IJCAI 2021 | 中科院计算所:自监督增强的知识蒸馏方法


知识蒸馏作为模型压缩里的一项重要技术,在学术界和工业界都得到了广泛的研究。
近日,AI Drive 邀请中科院计算所在读博士生杨传广,分享其在 IJCAI 2021 上发表的最新工作:自监督增强的知识蒸馏。

论文标题:
Hierarchical Self-supervised Augmented Knowledge Distillation
https://arxiv.org/abs/2107.13715


背景介绍:为什么要对模型进行知识蒸馏
今天分享的自监督增强知识蒸馏方法,是我们在 IJCAI 2021 中发表的用于通用图像分类任务的一种方法,该方法可以提升网络的性能。
首先介绍,为什么要对模型进行知识蒸馏。
第一,资源困境。深度学习模型,可以完成复杂的任务,但是往往具有庞大的参数量,计算开销和内存需求大的问题。因此,在计算能力受限平台上部署这些庞大的模型,通常是一个挑战,在不影响模型性能的前提下进行模型加速与压缩,也是一个研究热点。通常,我们使用的方法有参数剪枝、参数共享、模型量化、知识蒸馏等。文中我们重点研究知识蒸馏相关的模型压缩。
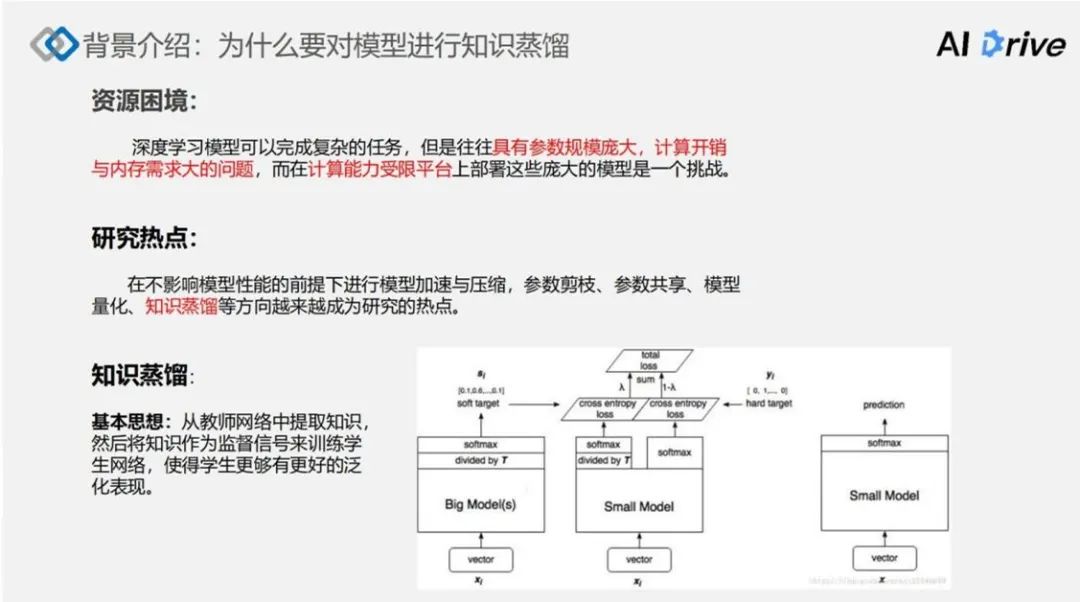
知识蒸馏的基本思想,是从教师网络中提取知识,然后将知识作为监督信号来训练学生网络,使得学生网络能够有更好的泛化能力。
上图展示了知识蒸馏的整体示意图,其中,Big Model 通常代表教师网络,而 Small Model 通常代表学生网络。知识蒸馏的核心思想,就是将这个教师网络所产生的信息作为监督信号,来训练学更小的学生模型,使得这个小模型能够在完成任务需求的情况下,复杂度要远远小于原有的教师模型。


上图重点介绍了知识蒸馏技术的发展脉络,以及一些代表性的相关工作。
现有的知识蒸馏主要分为两个层面的研究内容:
1. 怎样在教师网络中挖掘有益的知识来引导学生网络学习。
通常可以概括为三个层面:第一个层面是决策概率分布,response-based;第二个是特征信息,feature-based;第三个是高阶的跨样本相似度关系,relation-based。
2. 有了教师网络中的知识形式,以何种方式来迁移给学生?
第一种最常见的方式是采用 KL divergence 和 L2 误差的方式,分别对概率分布和特征图信息作为一种逼近手段;第二种是从模型的角度,在教师和学生之间引入一个中间模型。第三种,可以利用对抗生成的思想来依次进行知识迁移。
