赛尔推荐 | 第7期
该栏目每周将推荐若干篇由师生精心挑选的前沿论文,分周三、周五两次推送。
本次推荐了最新发布的NAACL 2018 Outstanding Paper中关于词向量和RNN计算复杂性的两篇论文以及两篇关于事件检测、推敲网络、编码器-解码器和序列生成的其他顶会论文。
1
推荐组:LA
推荐人:刘一佳(研究方向:句法分析,语义分析)
论文题目:Deep contextualized word representations
作者:Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
出处:NAACL 2018 Outstanding Paper
论文主要相关:词向量
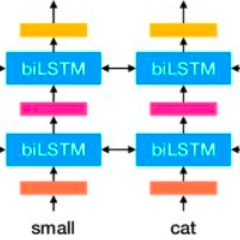
简评:词向量(Word embedding)已经成为神经网络时代NLP任务的基石。然而,众所周知,随着上下文环境不同,词的句法语义功能会发生明显变化。采用与Word2vec类似的方式给每个词以固定的向量表示似乎不是最佳实践。直观上更好的表示方式是:将词进行向量化的模块接受一个词以及他的上下文,输出对应考虑上下文(contextualized)的词向量。这篇文章关注的就是如何构建这样一个模块。文章提出了一种考虑上下文建模词向量的模型--ELMo。ELMo采用双层双向LSTM建模这种考虑上下文的词向量。它接受输入句子并将LSTM的在每个词上的各层隐层输出作为对应词向量。ELMo的训练过程与一般语言模型相似,在使用时需要对各层输出进行加权。更多细节请参考原文论文。
ELMo虽然看起来很简单,非常有效。但在本文6项句法语义实验中,使用ELMo显著提高了强基线模型的性能,取得了相对值5%到25%的提升。除了ELMo模型方面的贡献,本文也详细分析了ELMo的获得的词向量。比较有趣的结论是:ELMo的第一层输出包含更多的句法信息,而第二层输出包含更多语义信息。具体论证方法也请参考原文。
在刚刚公布的NAACL 2018 Outstanding Paper的评选中,这篇研究上下文相关词向量的工作脱颖而出,获得了Outstanding Paper。推荐者认为,这篇文章获得好评的原因在于:1. 简单有效的方法;2. 扎实的实验结果;3. 有趣的分析。
末了,推荐者想将ELMo与多任务学习建立联系。ELMo可以视作是在单一任务的学习目标中加入一个额外的语言模型学习目标。事实证明,这种学习目标可以有效提高模型的泛化能力。更进一步,我们能不能使用跨任务数据(比如句法或者语义数据)或者跨语言数据(比如多语语言模型)作为这种额外目标。他们又会给传统单一任务学习带来怎样的变化呢,期待有后续工作从这个方向跟进。
论文链接:
https://arxiv.org/pdf/1802.05365.pdf
源代码链接:
http://allennlp.org/elmo
2
推荐组:LA、RC
推荐人:文灏洋(研究方向:任务型对话)、赵森栋(研究方向:文本挖掘)
论文题目:Recurrent Neural Networks as Weighted Language Recognizers
作者:Yining Chen, Sorcha Gilroy, Andreas Maletti, Jonathan May, Kevin Knight
出处:NAACL 2018 Outstanding Paper
论文主要相关:RNN、计算复杂性
简评:这篇讨论了以RNN为模型识别带权语言(Weighted Languages)的相关问题的计算复杂性。事实上,语言模型以及利用句子级极大似然进行训练的模型都可以看做这一类问题,所以这类问题的计算复杂性的讨论是十分有价值的。文章着重讨论了单层、以ReLU为激活函数的RNN。文章指出,给定一个RNN判断其是否具有识别带权语言的一致性是不可判定的。以语言模型为例,即基于RNN的语言模型是否为一个概率分布的问题是不可判定的。同时,文章利用停机问题规约并指出,给定一个RNN和阈值c,判断是否有字串s使得其通过RNN生成的权重大于c的问题也是不可判定的。但如果给定的RNN具有一致性,问题就是可判定的。而文章利用整数线性规划问题进行规约并指出,在多项式长度内找到一个串使具有一致性的RNN生成的权重大于某阈值的问题为NPC、APX-Hard问题。换句话说,这提供了在类似问题(如Seq2Seq问题的解码器)上使用贪心、Beam Search等近似算法的必要性的理论依据。文章最后还说明了,判断两个RNN是否等价、判断一个RNN是否存在神经元更少的RNN与其等价的问题都是不可判定的。同时,在这样简单的RNN结构上的复杂性可能预示着在复杂结构(如LSTM)上也存在着类似结论。在本文中作者为你准备了大量的烧脑推导和证明。自认为在计算理论上功力深厚的你抓紧去读论文吧。
