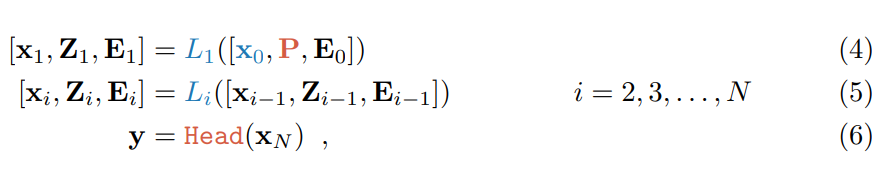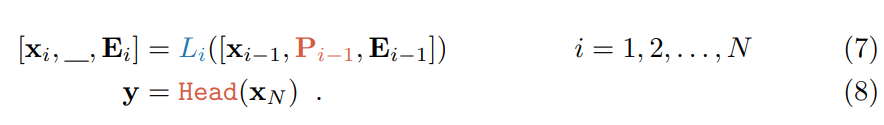选自arXiv
作者:Menglin Jia等
机器之心编译
编辑:赵阳、小舟
来自康奈尔大学、Meta AI 和哥本哈根大学的研究者提出一种优化 Transformer 的有效方案,在只添加少量参数的情况下,对下游任务有极大的提升效果。
识别问题往往是通过预训练大型基础模型处理大量精选或原始数据的方式解决的。这似乎是一种可行的模式:只需利用最新最好的基础模型,就可以在多个识别问题上取得极大的进展。
然而,在实践中,将这些大型模型用于下游任务就存在一些挑战。最直接(通常也是最有效)的适应策略是针对任务对预训练模型进行端到端的全面微调(full fine-tuning)。但这种策略需要为每个任务存储和部署一个单独的主干网络参数副本。因此这种方法通常成本很高且不可行,特别是基于 Transformer 架构的模型会比卷积神经网络大得多。
近日,来自康奈尔大学、Meta AI 和哥本哈根大学的研究者试图找到让大型预训练 Transformer 模型适应下游任务的最佳方法。
![]()
论文地址:https://arxiv.org/abs/2203.12119
首先,解决这个问题的一种简单策略是参考卷积网络适应新任务的方法,如下图 1 (a) 所示。一种较为普遍的方法是只微调参数的一个子集,如分类器头或偏置项(bias term),还有研究考虑在主干网络中添加额外的残差块(或适配器)。这些策略也可以用于 Transformer 模型。然而,这些策略在准确性上往往不如微调参数。
![]()
本研究的研究者探索了一条完全不同的路线。他们不修改或微调预训练 Transformer 本身,而是修改 Transformer 的输入。受 prompt 方法最新进展的启发,研究者提出了一种简单有效的新方法,将 transformer 模型用于下游视觉任务 (图 1 (b)),即视觉 prompt 调优 (visual prompt tuning,VPT)。
