ECCV 2020 | CFBI:前背景整合的协作式视频目标分割
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

论文已上传,文末附下载方式
本文作者: 需言(悉尼科技大学ReLER实验室)
https://zhuanlan.zhihu.com/p/159993046
本文已由原作者授权,不得擅自二次转载

论文题目:Collaborative Video Object Segmentation by Foreground-Background Integration
论文地址:arxiv.org/abs/2003.08333
作者:Zongxin Yang, Yunchao Wei, Yi Yang
代码仓库(即将放出,目前处于代码清理阶段):
https://github.com/z-x-yang/CFBI
半监督视频目标分割
视频目标分割(VOS)是计算机视觉领域的一个基础任务,具有非常多潜在的应用场景,例如增强现实和自动驾驶。而半监督视频目标分割的任务,意图在给出视频第一帧中的目标分割的前提下,分割出剩余的整个视频中的该目标。半监督视频目标分割的发展有利于促进很多相关任务的提升,比如视频实例分割和交互式视频目标分割。本文的方法就是聚焦于半监督视频目标分割任务上。
被轻视的背景信息
较早的半监督VOS工作(例如OnAVOS和PReMVOS)会在测试过程中将模型在视频第一帧(具有groundtruth)上进行微调训练(fine-tuning),这可以显著地提升性能但会大幅降低模型的推断速度。最近的工作都旨在直接提升网络的表征能力,从而避开使用微调训练,以达到更好的推断速度。STMVOS引入了一个记忆模块来存储过往帧的信息,但训练的过程中需要使用大量的图片来模拟生成视频序列。FEELVOS基于第一帧和前一帧的像素特征来匹配当前帧中目标的像素,网络结构简单且快速,但性能上却远不能比拟STMVOS。
我们观察到之前的工作都把精力放在如何更好的匹配前景目标上,很少有工作关注背景的特征学习。直观上,如果我们能准确地匹配出背景区域中的物体,那么与背景相对的、剩下的就是前景的物体。此外,视频场景中往往会存在多个相似的目标,例如会议中的多个人、赛车比赛中的多辆车还有农场中的一群动物等等。在这些场景下,如果我们关注其中的某一个物体却忽视其他背景中的相似物体时,我们的预测结果就很容易被这些背景中的物体所影响甚至产生混淆。
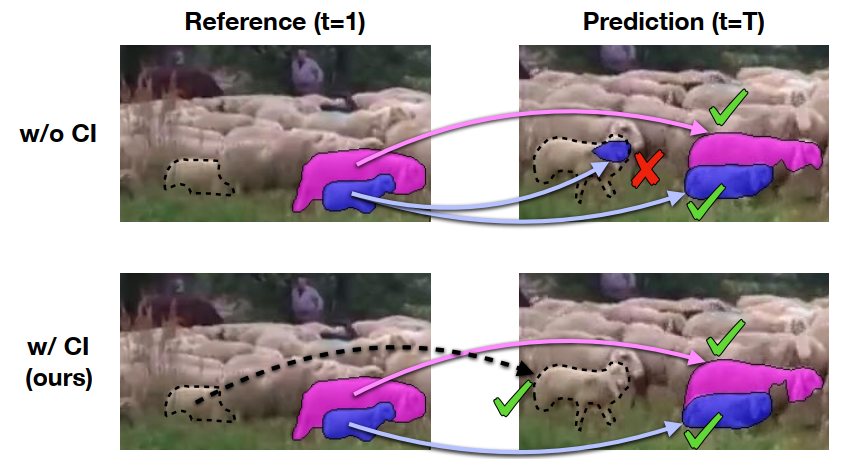
这张图便是一个简单的例子,如果我们忽略背景中的羊群,我们的预测就可能出现错误。但如果我们同时对背景中的羊以及前景中的羊都做匹配,那么原先出错的羊就有可能被正确的归类到背景中,从而避免了混淆的发生。
CFBI:前背景整合的协作式视频目标分割
