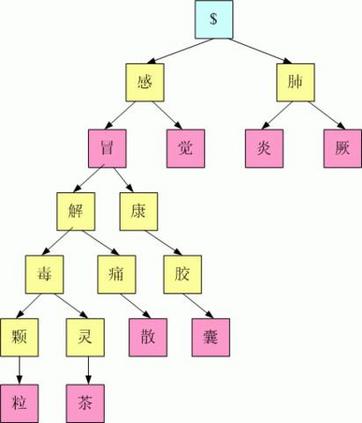
[情人节] jieba分词介绍

jieba 分词我觉得是Python中文分词工具中最好用的一个工具包。想要入门自然语言处理,jieba分词有必要好好掌握一下,今天带大家入门一下jieba分词包。
首先简单介绍一下jieba分词的原理,jieba分词采用的是基于统计的分词方法,首先给定大量已经分好词的文本,利用机器学习的方法,学习分词规律,然后保存训练好的模型,从而实现对新的文本的分词。主要的统计模型有:N元文法模型N-gram,隐马尔可夫模型HMM,最大熵模型ME,条件随机场模型CRF等。
jieba分词包含三个主要的类,分别是jieba,jieba.analyse, jieba.posseg。jieba类主要用于分词,analyse类主要用于文档关键词提取,tfidf计算等,posseg主要用于词性标注等。
下面我把jieba中涉及到的主要方法给大家做个小demo。
1. 分词
jieba分词基本的方法就是cut,cut_all这个参数的意思是,是否把所有分词的可能都切分出来,False为精确模式,True为全模式,这里情人节,因为情人也是一个词,所以全模式的时候就会把情人也分出来。这里到底要不要全切分出来,取决于实际的应用场景,如果是一个比较专业的领域,自己建立的词典不是很准确,这时候cut_all可以设置为True。HMM参数意思是,是否使用隐马尔科夫模型,一般为True。
import jieba
import jieba.posseg
import jieba.analyse
str1 = "今天是情人节,祝大家情人节快乐"
str1cut = jieba.cut(str1, cut_all=False, HMM=True)
out = " ".join(str1cut)
print(out)
"""
今天 是 情人节 , 祝 大家 情人节 快乐
"""
str1cut = jieba.cut(str1, cut_all=True, HMM=True)
out = " ".join(str1cut)
print(out)
"""
今天 是 情人 情人节 祝 大家 家情 情人 情人节 快乐
"""
第二个切词的方法是lcut,lcut返回的是一个list,而刚才的cut返回的是一个Python生成器。
import jieba
import jieba.posseg
import jieba.analyse
str1 = "今天是情人节,祝大家情人节快乐"
str1cut = jieba.lcut(str1, cut_all=False, HMM=True)
print(str1cut)
"""
['今天', '是', '情人节', ',', '祝', '大家', '情人节', '快乐']
"""
第三个切词的方法是posseg类里面的cut方法,它除了返回切词结果,还返回了词的词性,就是这个词是名词还是动词,还是形容词等。同样这里还有jieba.posseg.lcut方法,大家可以试一试。
import jieba
import jieba.posseg
import jieba.analyse
str1 = "今天是情人节,祝大家情人节快乐"
str1cut = jieba.posseg.cut(str1, HMM=True)
for w in str1cut:
flag, word = w.flag, w.word
print("{}, {}".format(flag, word))
"""
t, 今天
v, 是
n, 情人节
x, ,
v, 祝
n, 大家
n, 情人节
a, 快乐
"""
cut和lcut的区别除了返回的结果不一样以外,还有一个重要的区别是cut的速度要略快于lcut,大家可以把时间打出来看一看,时间问题在大规模文本分词中很重要。
2. 关键词提取
顾名思义,关键词提取,就是把文档中的关键字提取出来,jieba中主要是靠jieba.analyse类里面的extract_tags来完成的。
import jieba
import jieba.posseg
import jieba.analyse
str1 = "今天是情人节,祝大家情人节快乐"
res = jieba.analyse.extract_tags(str1, topK=3)
print(res)
"""
['情人节', '快乐', '今天']
"""
3. 词典
jieba中的词典,主要是指停用词词典和自定义词典。停用词词典很好理解,就是把不希望jieba分词分出来的词放入到一个叫做停用词词典的文件中,就不会被jieba分词分出来,这个很好理解哈,不多说。
自定义词典是有些词无法被jieba分词分出来,但是你又希望这个词被分出来,那么就把这个词放在一个叫做 自定义词典的文件中,这样jieba就可以分出来这个词了,也很好理解哈。
然后主要说一下jieba中是怎么实现这个功能的
对于停用词,其实就是把jieba分词的结果中那些在停用词表的词去掉,剩下的就是我们想要的。这里可以把停用词表放在文件里面,然后用的时候读取出来,然后读到一个list里面就好了。
import jieba
import jieba.posseg
import jieba.analyse
stopwords = ['是', '祝', ',']
str1 = "今天是情人节,祝大家情人节快乐"
str1cut = jieba.lcut(str1)
results = []
for x in str1cut:
if x not in stopwords:
results.append(x)
print(results)
"""
['今天', '情人节', '大家', '情人节', '快乐']
"""
jieba中还有一种设置停用词的方法, 这个是用在关键字提取的时候,所以如果你不是用的analyse这个类的时候,set_stop_words是不起作用的。
import jieba
import jieba.posseg
import jieba.analyse
jieba.analyse.set_stop_words("./dictionary/stopwords_zh.csv")
