzUxZWIzYWYwZDM0N2MzZmExMzQ1OGJlNDVjNmZiMzEwMWY4MjEwIn0%3D #HttpOnly_.hellobi.com TRUE / FALSE 1511007061 laravel_session eyJpdiI6Ik8zN3NUMjFjN2FRa1dldXZ4REhVTnc9PSIsInZhbHVlIjoiQ29kakpTRjFGdno5c2Y0elpSZWNhVFVpckJWTnRwaENaeHgxSThmOXRDNDU0T0k1djlUV011ZlBEQXV5N2drc3NBOHBzY0FWZEJSRG1ocjNweGpXNnc9PSIsIm1hYyI6IjZjOWRlMmNjMjg3MGM3MTEzZDA0N2M2OTdkNGUwYWM3MzY0N2MwNmJmYmMxZDAzYTllODEzZjQ0YWUzNjA4NjQifQ%3D%3D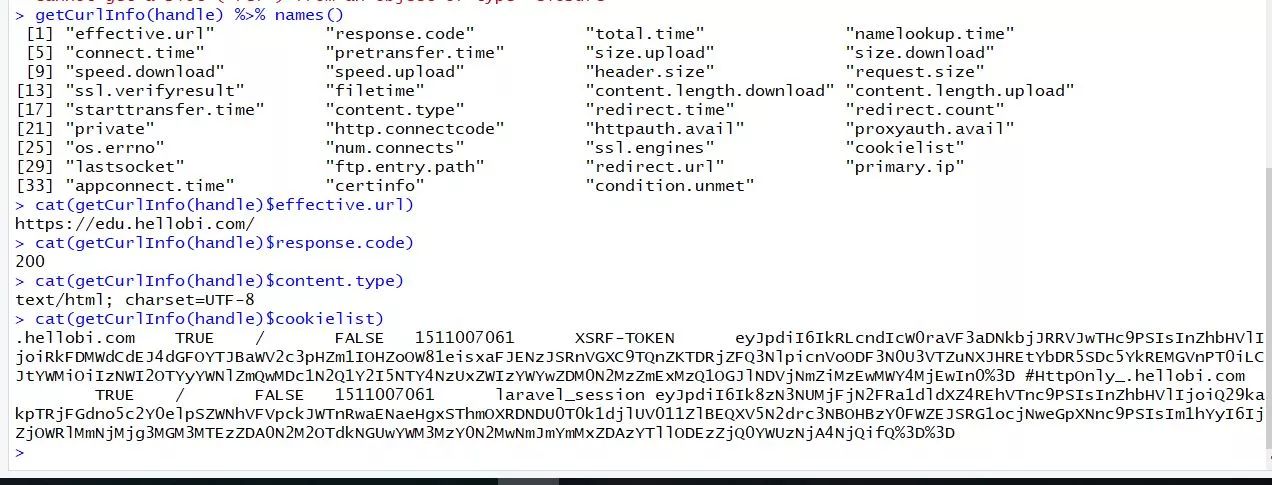
好了,到这里,RCurl的几个重要get函数几乎都已经讲完了,接下来会抽时间整理一下RCurl的中postForm函数的四种常见参数提交方式,以及curl句柄函数配置参数的权限类型,RCurl这个包经过这些时间的梳理,已经扒的差不多了,以后若是时间允许,可以探索一下RCurl中的并发与异步请求实现方式。
其实除了RCurl之外,rvest包也有很多好玩的东西,最近的探索发现,rvest本身并不神奇,它作为一个底层请求器httr以及解析器selectr包、xml2包的封装,整合了这些包的优点,在解析方面大有可为,但是请求功能上很薄弱,它的css解析器实现其实是在内部调用selectr包中的css_to_xpath函数,将css语法转化为xpath之后才开始解析的,这样如果你能花些时间学一下xml2\httr\selectr的话,几乎可以完全绕过rvest包,自己灵活构建请求与解析函数了,这三个包文档都很少(httr稍多一些!)。
还计划想写一篇关于R爬虫与Python对比的文章,R语言与Python在很多领域一直相爱相杀,Python的DataFrame貌似参考了R里面的data.frame,并且移至了R语言中的ggplot2,而R语言中,哈德利写的xml2包是由BeautifulSoup激发的的灵感,rvest包的初衷参照requests的框架,以后没事儿多八卦一些R语言与Python背后的故事,感觉蛮好玩的!
在线课程请点击文末原文链接:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File
相关课程推荐
R语言爬虫实战案例分享:
网易云课堂、知乎live、今日头条、B站视频
分享内容:本次课程所有内容及案例均来自于本人平时学习练习过程中的心得和笔记总结,希望借此机会,将自己的爬虫学习历程与大家分享,并为R语言的爬虫生态改善以及工具的推广,贡献一份微薄之力,也是自己爬虫学习的阶段性总结。

☟☟☟ 猛戳阅读原文,即刻加入课程。



