跟我学R爬虫|XML&XPath表达式与R爬虫应用

昨天跟微信上一不认识的同是搞数据技术的圈友聊天,我说最近在写一个R语言爬虫系列,想把Python爬虫那一套用R实现看看,刚开始在讲HTML和XML的内容。这位朋友是前端转数据库开发,说了一句HTML和XML这些知识还不简单,能看得懂英文的都能看得懂HTML代码,HTML连编程语言都不是,以现在搞互联网技术年轻人的学习能力,一上午就可以搞定。
借着这位大兄弟的鼓舞,louwill的学习激情又被燃到很高,今天就来继续更新R语言爬虫系列的第二期内容。在上一期里,louwill给大家介绍了HTML的基本语法和如何在R中用XML包对HTML进行解析。今天继续跟大家介绍一下一个跟HTML很像的内容——XML。
在此之前,louwill和广大吃瓜群众一样,看到XML和JSON这样的字眼就一脸懵逼,一直心想这都是些什么鬼,好好的excel数据不好吗。年轻人就是naive,总喜欢对自己不懂的东西指手画脚哈哈。好了,扯淡完毕,回归正题,下面就郑重地跟大家介绍XML以及与之相关的查询语言XPath表达式。
XML
吃瓜群众看标题点进来心里一定是这么想的:什么是XML?它有什么用?XML和HTML都什么区别和联系吗?我又该怎样使用XML?

XML(eXtensible Markup Language)全称叫做可扩展标记语言,首先它和HTML一样,是一门标记语言,那它就该有标记语言的全部特征,这是XML的共性。XML当然必须也有自己的特性,XML是被设计用来传输和存储数据的,这和HTML用来显示数据大不一样,所以XML又有网络数据交换最流行格式的美誉。先看一段XML代码:

