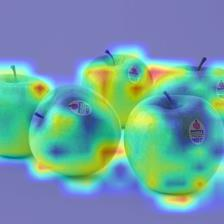
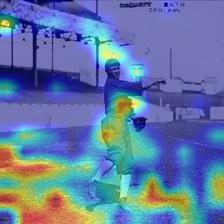
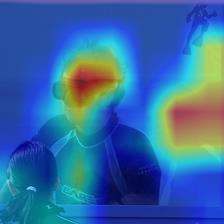
Vision transformers have shown great success on numerous computer vision tasks. However, its central component, softmax attention, prohibits vision transformers from scaling up to high-resolution images, due to both the computational complexity and memory footprint being quadratic. Although linear attention was introduced in natural language processing (NLP) tasks to mitigate a similar issue, directly applying existing linear attention to vision transformers may not lead to satisfactory results. We investigate this problem and find that computer vision tasks focus more on local information compared with NLP tasks. Based on this observation, we present a Vicinity Attention that introduces a locality bias to vision transformers with linear complexity. Specifically, for each image patch, we adjust its attention weight based on its 2D Manhattan distance measured by its neighbouring patches. In this case, the neighbouring patches will receive stronger attention than far-away patches. Moreover, since our Vicinity Attention requires the token length to be much larger than the feature dimension to show its efficiency advantages, we further propose a new Vicinity Vision Transformer (VVT) structure to reduce the feature dimension without degenerating the accuracy. We perform extensive experiments on the CIFAR100, ImageNet1K, and ADE20K datasets to validate the effectiveness of our method. Our method has a slower growth rate of GFlops than previous transformer-based and convolution-based networks when the input resolution increases. In particular, our approach achieves state-of-the-art image classification accuracy with 50% fewer parameters than previous methods.
翻译:视觉变压器在众多计算机视觉任务中表现出巨大的成功。然而,其核心部分,即软式关注,却禁止视觉变压器向高分辨率图像扩展,因为计算复杂度和记忆足迹都是四分法。尽管自然语言处理(NLP)任务引入线性关注以缓解类似问题,但直接将现有线性关注运用于视觉变压器可能不会产生令人满意的结果。我们调查了这一问题,发现计算机的视觉任务比NLP任务更多地侧重于本地信息。根据这一观察,我们展示了一种“维度注意”结构,向具有线性复杂性的视觉变压器引入了局部偏差。具体地,我们根据每幅图像补位,根据以其相邻的2D曼哈顿距离来调整其关注度。在这种情况下,相邻的补音频带会比远处的补差得到更大的关注。此外,由于我们的“维度”关注度需要象征性的长度比特征层面大得多,因此我们进一步建议一个新的“维度变压变压法”变压器结构(VT)结构,在不破坏准确度方面。我们之前的图像变压率网络进行了广泛的实验,我们以前的变压方法比以前的变压法化方法。我们比以前的变压了以前的变压方法。