Kaggle大能源双榜金牌ASHRAE!教你如何避免过拟合,不shake的秘诀!昂钛客又双叒叕拿金牌了!
一、ASHRAE大能源预测?一个波折重重的比赛
你知道建筑耗能总量已经与工业耗能、交通耗能并列,成为我国能源消耗的三大“耗能之王”了么?建筑耗能不仅会让大型投资者和金融机构在这方面加大费用,同样随着能耗的变高,也会排出更多温室气体。
ASHRAE是这次比赛的赞助商,ASHRAE成员代表着世界各地的建筑系统设计和工业过程专家。他们希望能准确的对建筑物计量能源使用量进行预测,这样就能帮助设计能耗更低的建筑,降低建筑能耗费用,促进节能领域发展。
听起来是不是还挺有意思的?这个比赛也确实十分有意思可以说是kaggle有史以来最一波三折的比赛了。我们看看kaggle官网上参赛选手的评论:
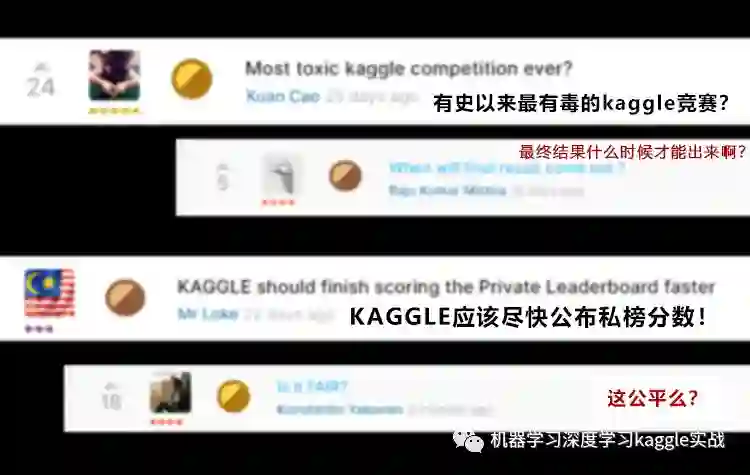
[炸锅了的比赛讨论区]
这次比赛不仅在过程中经历了数据泄露,在临要放榜时还因为恰巧赶上了圣诞节,平安夜,黑色星期五,元旦各种假日导致放榜时间一再延后,
你以为这就完了?
私榜结果一出,更是把这次比赛推向了高潮:A榜金牌大洗牌!众多参赛者一度跌出奖牌区!
二、2019大数据竞赛公榜金牌?怎料私榜泪两行!
ASHRAE大能源预测比赛中,公榜的第一名,第一时间便火速在kaggle平台讨论区上无私分享了自己的金牌经验。转眼到了kaggle赛方私榜放榜那天,第一名同学发现开榜时间延后了,又过了半个多月,第一名惊讶发现自己跌到了497名?这是什么样的魔鬼比赛如此残酷?
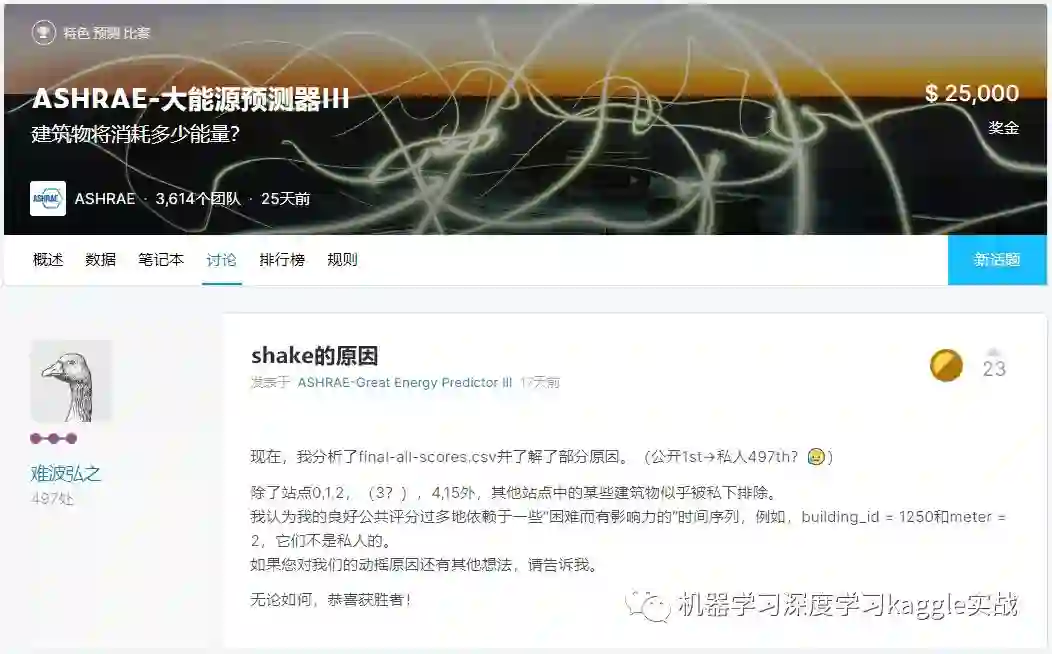
[私榜发布后原本的“第一名”发的帖子]
这次的比赛结果可以说让不少参赛者大跌眼镜,这不禁让人好奇,此次ASHRAE大能源预测比赛究竟难在哪?
比赛难点:提交次数比较少,只有两次;数据量大,对于内存不是很友好;后期数据的泄露使得整个比赛的结果跳水;过拟合严重排行榜金牌成绩只有我们保留,A榜金牌大洗牌!