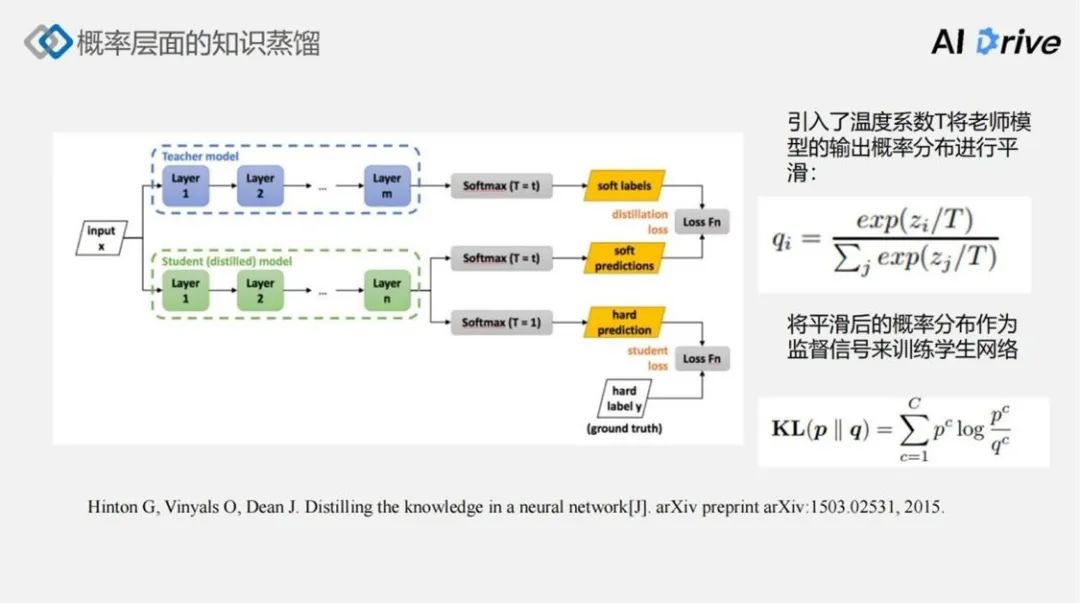
对于最传统的概率层面知识蒸馏方法,首先预训练一个 Teacher Model,输入 x 计算网络可以得到一个概率分布输出,这里称为 soft labels,同样的给定输入x学生网络也可以得到对应的概率分布信息,这里称为 soft predictions。
然后,将这两个概率分布经过一个温度T平滑,再进行一个 KL divergence 的逼近,使得这个学生网络的分布逼近教师网络产生的概率预测分布。
这种方法在直觉上是 work 的,因为教师网络具有更好的表现,通常是因为它具有更高质量的一个预测的概率分布,然后使得学生网络去逼近更高质量的概率分布,通常可以提升学生网络的泛化能力。
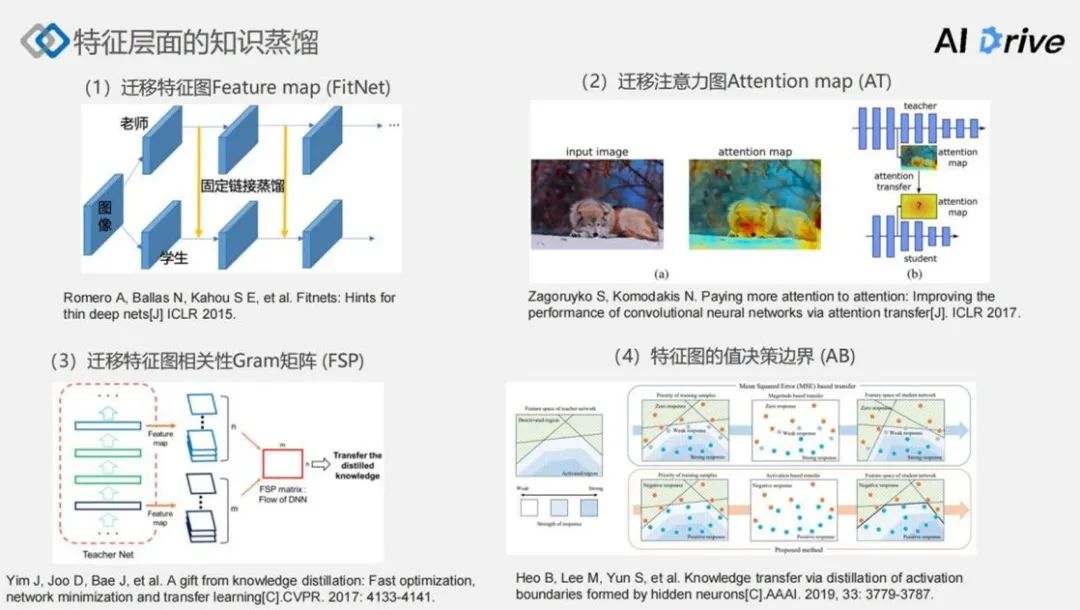
概率层面中,CNN 在做出推断的时候,通常会产生很多特征图,这些多层次特征图通常代表 CNN 对输入的学习过程,因此,传统的方法 Feature map 采用迁移特征图的方式,这种方式通常是采用 L2 误差的方式,对教师网络和学生网络之间不同阶段的特征图进行对应,使得学生网络在决策过程中能够逼近教师网络的决策过程。
同样,我们可以在特征图中凝练出更高更好的信息,最常见的可能就是注意力图(Attention map)。在这里,这个方法是给将给定的 Feature map,从参照维度通过聚合生成 Spatial Feature map,作为一种知识迁移的形式。
另一种比较经典的是 FSP 方法,该方法利用 CNN 不同阶段的特征图,求取相关度——Gram 矩阵,以它作为一种知识表达形式。
第三种比较经典的方法是,可以基于给定特征图中的决策边界。
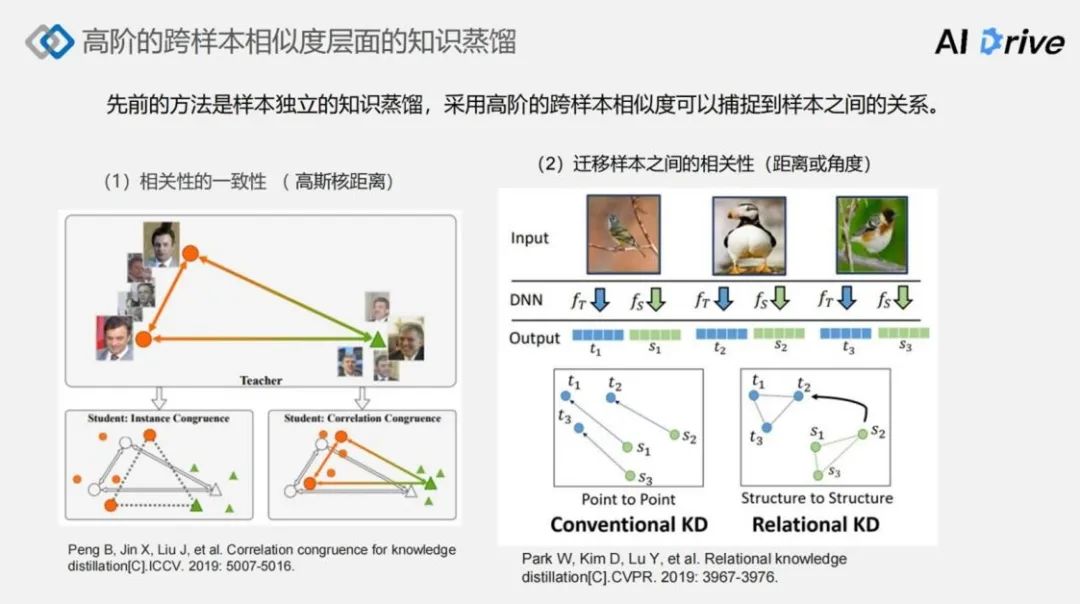
对于高阶的框架的相似度层面的知识蒸馏,代表性的工作有两个,一个是基于高斯和距离的相关性,称为 Correlation,该方法是将 Embedding 映射到一个高维的 Embedding 空间,然后在高维空间中作为相似度的求取。
第二种方法是 relationship 的 R KD,该方法是将这个网络不同样本所产生的 Embedding 求距离相关或者是余弦值角度相关的相似度关系,作为一种知识表达形式。
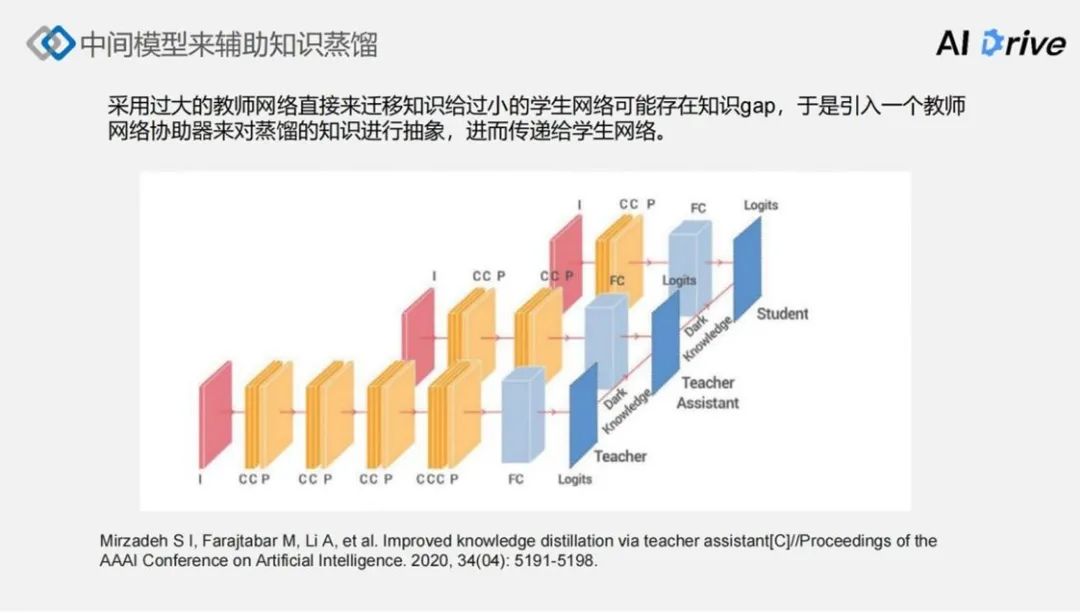
有了这个知识之后,怎样进行知识迁移?