str1 = "今天是情人节,祝大家情人节快乐"
str1cut = jieba.analyse.extract_tags(str1)
print(str1cut)
"""
['情人节', '快乐']
"""
然后是自定义字典,直接调用load_userdict, 把字典的路径放进去就ok了。
import jieba
import jieba.posseg
import jieba.analyse
jieba.load_userdict("./dictionary/jieba_dict.csv")
jieba.analyse.set_stop_words("./dictionary/stopwords_zh.csv")
str1 = "今天是情人节,祝大家情人节快乐"
str1cut = jieba.lcut(str1)
print(str1cut)
"""
['今天', '是', '情人节', ',', '祝', '大家', '情人节', '快乐']
"""
4. 词云
词云和jieba的关系不是很大,之所以要把这个放在这里讲一下,是因为答应我的女朋友,分析一下我们过去微信里的聊天记录,做一个词云展示出来,作为情人节的礼物(⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄),But,我的手机死活root不了,我试了很多软件都不行,也是醉了。截止目前,我还没有把我们的聊天记录提取出来,所以也没法做后续的分析,这里求助一下各位大大,有谁知道怎么root三星的A9,可以来教一下我。
Python里面做词云的是wordcloud包,用起来非常方便。做词云的一个好处是可以展示给别人看,当然自己看的话,统计一下词频就可以了,词云就是根据文档中词的频率不同,展示出来的字体大小,颜色不同,给人一种直观的感觉。
下面直接上代码
from scipy.misc import imread
import matplotlib.pyplot as plt
import wordcloud
def plot_word_cloud():
text = open("test_file.txt", 'r').read()
alice_coloring = imread("back.png")
wc = wordcloud.WordCloud(background_color="white",
mask=alice_coloring,
max_font_size=20,
random_state=1,
max_words=100,
font_path='msyh.ttf')
wc.generate(text)
image_colors = wordcloud.ImageColorGenerator(alice_coloring)
plt.axis("off")
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.figure()
plt.axis("off")
wc.to_file("wordcloud.png")
plot_word_cloud()
做词云需要注意的地方是,1.读取的文本是分词时候的文件,而且必须以字符串或者二进制形式输入。否则会报错TypeError: expected string or bytes-like object。2. 中文字体,msyh.ttf文件是用来显示中文字体的文件,如果没有这个文件,中文会乱码。这个文件随手百度一下就有,然后把路径写对了就可以。3.背景图,alice_coloring,这个可以设置也可以不设置。
下面是我随手百度的一个效果图,让大家体会一下。

5. 一点心得
结巴分词固然好用,但是对于专业领域的文本,很多词是切不出来的,或者是一些专有名词,地名,人名,机构名等,还有最重要的一类是对你后面模型的建立起作用的词,在别的地方可能是没用的,但是对你是有用的词,这时候就比较难办,所以专业领域的词典构建是一件非常繁琐的事情,至今貌似也没有什么好的办法,只能遇到一个然后添加进去一个。我自己想了一个办法,就是把所有可能的词全切出来,然后根据频率去掉频率低的词,因为如果是一个需要被切出来的词,那么应该是经常出现的词,如果不是经常出现的词,那就很有可能不是一个词。另外就是在分词的时候,不管是cut还是lcut,返回的结果可能并不能令你满意,这时候,你可以把你需要切出来的词直接封装一个方法,写在切词的方法里面,然后取二者的并集作为最后的分词结果,这样可以提高准确率。下面我写了一个脚本来抛砖引玉。
import jieba
import jieba.posseg
import jieba.analyse
import re
def newcut(inputs):
if isinstance(inputs, str):
_msg_cut = jieba.lcut(inputs)
print("|".join(_msg_cut))
print("="*20)
# 这里可以用正则匹配出文本出现价格的词,
# 因为类似100元这样的词,jieba是分不出来的,
# 但是你不能把类似这样的词加到词典里面去吧,
# 否则词典会变的很大。
p = re.compile("[0-9]+?[元|块]").findall(inputs)
if p:
for price in p:
_msg_cut.append(price)
if len(_msg_cut) > 0:
return "|".join(_msg_cut)
else:
return inputs
else:
return inputs
inputs = "今天是情人节,娜娜给我发了52元的红包!"
print(newcut(inputs))
"""
今天|是|情人节|,|娜娜|给我发|了|52|元|的|红包|!
===========================================
今天|是|情人节|,|娜娜|给我发|了|52|元|的|红包|!|52元
"""
今天是情人节,这篇文章也是送给我女朋友礼物,虽然我还没有把我们的聊天记录导出来(手动捂脸),后面我打算手动来做了,听起来是个大工程啊...。娜娜,愿我们相亲相爱,余生一起走! 也祝天下有情人终成眷属~~