FedReID - 联邦学习在行人重识别上的首次深入实践

作者 | 庄伟铭
编辑 | 陈大鑫
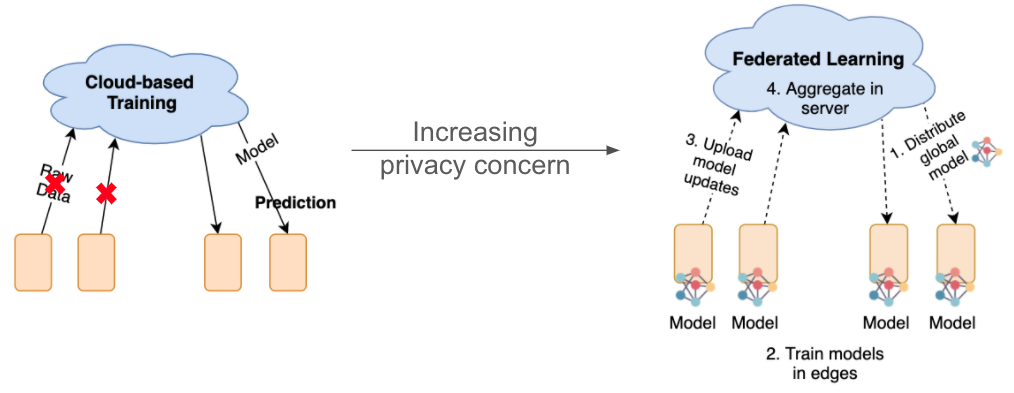
行人重识别的训练需要收集大量的人体数据到一个中心服务器上,这些数据包含了个人敏感信息,因此会造成隐私泄露问题。
联邦学习是一种保护隐私的分布式训练方法,可以应用到行人重识别上,以解决这个问题。
但是在现实场景中,将联邦学习应用到行人重识别上因为数据异构性,会导致精度下降和收敛的问题。
数据异构性:数据非独立分布 (non-IID) 和 各端数据量不同。
 本文介绍一篇来自 ACMMM20 Oral 的论文,
这篇论文主要通过构建一个 benchmark,并基于 benchmark 结果的深入分析,提出两个优化方法,提升现实场景下联邦学习在行人重识别上碰到的数据异构性问题。
本文介绍一篇来自 ACMMM20 Oral 的论文,
这篇论文主要通过构建一个 benchmark,并基于 benchmark 结果的深入分析,提出两个优化方法,提升现实场景下联邦学习在行人重识别上碰到的数据异构性问题。