论文链接:
https://arxiv.org/abs/1711.05408
3
推荐组:SP
推荐人:张文博(研究方向:社会预测)
论文题目:Event Detection via Gated Multilingual Attention Mechanism
作者:Jian Liu, Yubo Chen, Kang Liu, Jun Zhao
出处:AAAI 2018
论文主要相关:事件检测
简评:随着互联网信息爆炸式的增长,从非结构化的信息中提取出有用的结构化信息显得尤为迫切和重要。事件检测作为信息抽取系统中的一个关键任务,受到了很多研究者的关注,然而,以往大部分做事件检测的工作都只用到单语的信息,忽视了其它语言提供的丰富特征。该论文提出了一个基于Attention机制的事件检测框架(GMLATT),这个框架最大的创新点是通过聚合多语信息来消除触发词的歧义,同时多语信息的加入还弥补了数据匮乏的问题。例,Fired on the hotel和The staff were fired,同样是fired,对应的中文却分别是“开火”和“解雇”,整合中文信息后,使得触发词的特征信息更明显,进而有助于提高预测准确率。GMLATT框架大致分为四个模块:1).多语映射:利用机器翻译和多语对齐技术,完成源语言与目标语言的映射;2).句子表示:利用Bi-GRU完成源语言句和目标语言句的向量表示;3).多语信息整合:基于上下文Attention完成候选词与句中其它词之间的信息整合,基于跨语言Attention完成源语言和目标语言的信息整合;4).事件类型预测:把整合后的信息先进行非线性变换,然后再通过softmax得到预测的每个事件类型的概率。
论文链接:
http://www.nlpr.ia.ac.cn/cip/~liukang/liukangPageFile/Liu_aaai2018.pdf
4
推荐组:TG
推荐人:冯掌印(研究方向:文本生成)
论文题目:Deliberation Networks: Sequence Generation Beyond One-Pass Decoding
论文作者:Yingce Xia, Fei Tian, Lijun Wu, Jianxin Lin, Tao Qin, Nenghai Yu, Tie-Yan Liu
出处:NIPS 2017
论文主要相关:推敲网络、编码器和解码器、序列生成
简评:现有的encoder-decoder框架在生成序列的时候仅能利用已经生成的词信息,却无法使用未生成的词信息,然而这并不符合人的认知过程。人在写文章时,往往会先写出一版草稿,然后基于对全局信息的理解和思考,在此基础上对草稿进行修改和润色,从而写出最后的佳作。基于以上过程,作者提出了推敲网络。推敲网络与现有encoder-decoder相比,多了一次解码的过程,整个网络包含一个encoder(E)和两个decoder(D1和D2)。网络执行流程如下:E对源端信息进行编码,D1基于编码信息按照普通decoder的解码方式进行初次解码,得到一个草稿。然后D2利用源端编码和D1生成的草稿再次解码得到最终较好的生成序列。在WMT2014英法机器翻译任务和Gigaword文摘任务上的实验结果表明,推敲网络确实能够生成更好的文本序列。其中,机器翻译任务上实现了state-of-the-art效果,BLEU值达到了41.5。基于人的认知过程,作者提出了推敲网络,想法虽然不复杂,但是却让神经网络更加真实,思考问题的方式值得借鉴。
论文链接:
https://www.microsoft.com/en-us/research/wp-content/uploads/2017/12/6775-deliberation-networks-sequence-generation-beyond-one-pass-decoding.pdf
往期链接:
点击文末“阅读原文”即可查看完整赛尔推荐目录
(语言模型、对话生成、情感因素、任务型对话、用户模拟、问答系统)
(推荐系统、情感分析、序列生成)
(自动文摘技术、自动文摘评价、自然语言推理、阅读理解和文本风格迁移)
(多任务学习、文本分类、阅读理解、特征选择、知识融合、图像标注)
本期责任编辑: 丁 效
本期编辑: 刘元兴
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。