VPT 方法只在输入空间中引入少量特定于任务的可学习参数,同时在下游训练过程中固定整个预训练 transformer 主干网络。在实践中,这些附加参数简单地被添加到 transformer 中每个层的输入序列中,并在微调过程中与 linear head 一起更新。
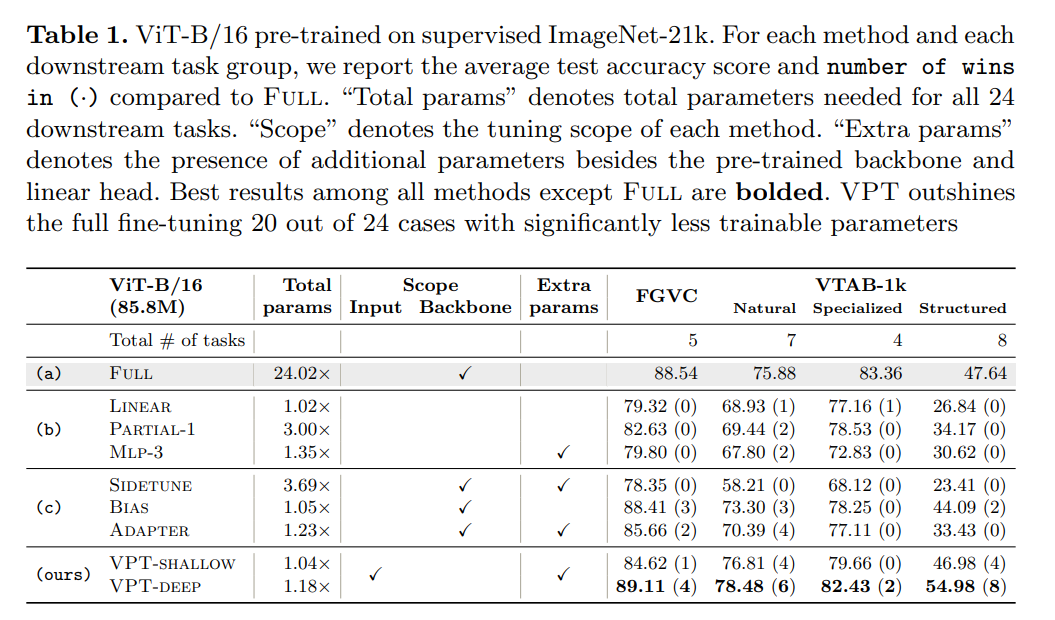
该研究使用预训练 ViT 主干网络完成 24 个不同领域的下游识别任务,VPT 击败了所有其他迁移学习 baseline,甚至在 20 种情况下超过了全面微调方法,而只用到极少量的参数(少于主干网络参数的 1%)。
实验结果表明 VPT 具有独特的优势。在 NLP 中, prompt 方法只能在一些特定情况下与全面微调方法性能相当。而 VPT 在小数据环境中也特别有效,在各种数据规模上均保持着优势。此外,VPT 在 Transformer 的扩展和设计方面也具有竞争力。综上所述,VPT 是适应不断增长的视觉主干网络的最有效方法之一。
VPT 将少量可学习参数引入 Transformer 的输入空间,并在下游训练阶段固定主干网络。总体框架如图 2 所示。
![]()
对于 N 层的 Vision Transformer (ViT),输入图像分为 m 个固定大小的 patch {I_j ∈ R^{ 3×h×w} | j ∈ N, 1 ≤ j ≤ m}. 。h, w 是图像 patch 的高度和宽度。接下来每个 patch 先是嵌入到具有位置编码的 d 维潜在空间中:
![]()
其中,E_i = {e^j_i ∈ R^d | j ∈ N, 1 ≤ j ≤ m} 表示图像 patch 嵌入的集合,并且也作为第 (i+1) 个 Transformer 层 L_(i+1) 的输入。连同一个额外的可学习分类 token([CLS]),整个 ViT 被表述为:
![]()
x_i ∈ R^d 表示 [CLS] 在 L_(i+1) 的输入空间的嵌入。[・,・] 表示在序列长度维度上的融合(stacking)和级联(concatenation),即 [x_i , E_i ] ∈ R^{(1+m)×d} 。每层 L_i 由多头自注意力 (MSA) 和前馈网络 (FFN) 以及 LayerNorm 和残差连接组成。神经分类头用来将最后一层的 [CLS] 嵌入 x_N ,映射到预测的类概率分布 y 中。