-
Benchmark: 包括数据集、新的算法、场景等 -
Benchmark 的结果分析 -
优化方法:知识蒸馏、权重重分配
1
Benchmark
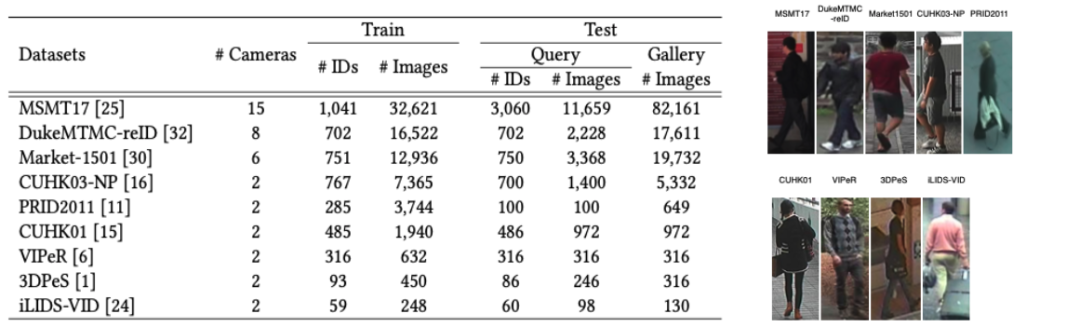
数据集
算法
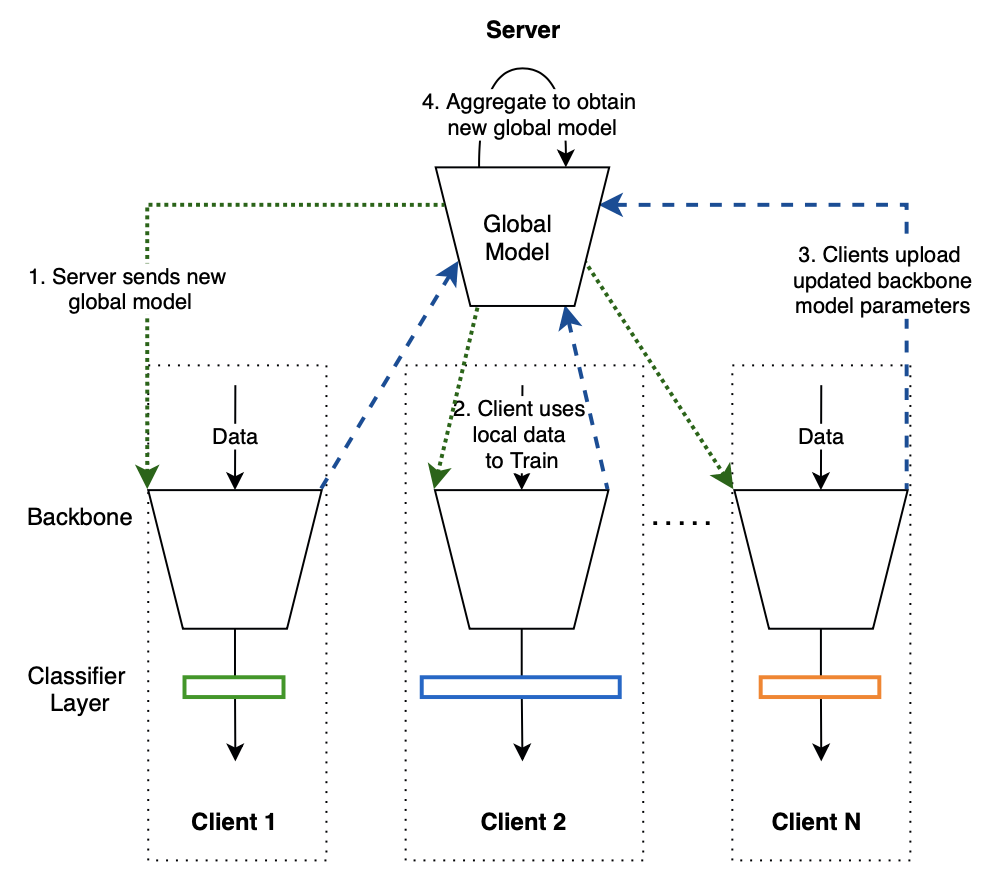
-
Server 下发一个全局模型到每个 Client -
每个 Client 收到全局模型后,将全局模型加上本地的分类器,用本地数据进行训练,每个 Client 得到一个 local model -
Client 将 local model 的 backbone 上传到 Server -
Server 对所有 client 收到的 model 进行加权平均。

