听说Attention与Softmax更配哦~

不知道大家留意到一个细节没有,就是当前 NLP 主流的预训练模式都是在一个固定长度(比如 512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了 Base 版的 GAU 实验后才发现 GAU 的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......

模型回顾
在FLASH:可能是近来最有意思的高效Transformer设计中,我们介绍了“门控注意力单元 GAU”,它是一种融合了 GLU 和 Attention 的新设计。
除了效果,GAU 在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要 Softmax 归一化,可以换成简单的 除以序列长度:
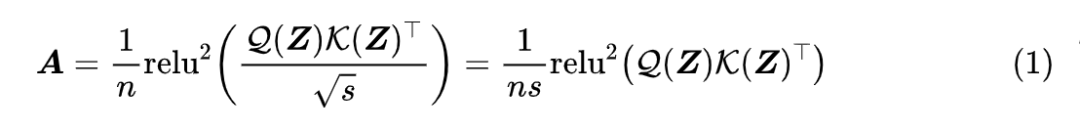
这个形式导致了一个有意思的问题:如果我们预训练的时候尽量将样本整理成同一长度(比如 512),那么在预训练阶段 n 几乎一直就是 512,也就是说 n 相当于一个常数,如果我们将它用于其他长度(比如 64、128)微调,那么这个 n 究竟要自动改为样本长度,还是保持为 512 呢?
直觉应该是等于样本长度更加自适应一些,但答案很反直觉:n 固定为 512 的微调效果比 n 取样本长度的效果要明显好!这就引人深思了......

问题定位
如果单看 GAU 的预训练效果,它是优于标准 Attention 的,所以 GAU 本身的拟合能力应该是没问题的,只是 在样本长度方面的迁移能力不好。为了确认这一点,笔者也尝试了混合不同长度的样本来做 GAU 的预训练,发现结果会有明显的改善。
那么,可能是 GAU 的什么地方出了问题呢?其实这不难猜测,GAU 的整体运算可以简写成 ,其中 都是 token-wise 的,也就是说它们根本不会受到长度变化的影响,所以问题只能是出现在 中。
以前我们用标准的 Attention 时,并没有出现类似的问题,以至于我们以前都无意识地觉得这是一个“理所当然”的性质。所以,我们需要从 GAU 的 Attention 与标准 Attention 的差异中发现问题。前面说了,两者不同的地方有两点,其一是多头 Attention 变成单头 Attention,但是这顶多会让效果有一定波动,而我们测出来的结果是大幅下降,所以问题就只能出现在另一点,也就是归一化方式上,即 Attention 的 softmax 换成 所带来的。
验证这个猜测很简单,笔者将 GAU 中 Attention 的归一化方式换回 Softmax 后重新训练一个 GAU 模型,然后微调测试不同长度的任务,发现其效果比 时明显要好。所以,我们得出结论:Attention 还是与 Softmax 更配~

原因分析
为什么更符合直觉的、自适应长度的 n 反而表现不如固定的 n 呢?既然我们已经以往用 Softmax 是没有这个问题的,所以我们不妨从 Softmax 出发找找灵感。Softmax 的操作是:
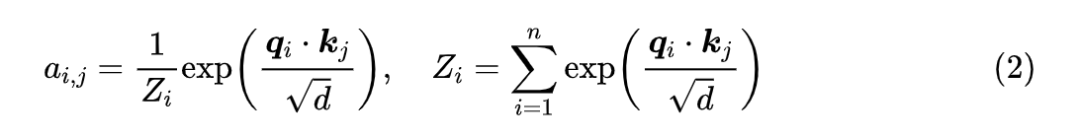
一个直接的问题就是:
跟 n 的关系是怎样的呢?如果真有
,那么理论上将
换成 n 应该能取得相近的效果,至少不会是特别差的那种。
然而,我们知道注意力的重点是“注意”,它应该有能力“聚焦”到它认为比较重要的几个 token 上。同时,以往关于高效 Transformer 的一些实验结果显示,把标准 Attention 换成 Local Attention 后结果并不会明显下降,所以我们可以预计位置为 i 的 Attention 基本上就聚焦在 i 附近的若干 token 上,超出一定距离后就基本为 0 了。事实上,也有很多事后的可视化结果显示训练好的 Attention 矩阵其实是很稀疏的。
综合这些结果,我们可以得出,存在某个常数 k,使得 时 都相当接近于 0,这样一来 应该更接近 而不是 ,这就意味着 很可能跟 n 是无关的,或者说跟 n 的数量级关系至少是小于 的!因此,我们如果要将 替换成别的东西,那应该是一个比 n 的一次方更低阶的函数,甚至是一个常数。
现在回看 GAU,它的激活函数换成了 时,其 Attention 情况是类似的,甚至会更稀疏。这是因为 操作有直接置零的作用,不像 总是正的,同时 GAU“标配”旋转位置编码 RoPE,在Transformer升级之路:博采众长的旋转式位置编码中我们就推导过,RoPE 本身自带一定的远程衰减的能力。综合这些条件,GAU 的归一化因子也应该是低于 的阶甚至是常数级别的。