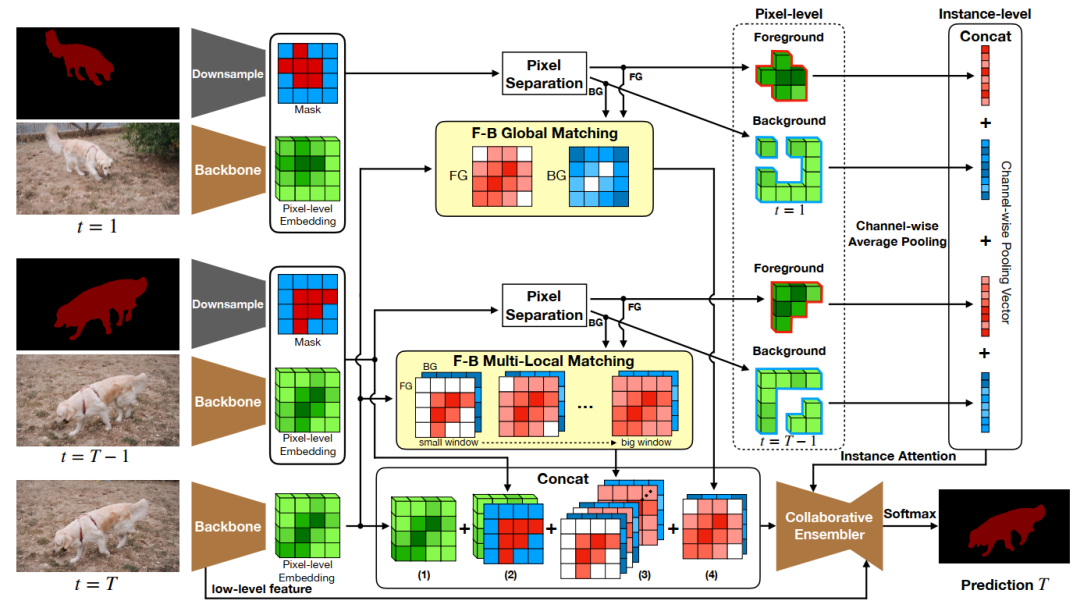
上图便是我们CFBI的整体框架,给定参考帧(第一帧)和前一帧的图像和目标分割,我们的框架会预测出当前帧的分割。
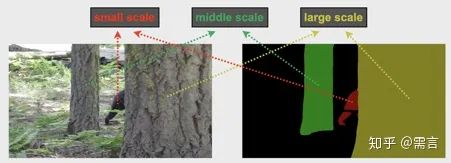
融合不同尺度的信息在VOS中是必要的,因为视频中往往存在着不同尺度大小的物体。一个好的模型需要在处理不同尺度的物体时都有较好的鲁棒性。为此,我们设计的CFBI的模型部分分为两个大部分,第一部分为像素尺度的匹配(框架图的中部),第二部分为实例尺度的注意力模块(框架图的右侧)。
在这两个大部分上,我们都会同时、同等地处理前景和背景信息。前背景信息的分离是简单且直接的,我们直接根据给定的目标分割将参考帧和前一帧的像素特征分为了前景像素特征和背景像素特征,这两种特征被分别用于匹配前景像素区域和背景像素区域。
基于参考帧的前景和背景匹配
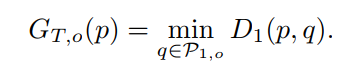
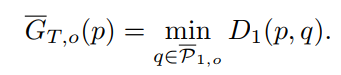
基于前一帧的前景和背景匹配
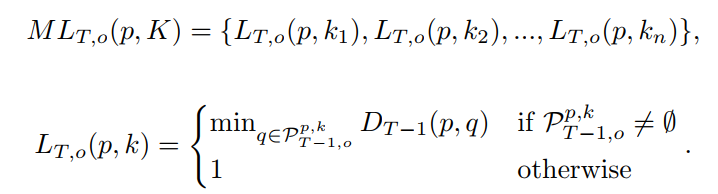
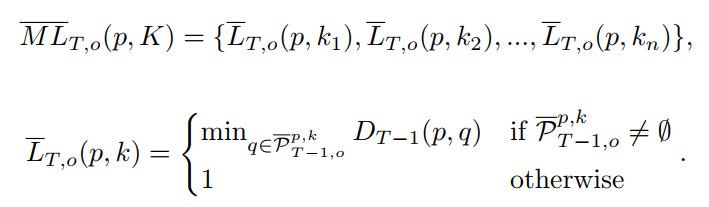