有一种比较好的方法就是:基于一种观测,即采用过大的教师网络直接来迁移知识给过小的学生网络,可能会存在一种支持 gap,于是引入网络协助器来对蒸馏的知识进行抽象。这个网络协助器,通常是介于教师网络和学生网络之间规模的模型,然后该模型可以对教师知识进行一定程度的抽象,再传递给学生网络。
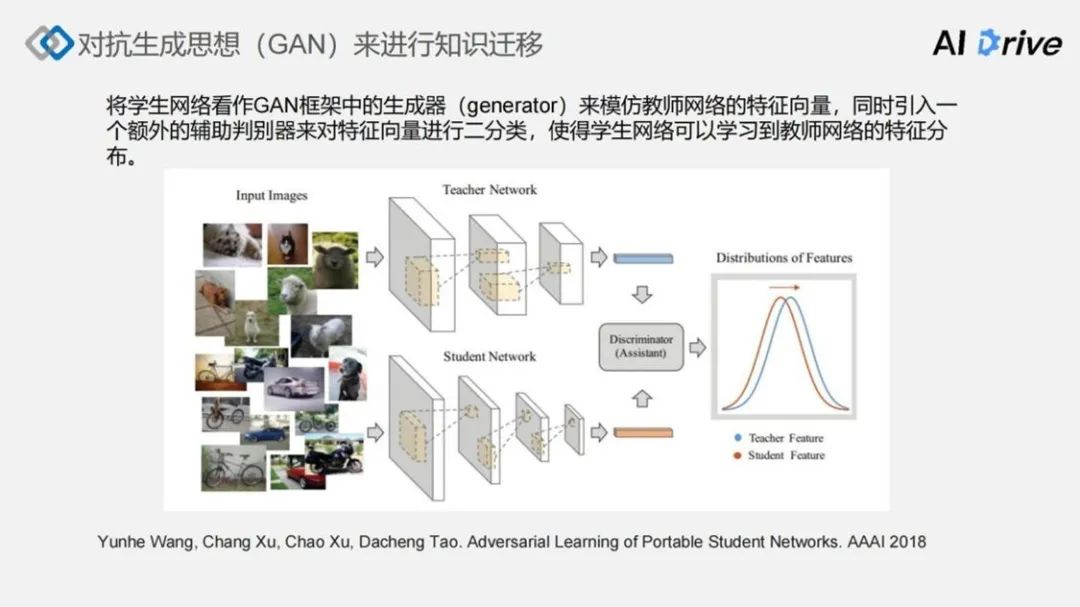
另一个思想用对抗生成(GAN)。可以将学生网络看成 GAN 框架中的生成器,来模仿教师网络的特征向量,同时需要引入一个额外的判别器,来对特征向量进行二分类,然后通过对抗生成的框架,可以使得学生网络学习到教师网络的概率分布——这就是特征分布。
下文是对自监督表示学习引导的知识蒸馏的介绍。


自监督学习的主要思想,是利用人工构造的伪标签和数据增强,使得网络学习更加泛化性的特征表示。
现有的自监督学习表示通常可以分为两大模式,第一个是基于分类的自监督学习,通常,是先提出一种基于分类的 pretext task,该任务通常施加在输入的图像上,例如比较经典的四种旋转角度,颜色通道打乱等等,可以引导网络去正确预测其中施加的是哪种数据增强,从而使得网络学到更好的特征表示。
自监督学习特征表示,通常可以用于到下游的一些语义识别任务,比如图像分类和目标检测。
第二个层面是基于对比学习的自监督学习,该种方法近年来比较流行,通常的思想是对输入一张图像增加不同的数据增强,然后使用对比误差来逼近一张图像的不同视角。
在这里,一张图像的不同视角通常认为是正样本,然后其他图像所产生的 Embedding 特征向量是负样本。
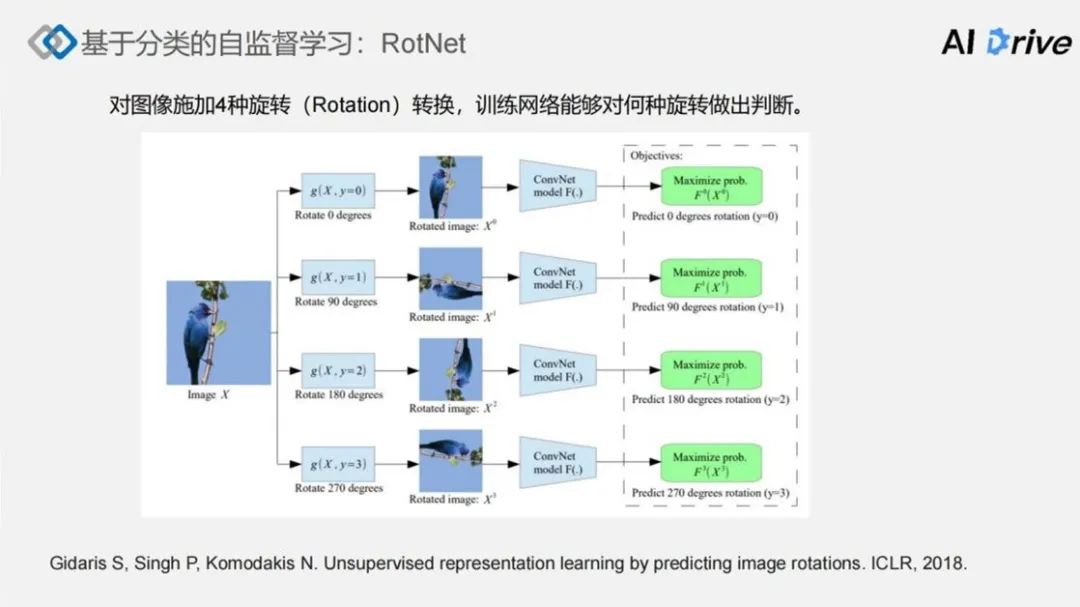
第一个基于分类的自监督学习模式的代表工作 RotNet。该方法是对输入的 Image X,施加四种转换,分别是零度(零度代表对图像没有变化)、90 度、180 度、270 度,最后进一步训练网络对输入的图像做何种旋转做出判断。
例如上图由于是 4 种旋转角度,相当于是一个自监督的自分类问题。对一个图像旋转 90 度,然后要求卷积神经网络能在 4 种角度中,正确判断出旋转的是 90 度,最后分类的 loss 也是基于传统的交叉分类 loss。
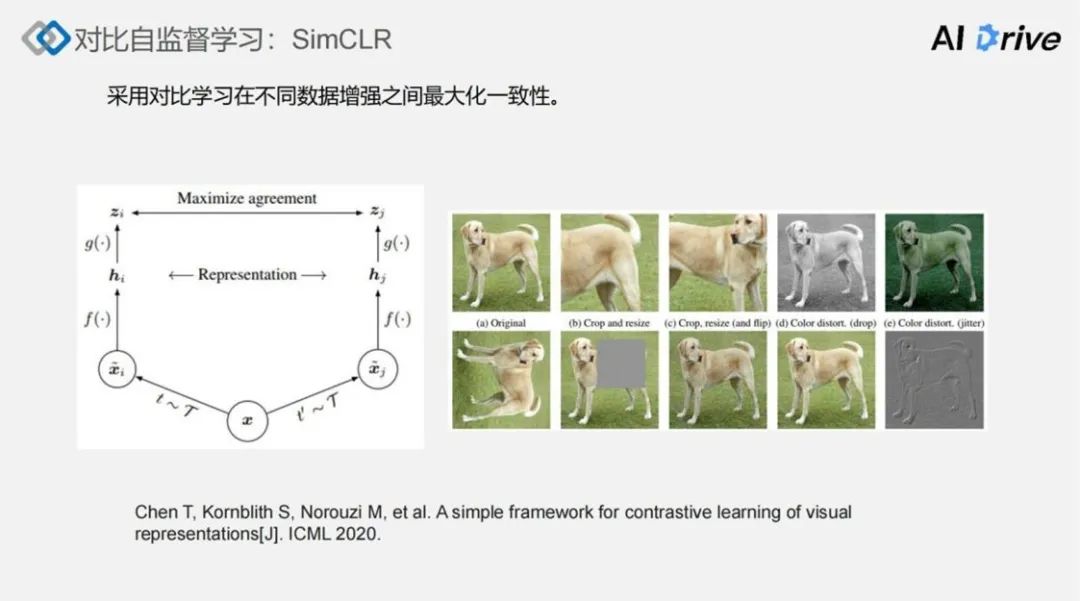
第二比较有代表性的对比自监督学习工作,是 SimCLR。该工作的核心思想就是采用对比学习,在不同的数据增强之间最大化一致性。有关论文中研究了很多种不同的数据增强,上图左边部分展示的,便是 SimCLR 的整体过程:针对这个输入 x,通常可以随机采样两种不同的数据增强,然后在这里施加了两种不同数据增强之后,分别得到了 xi 和 xj 增强之后的数据,并认为这是正样本。