熵不变性
由此,我们可以总结出 GAU 的三个解决方案,一是预训练和微调都用同一个固定的 n;二是依然使用动态的样本长度 n,但是预训练时需要用不同长度的样本来混合训练,不能只使用单一长度的样本;三就是像 Softmax 那样补充上一个归一化因子,让模型自己去学:
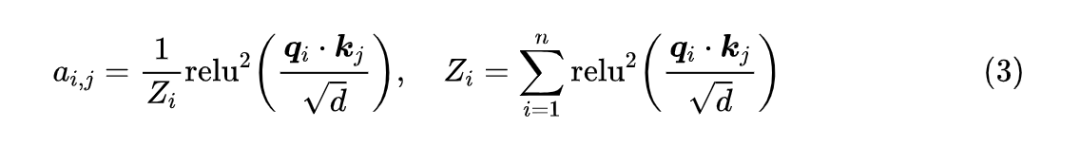
既然存在这些解决方案,那为什么我们还说“Attention 与 Softmax 更配”呢?GAU 的 哪里不够配呢?首先,我们看 GAU 原论文的消融实验,显示出 换成 Softmax,效果基本是一致的:
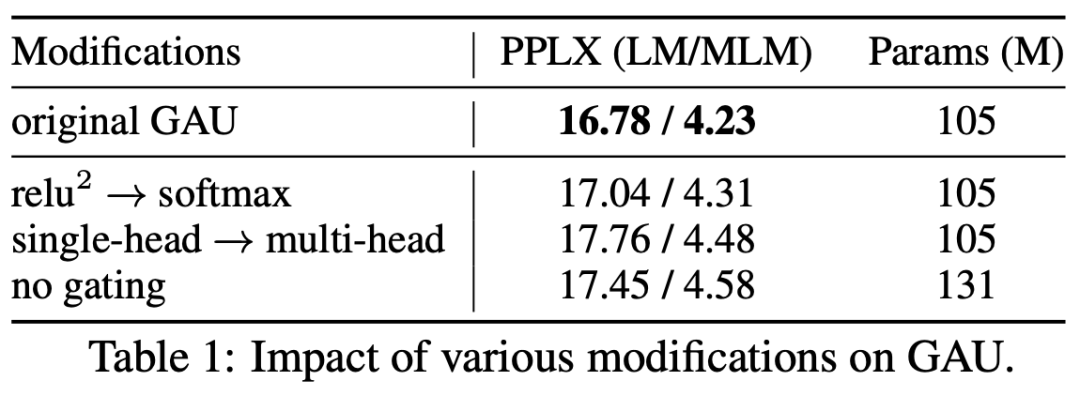
▲ GAU的squared_relu换成softmax效果是相近的
有了这个基本保证之后,我们就可以看 Softmax 比 好在哪里了。我们看刚才提到的 GAU 三个解决方案,方案一总让人感觉不够自适应,方案二必须用多种长度训练显得不够优雅,至于方案三补充了归一化因子后形式上相比 Softmax 反而显得“臃肿”了。所以,总体来说还是用 Softmax 显得更为优雅有效。
此外,泛化能力可以简单分为“内插”和“外推”两种,在这里内插(外推)指的是测试长度小于(大于)训练长度。我们刚才说归一化因子是常数量级,更多是在内插范围内说的。对于外推来说,如果长度足够长, 都“挤”在一起,所以很难保持距离超过某个范围就很接近于 0 的特性。而如果我们用 Softmax 的话,就是它可以推导出一个“熵不变性”的版本,来增强模型的外推能力:
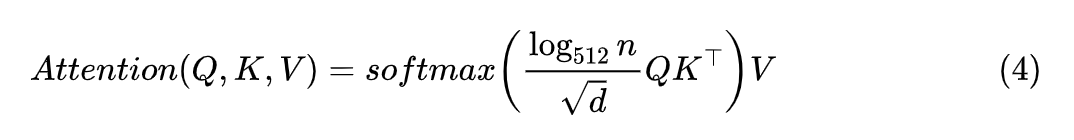
在从熵不变性看Attention的Scale操作中我们做过简单的对比实验,显示该版本确实能提高模型在超出训练长度外的效果。
那么, 能否推一个“熵不变性”的版本呢?答案是不能,因为它相当于是通过温度参数来调节分布的熵,这要求激活函数不能是具备正齐次性,比如对于幂函数有 ,归一化后 就抵消了,不起作用。激活函数最好比幂函数高一阶,才比较好实现这个调控,而比幂函数高阶的函数,最常见就是指数函数了,而指数归一化就是 Softmax 了。

实验结果
本文分析了 GAU 在微调效果不佳的原因,发现 Attention 的归一化因子应该是接近常数量级的,所以 GAU 用 n 或者 做归一化因子会表现不佳。总的来说,笔者认为 Attention 还是跟 Softmax 更配,它是一个不错的基准,并且还可以通过“熵不变性”的拓展来进一步增强外推能力。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