2
Benchmark结果
1. 大数据集在联邦学习中的精度低于单个数据集训练的精度
![]()
FedPav: 联邦学习模型的精度
FedPav Local Model: 联邦学习各边端模型模型上传前在各自边端测试的精度
Local Training: 基准,每个数据集单独训练和测试的精度
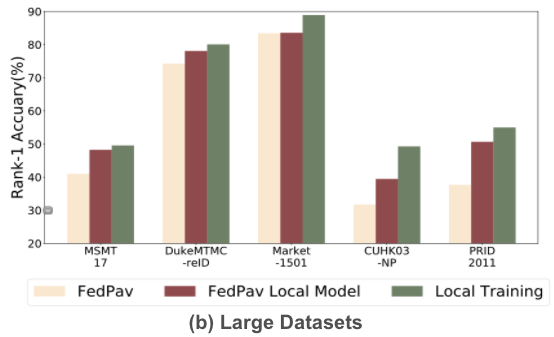
FedPav: 联邦学习模型的精度
FedPav Local Model: 联邦学习各边端模型模型上传前在各自边端测试的精度
Local Training: 基准,每个数据集单独训练和测试的精度
2. 联邦学习训练不收敛
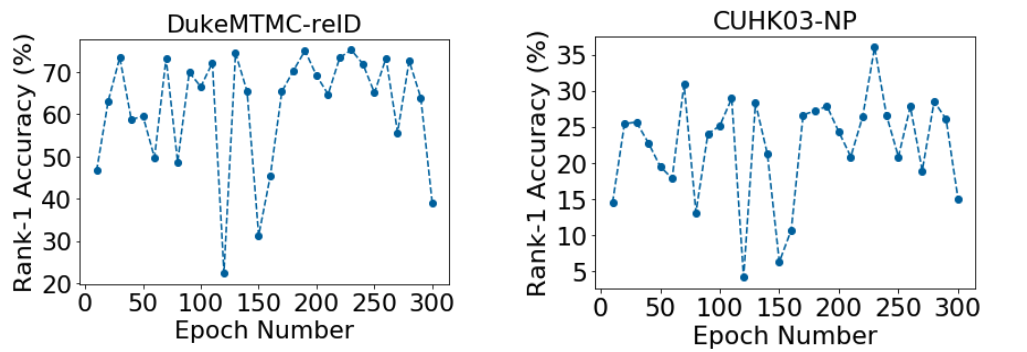
3
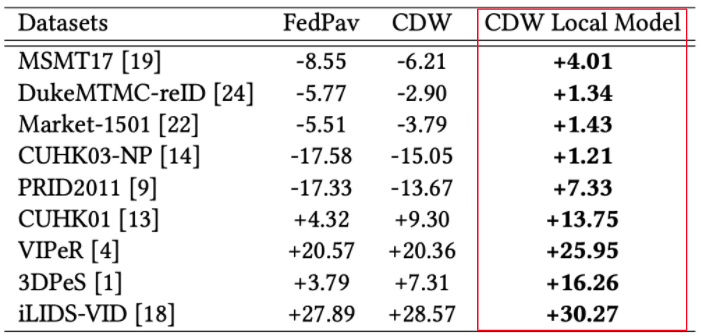
优化方法
采用知识蒸馏,提高收敛
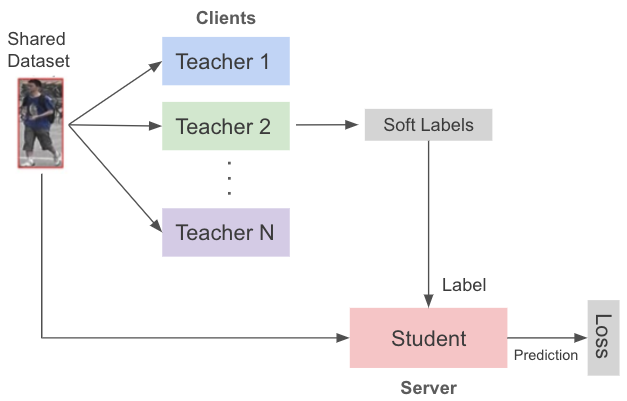

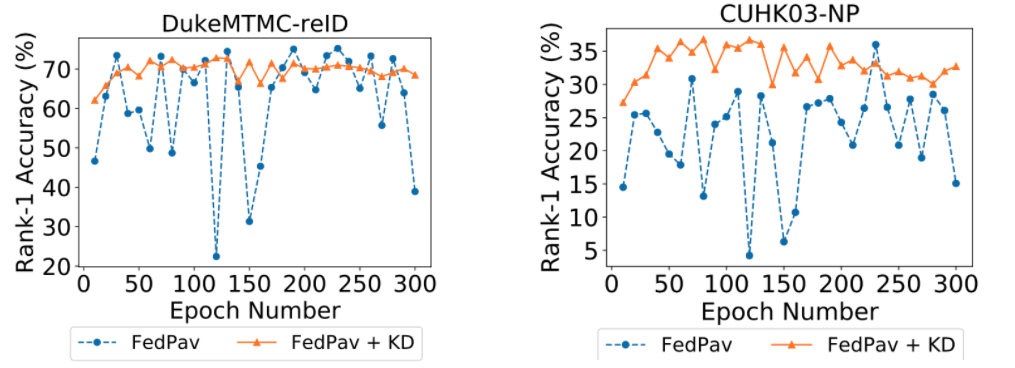
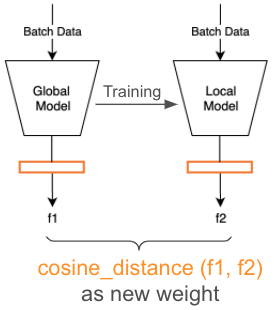

4
总结
在AI科技评论今天(10月19日)头条文章《专访吴军:未来10年,AI的发展方向是应用,不会出现重大的理论突破》一文留言区留言,谈一谈吴军博士对你的启示,或你对信息技术发展的理解。
AI 科技评论将会在留言区选出 10 名读者,每人送出《信息传》一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 10 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月19日 - 2020年10月23日(23:00),活动推送内仅允许中奖一次。
NeurIPS 2020论文接收列表已出,欢迎大家投稿让更多的人了解你们的工作~


点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容

Arxiv
0+阅读 · 2020年11月25日
Arxiv
12+阅读 · 2018年1月29日




相关VIP内容
相关资讯