对于这两种增强之后的数据,我们输入到同一个卷积神经网络f中,可以得到对应的特征表示分别为 xi 和 xj。然后经过一个特征向量转换之后,得到表示 zi 和 zj,最后最大化 zi 和 zj 的一致性,同时将其他的图像作为负样本,做一个对比学习。
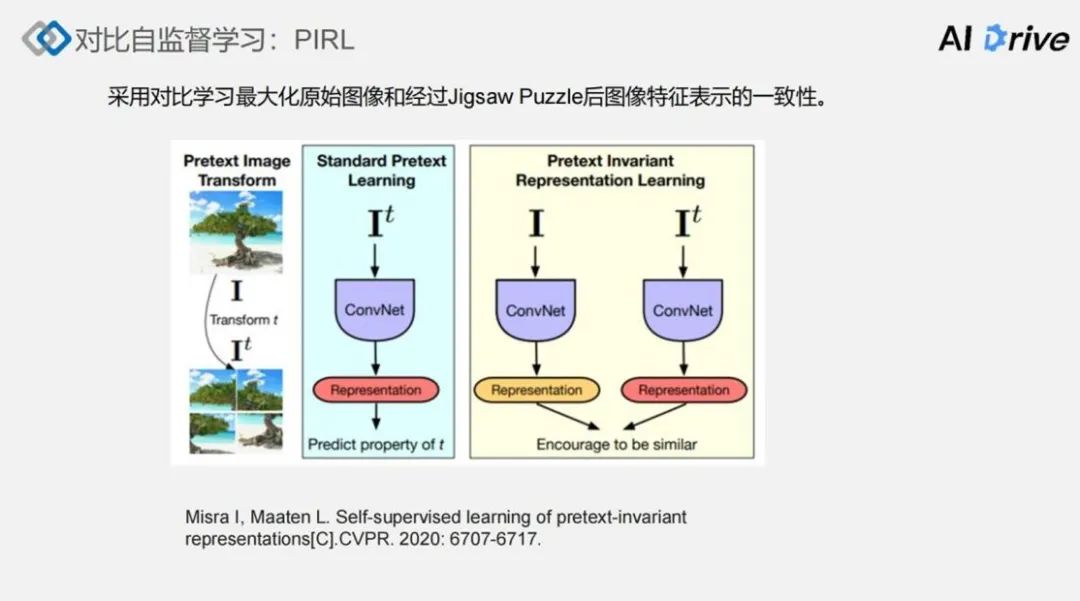
另一个比较有代表性的对比自监督学习工作是 PIRL,其对比学习的框架跟 SimCLR 是一致的,它的主要思想也是对一张图像施加转换,将一个图像的不同转换的视角作为正样本,其他图像作为负样本,文中引入了一个 Jigsaw Puzzle 转换。
如上图左边部分,给定一个输入图像 I 施加一个 Transform t,然后得到一 个It,即拼图之后的一个图像。标准的自监督学习,判断出给定的这个 It,并判断出这个拼图是基于怎样的顺序,而这里采用的也是鼓励一致性的做法,针对卷积神经网络,输入的两个视角是原始的图像I和转换之后的图像It,然后分别得到它的表示之后,采用对比学习来鼓励一致性,从而进行自监督学习。
先前的自监督学习的场景,主要是用在没有标签的情况下。一种可行的思想是,利用自监督学习来进一步增强有监督学习的性能。
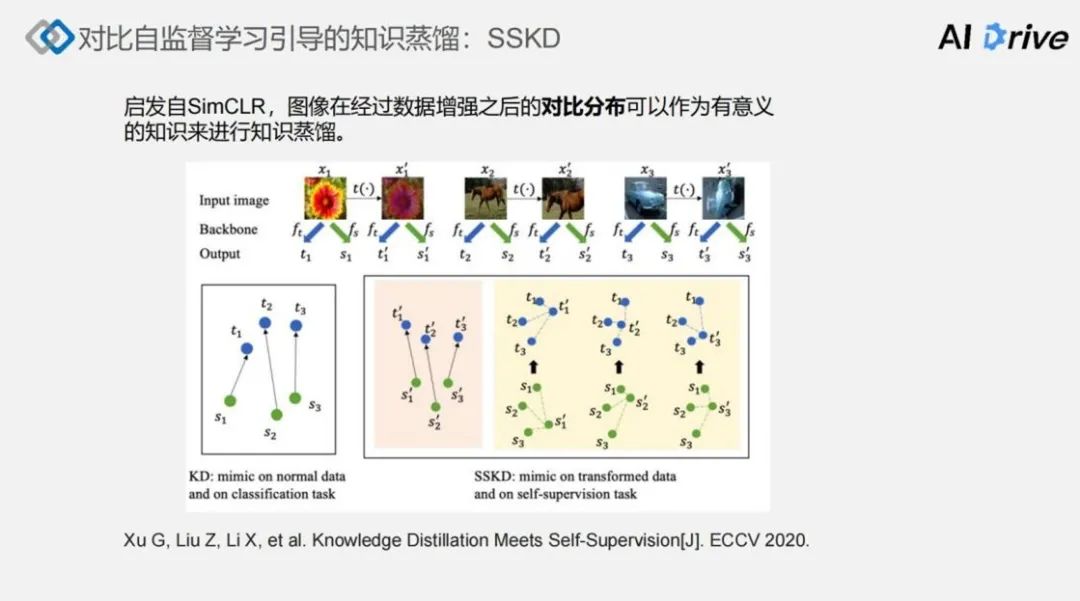
SSKD 是一种将自监督知识引入有监督知识蒸馏的方法。SSKD 启发自 SimCLR,它将图像在经过数据增强之后的对比分布,可以作为有意义的知识形式来进行知识迁移。
上图就说明了这个知识定义过程,这个过程实际上就是 SimCLR 的过程,针对一个图像做数据增强之后,尽量去逼近原始图像和转换之后图像的关系,然后进一步远离其他图像之间的关系。
由这个关系做一个对比分布,可以由教师网络迁移给学生网络,在具体实现层面上的话,是在 Teacher Backbone 和 Student Bone 上分别加一个自监督的模块,文中的自监督模块,实际上是一个特征向量的转换模块,这个特征向量的转换模块是由两个全连接层中间加一个非线性的 ReLU 函数来构成的,目的是将 Backbone 所产生的特征向量做一定程度的转换,转换之后的特征向量可以用于进行学习。

实现方法和实验结果
既然自监督和有监督都能使得网络学习到更好的特征表示,那么一个很好的研究方向,就是去考虑用自监督任务来增强有监督任务的特征学习。
在这里,考虑联合两种方式进行有效的特征表示学习。
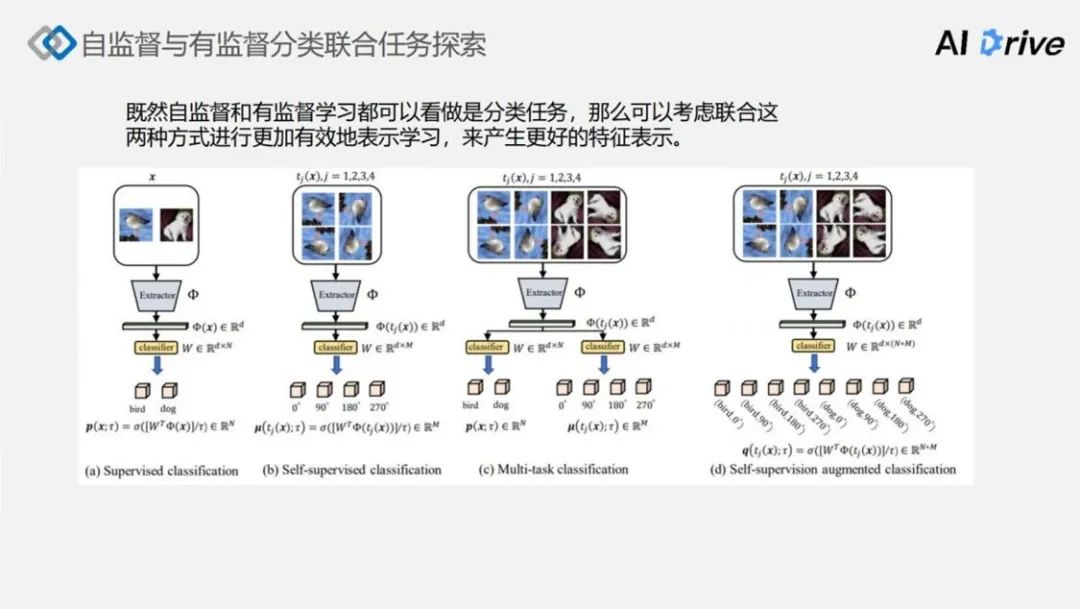
上图中,首先(a)图是传统的有监督分类,有监督分类就是针对一张图像,判断这个图像中目标是哪一个类。(b)图展示的是自监督的分类示意图,针对一张图像做了不同的旋转之后,通过分类器,判断做的是哪种旋转。