给定一个预训练的 Transformer 模型,该研究在嵌入层之后的输入空间中引入 p 个维度为 d 的连续嵌入,即 prompt。在微调期间仅更新特定于任务的 prompt,而 Transformer 主干保持不变。根据所涉及 Transformer 层的数量,研究者提出两种变体,VPT-shallow 和 VPT-deep,如图 2 所示。
VPT-Shallow:*prompt 仅插入到第一个 Transformer 层 L_1 中。每个 prompt 都是一个可学习的 d 维向量。p 个 prompt 的集合表示为 P = {p_k ∈ R^d | k ∈ N, 1 ≤ k ≤ p}, shallow-prompted ViT 为:
![]()
其中,Z_i ∈ R^{p×d} 表示第 i 个 Transformer 层计算得到的特征,[x_i , Z_i , E_i ] ∈ R^{(1+p+m)×d} 。
如图 2 所示,橙色和蓝色标记的变量分别表示可学习和固定的参数。值得注意的是,对于 ViT,x_N 相对于 prompt 的位置是不变的,因为它们是在位置编码之后插入的,例如,[x_0, P, E_0] 和 [x_0, E_0, P] 在数学上是等价的。这也适用于 VPT-Deep。
VPT-Deep:在每个 Transformer 层的输入空间都引入了 prompt。对于第 (i+1) 层 L_(i+1),输入的可学习 prompt 集合表示为 P_i = {p ^k_i ∈ R^d | k ∈ N, 1 ≤ k ≤ m}。VPT-Deep 的 ViT 为:
![]()
视觉 prompt 的存储:VPT 在存在多个下游任务时具有显著优势,只需要为每个任务存储学习到的 prompt 和分类头,并重新使用预训练 Transformer 模型的原始副本,这显著降低了存储成本。例如,给定一个具有 8600 万参数的 ViT-Base(d = 768),50 个 VPT-Shallow 和 VPT-Deep 产生额外的 p × d = 50 × 768 = 0.038M 和 N × p × d = 0.46M 参数,分别仅占所有 ViT-Base 参数的 0.04% 和 0.53%。
