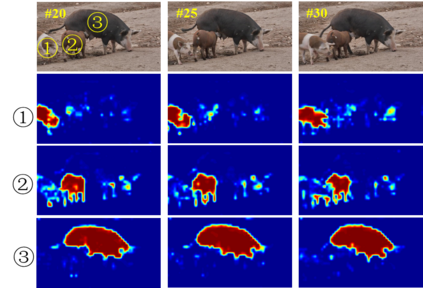
Video Object Segmentation (VOS) is typically formulated in a semi-supervised setting. Given the ground-truth segmentation mask on the first frame, the task of VOS is to track and segment the single or multiple objects of interests in the rest frames of the video at the pixel level. One of the fundamental challenges in VOS is how to make the most use of the temporal information to boost the performance. We present an end-to-end network which stores short- and long-term video sequence information preceding the current frame as the temporal memories to address the temporal modeling in VOS. Our network consists of two temporal sub-networks including a short-term memory sub-network and a long-term memory sub-network. The short-term memory sub-network models the fine-grained spatial-temporal interactions between local regions across neighboring frames in video via a graph-based learning framework, which can well preserve the visual consistency of local regions over time. The long-term memory sub-network models the long-range evolution of object via a Simplified-Gated Recurrent Unit (S-GRU), making the segmentation be robust against occlusions and drift errors. In our experiments, we show that our proposed method achieves a favorable and competitive performance on three frequently-used VOS datasets, including DAVIS 2016, DAVIS 2017 and Youtube-VOS in terms of both speed and accuracy.
翻译:视频对象分割(VOS) 通常是在半监督环境下构建的。 鉴于第一个框架的地面真相分割面, VOS 的任务是在像素层面跟踪和分割视频休息框中的单个或多个利益对象。 VOS 的基本挑战之一是如何通过基于图表的学习框架最充分地利用时间信息来提高性能。 我们展示了一个端对端网络,将当前框架之前的短期和长期视频序列信息存储为处理 VOS 时间模型的时间记忆。 我们的网络由两个时间子网络组成,包括一个短期内存子网络和一个长期内存子网络。 短期内存储子网络模型是视频中相邻区域之间在视频中细微的时空互动。 我们展示了一个基于图表的学习框架,这可以保持本地区域在时间上的视觉一致性。 长期记忆子网络模型通过一个简化的GOS 配置单元(S-GRU) 长期内的时间存储对象的长程演变。我们的网络网络包括一个短期内存储子网络和长程内存储子网络。 短期内存储子网络模型是我们所拟议的视频的竞争性S 和DOVVI 经常显示一种我们用来定位的动态定位和DAVS 的动态数据, 和DVES 两种方法, 显示我们用来显示我们所的可移动的可移动的精确和DVIS 。