(c)是联合有监督和自监督的一种学习方式,在这里它们两者采用了共享的特征提取器,在分类尾部是采用了不同的分类头,左侧是一个有监督的分类头,用来分类不同的目标,右侧是一个自监督的分类头,用来分类这个目标的旋转角度,这两个分类任务是同时进行、学习共享的特征提取器。
(d)是将这个自监督和有监督的 label 空间进行一定程度的融合,变成一个全连接的空间。举例子的话是比如说有监督的分类任务是两个目标,而自监督的角度分类是 4 个 label,通过融合这两个 label 可以得到一个 2 * 4 的 8 个 label 空间,通过两个 label 空间做一个笛卡尔积的方式。这里只需要用一个分类头就可以达到,但是这种方法的缺点就是可能会增大类别空间的类别个数。但是当增大类别个数之后,也会意味着会显著的编码更多的有监督和自监督的这种联合信息。
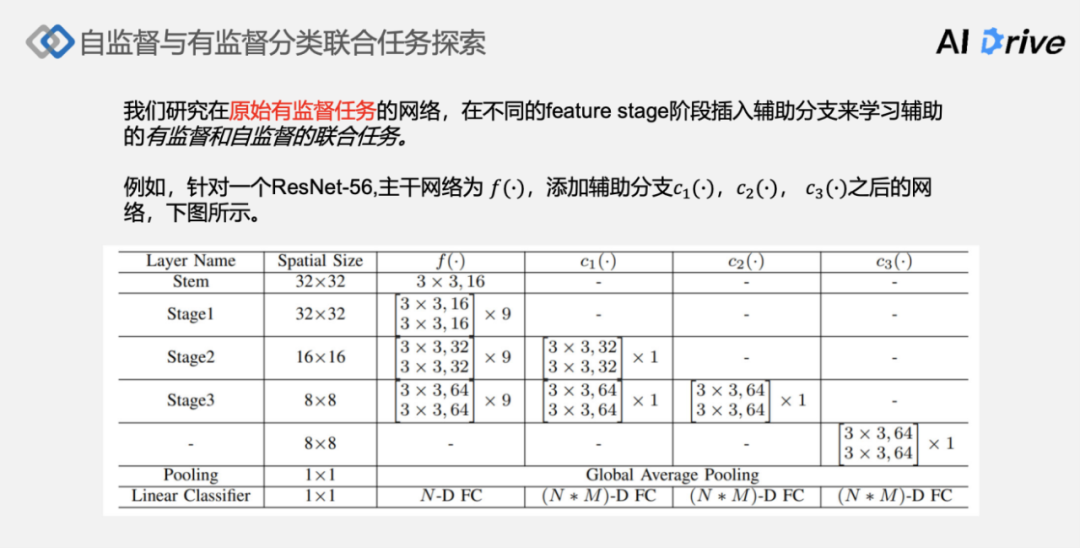
在研究原始有监督任务的网络时,不同的 Feature Stage 阶段插入辅助分支来学习辅助的有监督和自监督的联合任务,需要对网络结构进行了一定的改进。
例如,针对一个 ResNet-56 为例,将主干网络表达为f(·),并且添加辅助分支C1(·),C2(·),C3(·),主干网络还是学习原始的有监督的分类任务,辅助分支学习提出的一些有监督结合的一些任务,从而研究无监督任务对有监督任务的一个表现的增益。
不同网络结构上使用自监督辅助任务来做辅助训练,对最终有监督分类任务的影响如下表所示:
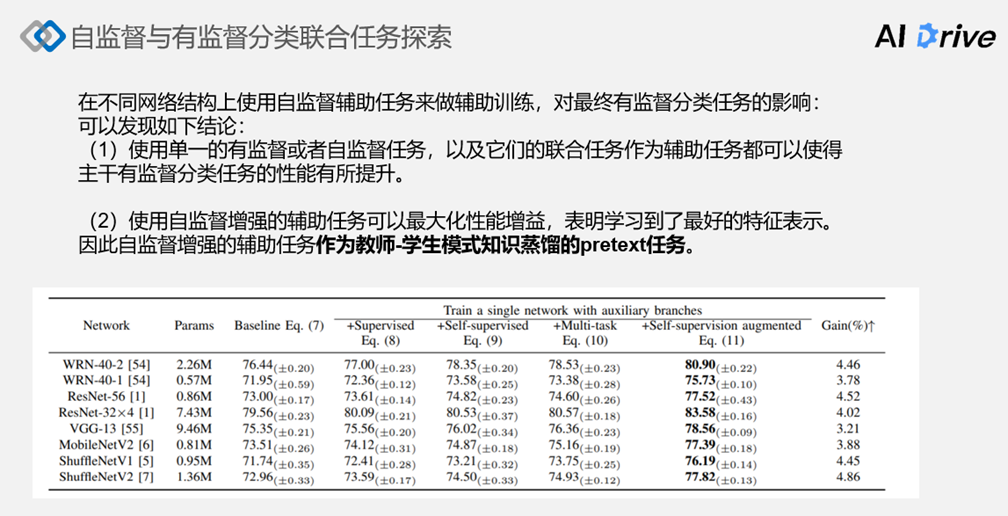
在不同网络结构上做了一系列的实验,发现了如下结论:
(1)使用单一有监督或者自监督任务作为训练辅助分类器的一些任务以及它们联合的任务作为辅助任务,都可以使得主干的有监督分类任务的性能有所提升。
(2)采用和主干网络相同的有监督分类任务,性能提升可能是最小的,可能是因为添加的辅助任务和原有的主干任务是高度同质化的,因此训练辅助结构并没有引入额外的一些信息和知识,采用纯自监督的任务作为训练辅助分类器的任务的话,性能增益是要比使用和主干网络相同的有监督任务要大,表明自监督任务的确是有能有效提升主干有监督任务的性能。
(3)由于自监督和原始的有监督可能是两种不太相同的任务,自监督也为有监督引入一些额外的表示学习的知识。此外,发现采用一种多任务方式,多任务就是上文提到了采用两个分类头的形式,分别学习有监督和自监督的方式,跟原始的自监督之前用自监督的方式性能增益相当。