下表 1 展示了在 4 个不同的下游任务组上微调预训练 ViT-B/16 的结果,并将 VPT 与其他 7 种调优方法进行了比较。我们可以看到:
VPT-Deep 在 4 个问题类别中的 3 个(24 个任务中的 20 个)上优于其他全部方法(表 1 (a)),同时使用的模型参数总量显著减少(1.18× VS 24.02×)。可见,VPT 是一种很有前途的方法,可以在视觉任务中适应更大的 Transformer。
VPT-Deep 在所有任务组中都优于所有其他的参数调优方法(表 1 (b,c)),表明 VPT-deep 是存储受限环境中最好的微调策略。
虽然比 VPT-deep 略差一点,但 VPT-shallow 仍然比(表 1 (b))中的 head-oriented 方法性能更好。如果存储限制很严重,VPT-shallow 是部署多任务微调模型的合适选择。
![]()
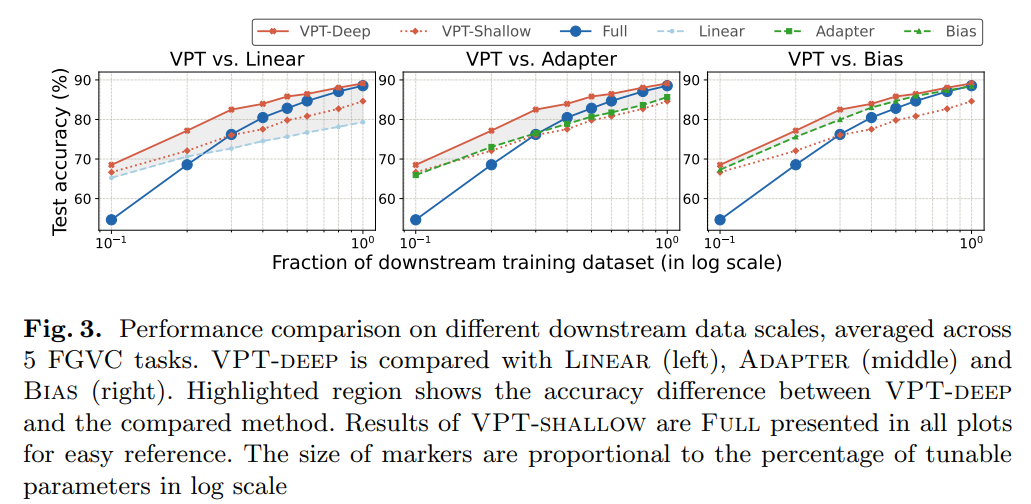
图 3 显示了每种方法在不同训练数据规模上的平均任务结果。VPT-deep 在各种数据规模上都优于其他 baseline。
![]()
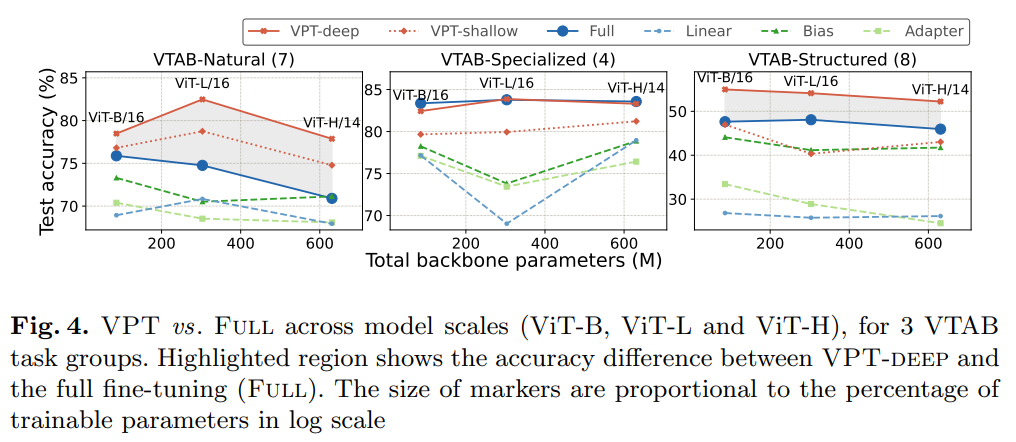
图 4 显示了 3 种不同主干规模下 VTAB-1k 的性能:ViT-Base/Large/Huge,VPT-deep 显著优于 Linear 和 VPT-shallow。
![]()
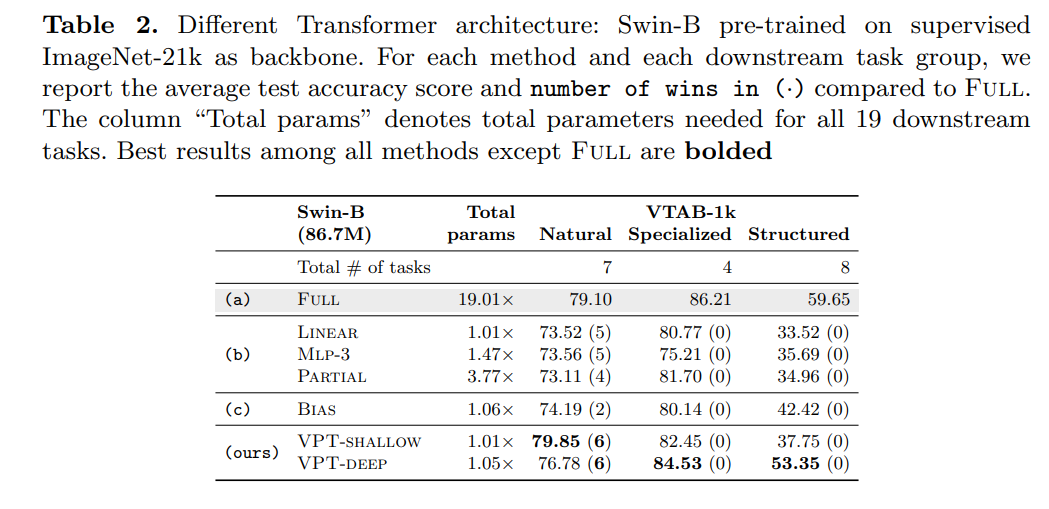
此外,研究者还将 VPT 扩展到 Swin 上,在局部移位窗口中使用 MSA,并在更深层合并 patch 嵌入。为简单且不失一般性起见,研究者以最直接的方式实现 VPT:prompt 被用于局部窗口,而在 patch 合并阶段被忽略。
如下表 2 所示,该研究在 ImageNet-21k 监督的预训练 Swin-Base 上进行实验。尽管在这种情况下,Full 总体上能产生最高的准确率(总参数成本也很高),但对于 VTAB 的三个子组,VPT 仍然优于其他微调方法。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com