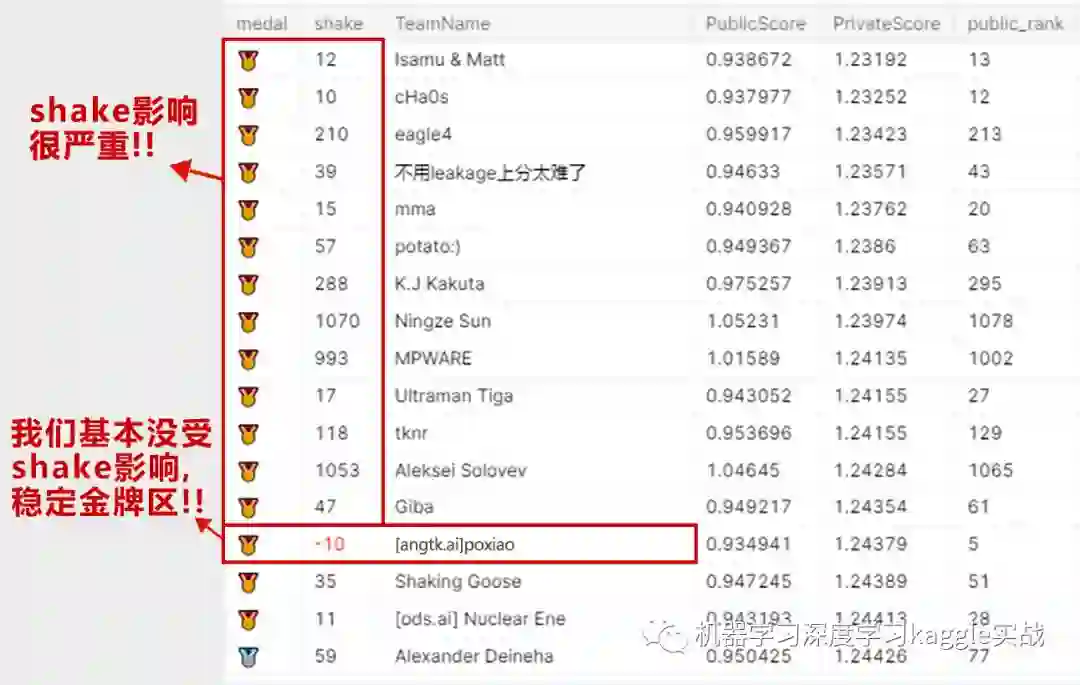
[图片来自kaggle官方]
由上可以看出本次比赛过拟合严重,是这次比赛最大的难点,很多以往的金牌得主受困于此,当场翻车。
重点来了!
我们将逐步带大家回顾一下这个比赛,并介绍一下我们是如何防止过拟合的。
三、防止过拟合的方法
首先应该将训练数据合理地分为训练集和验证集,保证自己有训练集、验证集和测试集。
之后,我们的评价标准就很清晰了,验证集结果和测试集结果越接近越好,一般来说,震荡不要超过2%,当然最好的情况是不要超过1%,例如验证集的准确率为92%,那么测试集应该在92±2%。
接下来我们总结在这个过程中可能出现的过拟合问题的原因:
1.验证集标签泄露:很多人喜欢先做特征工程再分割训练集和验证集,这样很可能导致标签泄露,造成过拟合;
2.验证集划分不合理:通常要求验证集和训练集的数据分布基本相同,可以通过计算欧式距离或者画图来查看分布;
3.测试集和训练集特征相差过大:在训练集和测试集中,一部分特征可能差距过大,例如:以天气距离,训练数据刚好是梅雨季节,测试数据是正常情况,那么就会产生较大的差异。
4.模型参数设计不合理:过低的学习率和较多的参数容易导致过拟合,我们一般在良好的验证集的指导下,能很快找到效果比较好的参数,而且不要忘记正则化。
四、本次比赛中的解决方案
1.模型融合:最好是选用不同特征下的不同模型的结果进行融合,在本次比赛中你还可以使用泄露的数据进行权重探索。
2.改变一部分数据的分布:例如:建筑物面积这样的参数,数值都比较大,我们可以使用log函数进行变换,这样可以让模型得到更好的效果。
3.构建简单且有用的特征:在模型中往往不是特征越多越好,按照奥卡姆剃刀定律,我们尽可能减少特征的数量,本次比赛中我们仅使用19个特征,且在添加该特征之前,我们还比较其分布等,保证其在训练集和测试集相似。

[奥卡姆剃刀]
4.使用泄露数据集进行对模型的正则:来判断是不是有过拟合,其效果相当于一个效果无限好的验证集。
关于泄露数据的使用:泄露数据本质相当于部分的测试集,所以拿来当作测试集使用即可
1) 直接拿来训练:相当于增加数据量的效果
2) 统计情况,发现例如停电,异常天气等不可控情况的发生(因为是时间序列的数据)
3) 用来当测试集,评估当前的模型效果
4) 用来确定部分超参数,进行模型融合
5.正则化变换:本次比赛中选用的都是树类算法,所以对于特征中的数据方差并不是很明显,但是当你选用包括深度学习在内的其他算法时,都应该对数据进行正则化变换。
6.数据增强:这个方法,在本次比赛中的应用仅限于使用泄露的数据添加进训练集;其实在数据类比赛中,数据增强很少用到,因为数据增强的合理性,很难界定,一般在图像中比较常见,例如在人脸图像增加一个小黑点,并不影响其还是一张人脸图片的事实。
以上只是我们技术分享的一部分,详细内容我们发布在了知乎上。
我们还有本次比赛的代码,感兴趣的小伙伴可以:
长按下方二维码关注公众号,回复“大能源”领取代码!