但是将两个 label 空间联合起来,即有监督和次监督这两个 label 空间采用笛卡尔积的形式变成一个联合 label 空间,这种 label 空间作为一个辅助的训练任务,可以使得网络主干的有监督分类就能得到最大程度的提升,表明学习到了最好的特征表示,因此也启发采用一种这种联合的形式作为辅助任务,作为教师学生模型之中的一种 pretext 任务。
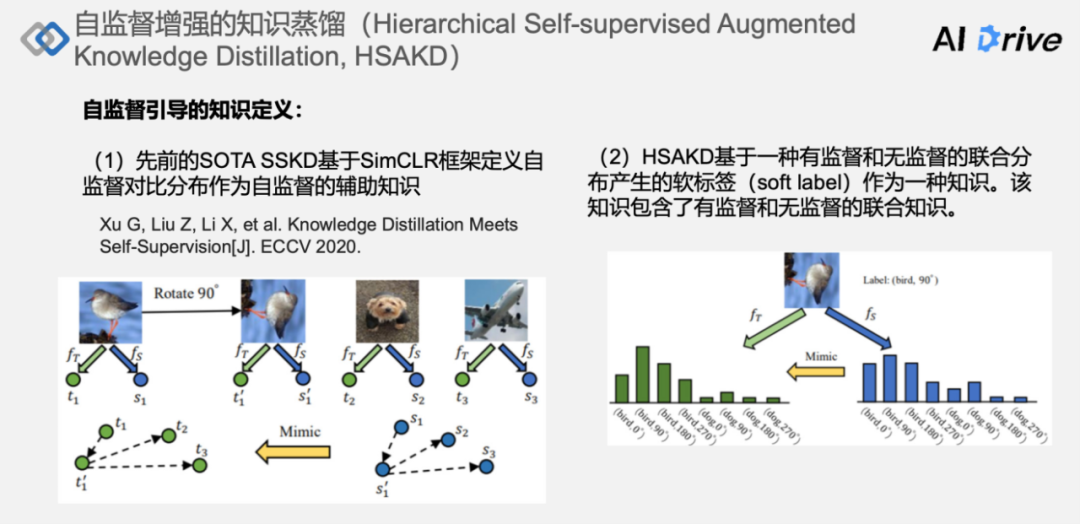
在此简单回顾一下自监督蒸馏知识的定义:
(1)先前最好的方法 SSKD 是基于 SimCLR 框架定义的一种自监督对比分布作为自监督的辅助知识。这里把之前的示意图做了简化:假如说这个鸟旋转 90 度得到一个 Transform 的图像,然后将这两个图像在这个特征空间中逼近,同时远离这个狗和飞机所产生的特征向量,这个是一个对比分布。
(2)采用了基于一种有监督和无监督的一种联合分布,产生的软标签作为一种知识,该知识包含了有监督和无监督的联合知识,然后对附加的辅助分类器来学习这些辅助的任务,来迁移有监督增强的一种联合概率分布。
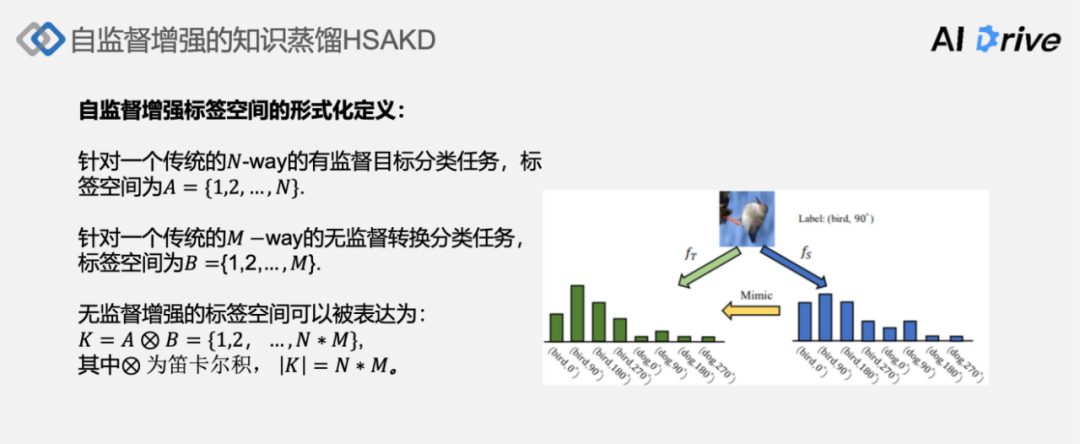
简单形式化介绍一下自监督增强的标签空间分布。针对一个传统的 N 维的目标分类任务,它的 label 空间为 1~N。针对一个传统的 M 维的无监督转换分类任务,label 空间通常是 1~M。然后无监督增强的标签空间,就可以表达为 label 空间 A 和 label 空间B的一个笛卡尔积的形式,然后新的增强的空间的大小就是 M*N。
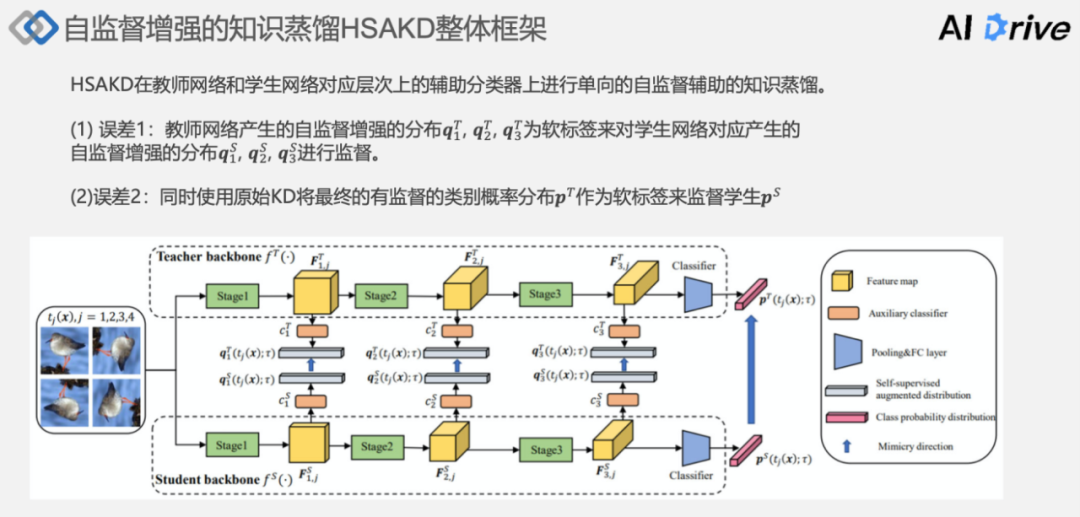
上图展示了自监督增强知识蒸馏框架:HSAKD 的整体的流程。
HSAKD 在教师网络和学生网络对应层次上的辅助分类器,进行一个单向的自监督辅助的知识蒸馏。
误差来源有两个:
(1)误差 1:教师网络产生的自监督增强的分布,q1 到 q3 作为软标签来对学生网络对应层次所产生的自监督增强的分布 q1 到 q3 进行监督;
(2)误差 2:最终分类器层面的一个概率概率蒸馏。使用原始的 KD,将最终的有监督的类别概率分布 PT 作为软标签来监督学生 PS ,这是两个蒸馏误差的来源。

具体的实验方法是由于基于教师学生模式的框架,通常需要预训练一个教师网络,将教师结构表达为主干网络 fT(·) 和 L 个辅助分类器。
(1)给定原始的数据 x,训练主干网络 fT(·) 通过传统的交叉熵来拟合真实的标签y;
(2)给定旋转增强的数据 tj(x),其中 tj 为第 j 的旋转角度,训练 L 个辅助分类器,通过交叉熵函数来学习自监督增强的 label,这个 K 表示为 KL,然后这两个 loss 都是基于交叉熵的分类 loss,整体的误差是将这两个交叉熵 loss 相加。同时对主干网络和添加的辅助分支做了一个联合的训练。