上面的XML代码提供了三名NBA球员的一些基本信息,大家可以仔细阅读一下这个简短的代码,相信任何懂一点英文的朋友都可以毫无困难的读懂其中包含的数据。正如之前所提到的,XML首先是一门标记语言,它的语法特性和HTML别无二致,XML里的值和名字都被包裹在有含义的标签里,这三名球员都带有主队、姓名和所在城市信息,这种缩进的框架结构能够让我们轻易地看懂XML文档的架构。文档以根元素<nbaplayer>开始,也以它结束。
所以综上我们就了解了,XML是一种类似于HTML的标记语言,它的设计宗旨是传输数据,而非显示数据,在编写XML文档时,我们需要自行定义标签。作为一种纯文本格式,任何有处理纯文本能力的软件都可以拿来处理XML。
下面再简单介绍一下XML的语法规则,XML的语法其实和HTML很像,我们就以上面那个XML代码例子来说明:
1. 一个XML文档永远以声明该文档的一行代码来开头:
<?xml version=”1.0” encoding=”ISO-8859-1”?>
version=”1.0”用来声明该XML文档的版本号,目前就两个版本:1.0和1.1。encoding=”ISO-8859-1”表明声明编码格式。一提到编码,相信有着各种乱码经验的R使用者都应该有体会。
2. XML文档必须要有一个根元素,这个根元素包裹了整个文档,在上面的例子里,根元素是:
<nbaplayer>
...
<\nbaplayer>
XML是用来传输数据的,而这个数据通常是放在具体的XML元素中的。
3. 一个XML元素由起始标签和具体内容来定义,一个元素可以用一个闭合标签来结束,也可以在起始标签里用一个斜杠(/)来闭合。元素里可以包含其他元素、属性、具体数据等其他内容。我们来看上述例子中<city>元素:
<city name=”houston”> rockets </city>
它的组成部分有:
元素标题 city
起始标签 <city>
终止标签 </city>
数据值 <rockets>
关于XML还有其他的一些像注释、特殊字符命名、事件驱动等细节知识louwill在这里就不再细说了,感兴趣的朋友可以参考XML官方网站https://www.xml.com/。
如何在R语言中解析XML
在R语言中解析XML和解析HTML 是一样的道理,就是对XML原件产生一个能保留住原始文档结构的表征,然后据此从这些文件中提取想要的信息。在R语言中解析XML的过程实际上包括两个步骤,首先XML文件的符号序列会被读取并从元素中创建层次化的C语言树形数据结构,然后这个数据结构会通过使用处理器翻译为R语言的数据结构。
R中导入和解析XML文档的包就叫XML包,我们可以使用xmlParse( )函数来解析XML。和htmlParse( )函数较为类似,且看例子:
library(XML)
nbadata <- xmlParse(file="D:/Rdata/nbadata.xml")
nbadata
<?xml version="1.0" encoding="ISO-8859-1"?> <nbaplayer> <team> <city name="houston"> rockets</city> <player> james harden</player> </team> <team> <city name="boston"> celtics</city> <player> kyrie irving</player> </team> <team> <city name="goldenstates"> worriors</city> <player> stephen curry</player> </team> </nbaplayer>
简单的一个函数就可以使得一个完整的XML文档被解析到R里面去了。至于如何提取HTML和XML中我们想要的数据信息,方式有多种,但最方便快捷的那还是XPath表达式。
XPath表达式
所谓XPath表达式,并不是什么的高大上的东西,就是一种可以查询标记语言的方法,你可以把它理解为SQL一样的东西,louwill认为它比正则表达式要容易多了。简单来说,XPath表达式就是选取XML或者HTML文件中节点的方法,这里的节点,通常是指XML/HTML文档中的元素。
XPath通过路径表达式(Path Expression)来选择节点信息,跟文件系统路径一样使用“/”符号来分割路径。先来看看XPath表达式选择节点的基本规则:
nodename:选择该节点的所有子节点
“/”:选择根节点
“//”:选择任意节点
“@”:选择属性
还是以前面的XML文档作为例子:
nbaplayer:选取nbaplayer元素所有的子节点
/nbaplayer:选取跟节点nbaplayer
//team:选择所有的team子元素
//@name:选择所有的name属性值
除此之外,我们还可以通过给表达式附加一些条件来选择指定的数据,所有的筛选条件都可以附在一个[ ]符号中:
/nbaplayer/team[1]:选择nbaplayer下第一个team子元素
//city[@name]:选择带有name属性的team节点
基本的XPath表达式的语法内容就这么多啦,还有一些诸如通配符、多路径选择之类的大家可以自己去查找,这里就不继续展开了。熟练掌握XPath表达式是提高爬虫代码效率的重要因素,大家不妨对此重点学习一下。
SelectorGadget自动生成XPath表达式
另外,在最后louwill还想向大家推荐一款Chrome 插件:SelectorGadget。这是一款可以快速定位节点信息的CSS选择器插件,可以方便快捷的为大家生成网页中想要提取的信息的XPath表示,大家可以直接复制拿来放到R爬虫代码中去。下面就简单介绍一下这款神器的使用方法。
打开任意一款搜索引擎输入SelectorGadget,选择搜索结果中像下面这样的链接:
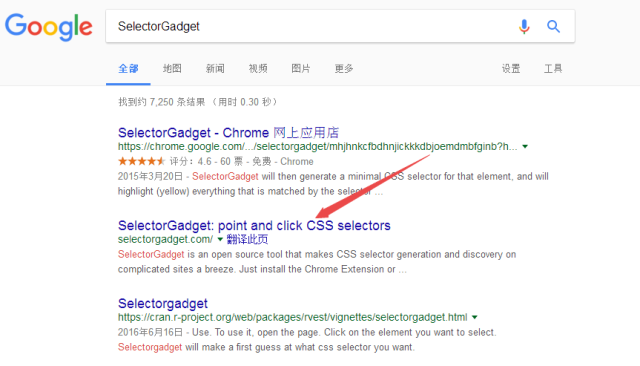
然后把点开的网页拉到底部,将带有下划线的蓝色字样的SelectorGadget拖拽到你的浏览器收藏夹:
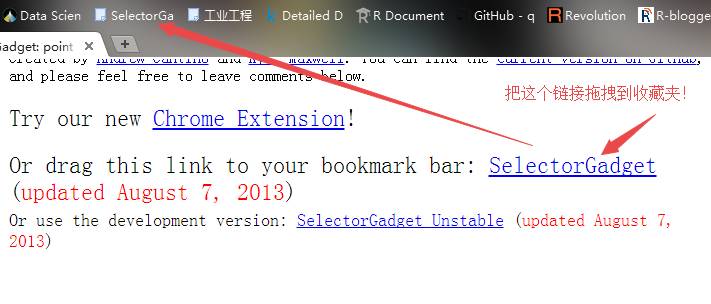
这样SelectorGadget选择器就安装完毕啦!
下次想要使用SelectorGadget来生成XPath表达式的时候,我们就可以在收藏夹点击一下它即可完成启动。以NBA官网为例说明一下:
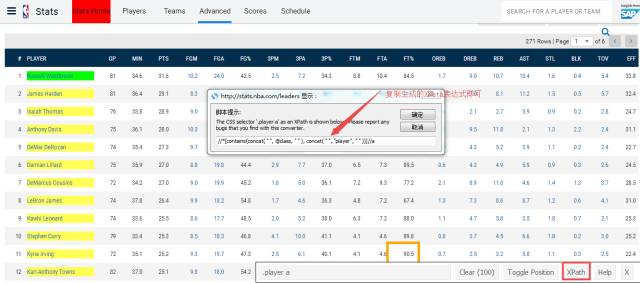
如上图红色箭头所示,在右下角选择XPath表达式后,网页会自动跳出一个框框,里面的代码就是XPath表达式啦!把它复制你的代码函数里就可以了!

参考资料:
Automated Data Collection with R
推荐阅读
Python微课:用Python验证你的策略吧!——Zipline回测
Python微课 | Seaborn——Python优雅绘图(上)
Python微课 | Seaborn——Python优雅绘图(下)
更多微课请关注【数萃大数据】公众号,点击学习园地—可视化


欢迎大家关注微信公众号:数萃大数据

网络爬虫与文本挖掘培训班【宁波站】
时间:2017年9月23日-25日
地点:维也纳国际酒店(机场店)
更多详情,请扫描下面二维码