在与参考帧的像素进行匹配时,我们会在当前帧的全平面上进行匹配搜索。而在与前一帧的像素进行匹配时,我们只会在前一帧像素的领域内进行匹配搜索,这是由于帧间的运动范围是有限的。不过,在VOS的数据集上,不同的视频往往有着不同的运动速率,所以我们采用了多窗口(领域)的匹配形式,以使得模型对在处理不同运动速率的物体时更为鲁棒。
此外,我们将前景像素特征和背景像素特征在特征通道上进行了全局池化,将像素尺度的特征转为实例尺度的池化向量。池化向量会基于一个启发于SE-Net的注意力结构,对CFBI的输出模块(Collaborative Ensembler)中的特征的通道进行调整。由此,我们的模型能更好的获取实例尺度的信息。
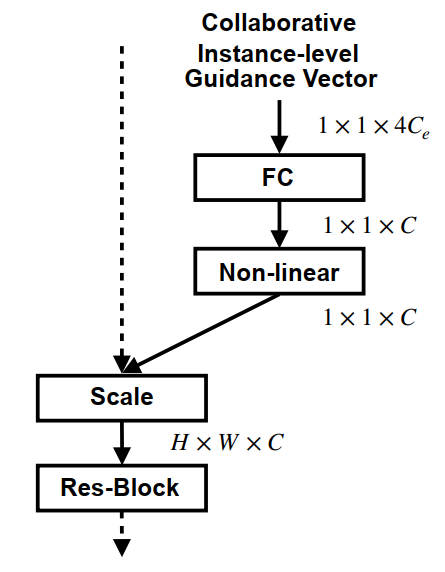
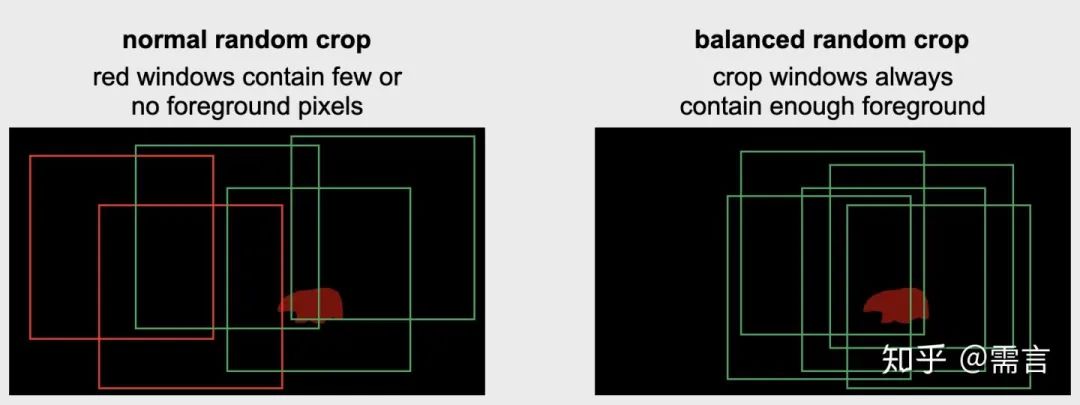
在训练的过程中,我们发现很多的目标要远小于视频图片的尺寸,在这样的情况下,随机裁剪增强时有很大的概率返回一张没有目标物体的图片,因此我们设计了一种均衡的随机裁剪算法,以使得前景目标更容易被裁剪到。
实验结果
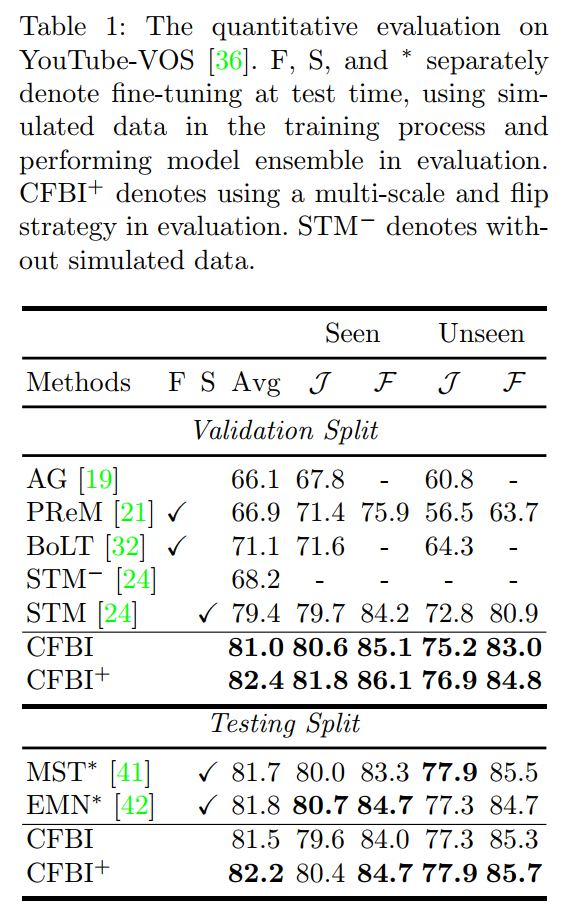
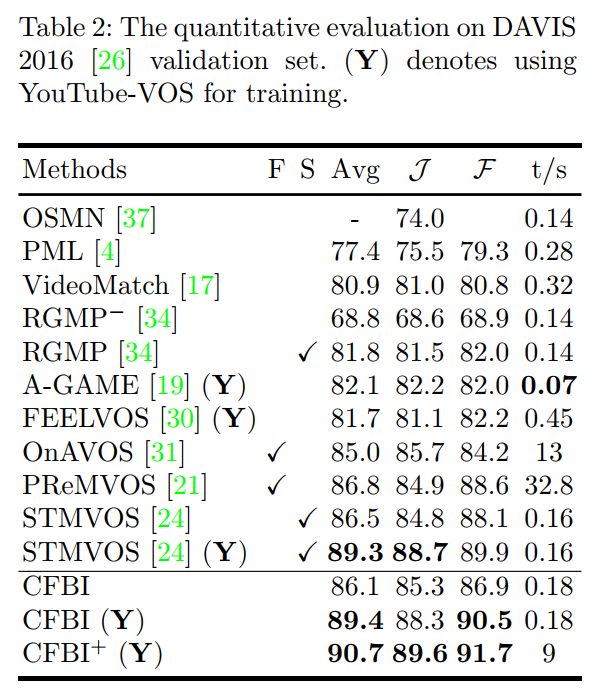
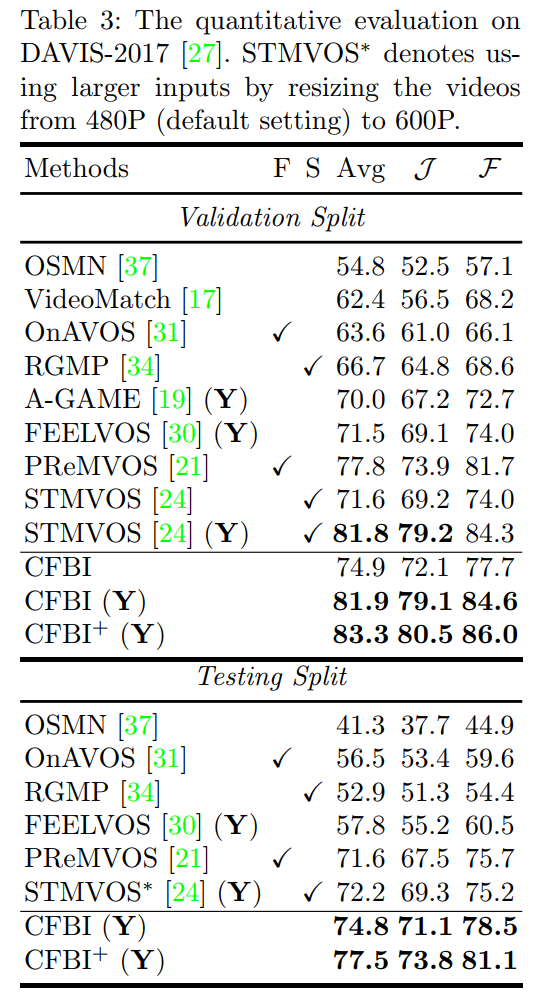