这里 PT 是指原始的 N 维有监督分类任务上预测概率分布,qT 的话就是为 N*M 维的一个自监督增强的分布,预训练教师网络之后,可以用教师网络进一步指导训练学生网络。


将学生结构表达为主干网络 fS(·),L 个辅助分类器 CS。
(1)对 fS(·) 拟合原始的数据 x,然后通过给定原始的数据 x 来拟合真实的标签y,这里采用了一种传统的交叉熵 loss。在这里 ps 的指原始的有监督分类任务上的一个概率分布。除了基础任务 Loss,还有教师网络对学生网络的指导。
(2)给定旋转增强的数据 tj(x)之后,其中 tj 为第 j 的旋转角度,训练L个辅助分类器来学习来自教师网络产生的自监督增强的软标签 qT,启发自原始的 KD 过程就可以用 KL 散度来实现。通过 KL 散度,可以使得学生网络产生的监督增强的分布。去拟合教师网络所产生的分布。在这个公式中,qs 是学生网络产生的自监督增强的分布,KL 散度中中,取温度 T=3。
(3)除了自监督增强的一个分布蒸馏,进一步可以考虑最终的有监督的类别概率分布作为前一个知识。由于对输入端图像进行了旋转增强,得到了转换之后的图像 tj(x),于是可以迁移这些增强数据的概率分布。这里采用了一种 KL 散度的方式来使得学生网络去逼近教师网络产生的概率分布。PT 和 PS 就是分别是有监督分类任务上的概率分布,都是 N 维的。这里同样取温度等 3。
整体的误差就是将上述误差(1)(2)(3)相加得到最终的误差。由于误差来源都是基于概率的熵误差,所以并没有引入误差平衡因子,在实验中效果表现已经足够好。
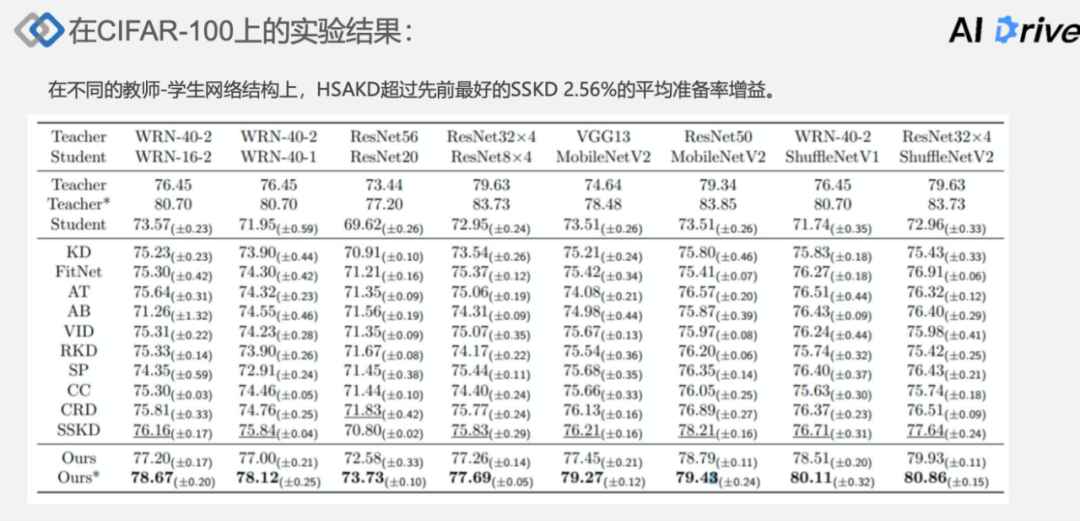
首先在标准的 CIFAR-100 数据集上做了一个实验对比,主要对比的是先前流行的自蒸馏方法,在不同的教师学生网络结构上, HSAKD 能一致的超过先前的方法,先前最好的方法是自监督相关的 SSKD,HSAKD 方法在不同网络结构上超过了 SSKD 2.56% 的平均准确率增益。
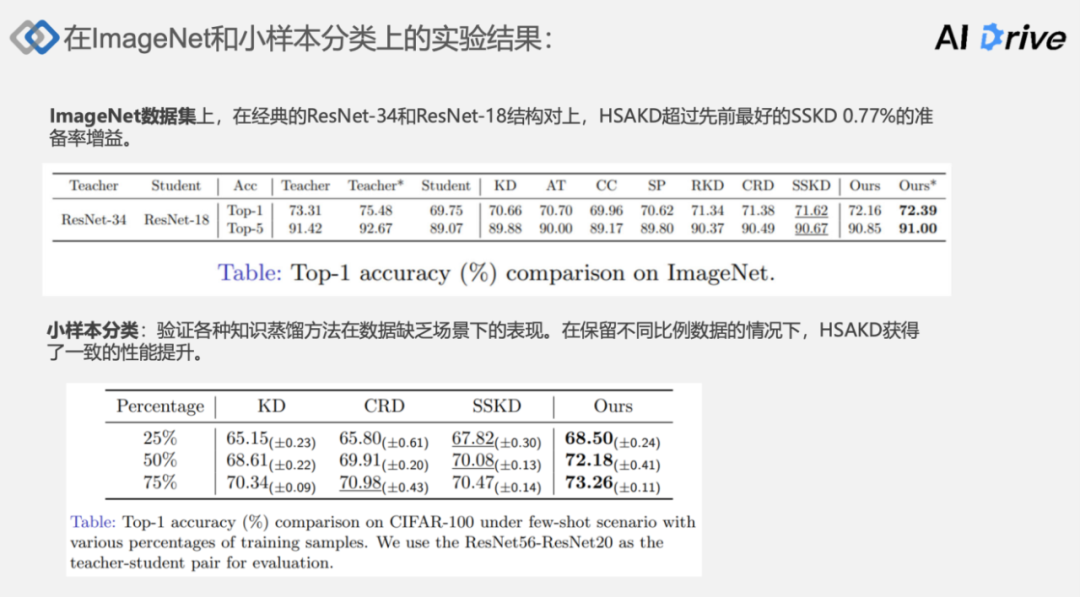
进一步的在 ImageNet 和小样本分类任务上进行了实验,得到以下结论:
(1)在ImageNet 数据上,在经典的 ResNet-34 和 ResNet-18 结构对上,HSAKD 超过先前最好的 SSKD 0.77% 的准确率增益。
(2)在小样本分类:验证各种知识蒸馏方法在数据缺乏场景下的表现。在保留不同比例数据的情况下,HSAKD 获得了一致的性能提升。表明 HSAKD 在缺乏数据的情况下,依旧能表现出良好的性能。在仅保留训练集 25% 的情况下,在 ResNet20 依旧能够达到 68.5% 的准确率,相当于跟原始的 baseline 效果是近似一致。
(2)进一步做了一个迁移学习的实验,通常在上游的图像分类数据集之后,可以将训练好的模型作为一个迁移学习的任务。在 ImageNet 数据集上训练的 ResNet-18 迁移到下游的目标检测任务上。在 ImageNet 上训练的其他的蒸馏方法做一个比较,训练的 ResNet-18 能在下游的 VOC 上获得了 78.45 的 mAP,比先前的 KD 超过了 0.85 的 mAP 增益。
(4)将 CIFAR-100 训练好的模型,固定特征提取器部分,只训练新添加的分类器,来完成下游的 STL-10 和 TinyImageNet 分类任务。结果显示,相比于先前最好的 HSAKD 性能增益依旧很大。
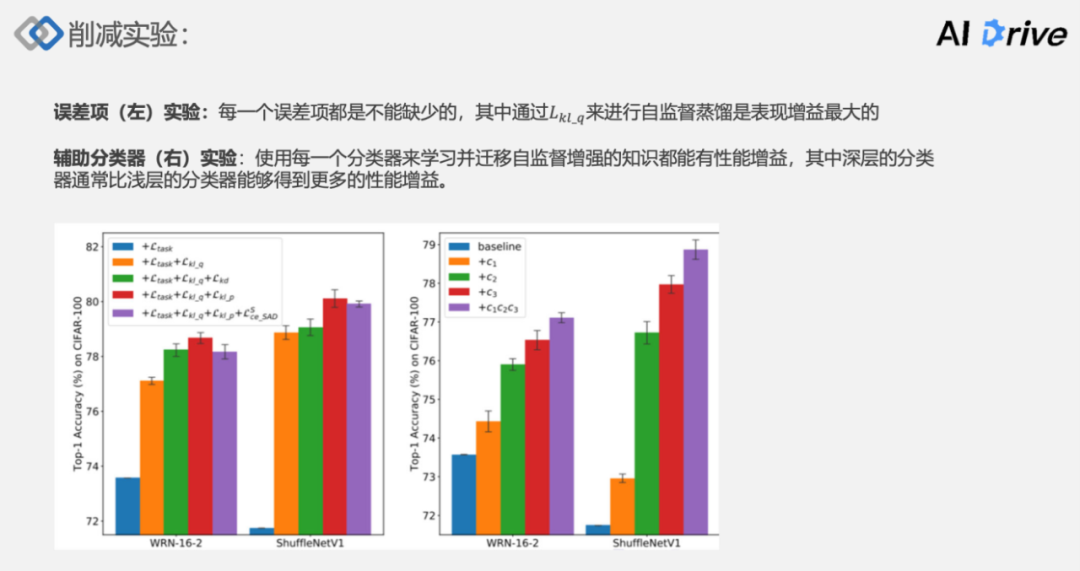
消融实验部分,首先是对一个误差项做一个消融实验:
(1)上图左面基于一个累逐渐累积的方式来做。结果显示,每一个误差项都对性能有提升的,其中通过 kl_q 来进行自监督的蒸馏表现增益是最大的。
(2)上图右边是一个基于辅助分类器的消融实验,可以发现就是说从左到右一次使用了单独分析了 c1、c2、c3,使用每一个分类器来学习并迁移自监督增强的知识都能有性能增益,其中深层的分类器通常比浅层的分类器能够得到更多的性能增益。原因是深层的分类器所接受的特征通常是比较高阶段特征,这些特征通常是具有高阶的语义信息,一般图像分类的话,使用这部分特征所产生的信息一般是更加具有泛化能力的。
最后聚合所有的分类器来进行自蒸馏,能够最大化增益。

总结与展望
总结包含三个方面:
1. 知识定义:引导了一个分类网络上的辅助结构来产生自监督增强的概率分布,该分布包含了原始有监督的分类任务和无监督任务的联合知识;
2. 知识迁移:利用中间的辅助分类器来进行一对一概率化知识的传递。使用高度抽象化的概率知识同样缓解了在特征匹配时语义层次不一致的问题;
3. 实验结果:HSAKD 显著地超过了先前基于自监督知识蒸馏方法 SSKD。同时利用自监督表示学习来进行 知识蒸馏通常也能使得网络学习到更容易泛化的特征表示,有利于下游的语义识别的任务。
随着自监督表示学习的发展,不同模式的算法被提出,本质上还是能够使得模型学习到泛化能力更好特征表示。直觉上讲,算法越好,其对应的知识表达形式在知识蒸馏领域就越可以 work。
所以,结合自监督的表示学习来进行有监督的知识蒸馏,目前仍然是一个具有前景的研究方向。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读



#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