与现有的最佳方法进行对比,我们在三个最受欢迎的数据集上(DAVIS-2016,DAVIS-2017,YouTube-VOS)上均取得了最佳结果。特别是在大型数据集YouTube-VOS 2018 Validation上我们要大幅领先之前的方法。而且在YouTube-VOS 2019 Testing上,我们的方法的单模型性能要高于2019年YouTube-VOS竞赛中的冠军方法。
与STMVOS的可视化结果对比显示出我们的方法对于模糊和遮挡有着更好的鲁棒性。
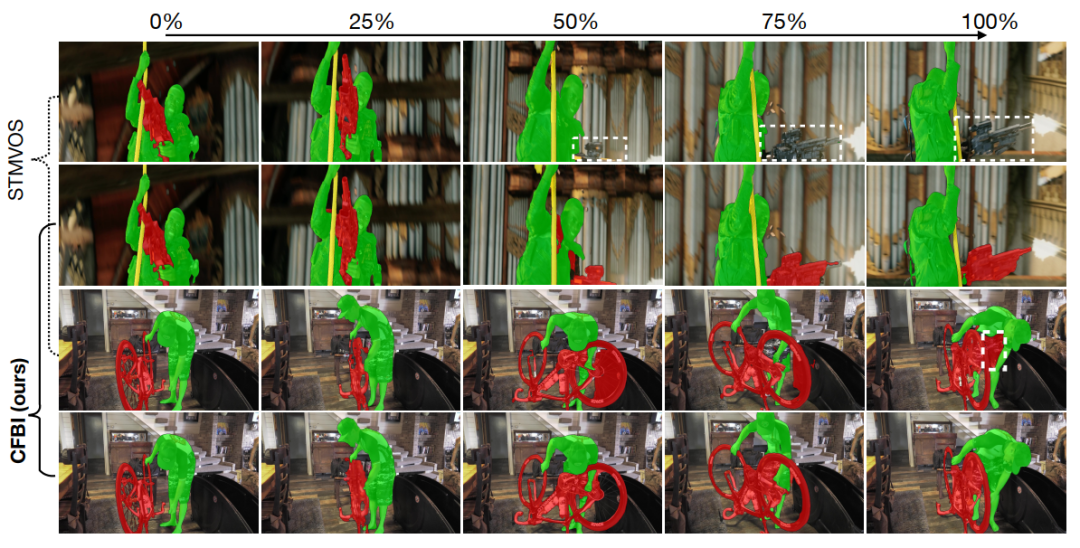
对于复杂的多相似目标的场景,我们的模型也能很好地处理。但当相似的物体直接相邻接时,还是可能会出现部分混淆。

消融实验中关于背景信息的部分充分体现了前背景信息整合对于性能提升的重要性。

感谢您的阅读,欢迎点赞转发评论。
欢迎大家关注我们实验室RelER的后续工作!
下载
在CVer公众号后台回复:CFBI,即可下载本论文
重磅!CVer-图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已满1500+人,旨在交流语义分割、实例分割、全景分割和医学图像分割等方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
点赞和在看!让更多CVer看见


