来源:arXiv
编辑:LRS
【新智元导读】Transformer在CV领域大放异彩,如何与传统CNN结合、利用CNN的优势一直是研究人员思考的问题。最近中科院、北大、微软亚研、百度联手提出HRFormer模型,能够在多分辨率并行处理图像,新模型架构参数量降低40%,性能却更强!
Vision Transformer(ViT)在ImageNet分类任务中表现出极其强大的性能。
在ViT的基础上,许多后续工作通过通过知识蒸馏(knowledge distillation)、采用更深层次的网络、引入卷积运算方法来提高分类精度,还有一些研究方向关注于如何扩展Transformer以解决更广泛的视觉任务,例如如目标检测,语义分割,视频理解等任务。
ViT需要将图像分割为大小为16×16的图像块(image patch)序列,并提取每个图像块的特征表示,这种方法存在一个缺陷就是ViT 的表示空间丢失了很多细节,导致在一些需要精细预测的任务中表现不佳。
并且ViT只能输出单尺度(single-scale)特征表示,缺少了通过数据增强捕获多尺度变换的能力。为了减少特征粒度的损失和模拟多尺度变化,提出了一种包含丰富空间信息的高分辨率变换器(HRformer),并构造了稠密预测的多分辨率表示方法。
为了减少特征粒度的损失并对多尺度变化进行建模,中科院计算所、北京大学、微软亚洲研究院、百度联合提出了一个包含更丰富空间信息的高分辨率Transformer(HRFormer),能够为dense prediction构造多分辨率表示,目前论文已被NeurIPS 2021接收。
论文作者王井东是百度AI的首席CV架构师,他于2007年9月至2021年9月是微软研究亚洲的高级首席研究员。主要研究领域包括神经结构设计,人类姿势估算,语义分割,图像分类,物体检测,大规模索引和突出对象检测。
另一位作者陈熙霖博士,是中科院计算所的研究员,ACM Fellow,IEEE Fellow,IAPR Fellow,中国计算机学会会士,国家杰出青年基金获得者。主要研究领域为计算机视觉、模式识别、多媒体技术以及多模式人机接口。先后主持多项自然科学基金重大、重点项目、973计划课题等项目的研究。
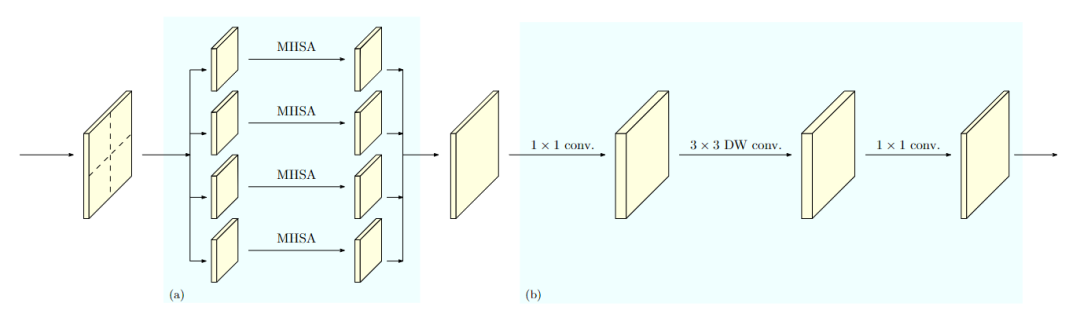
HRFormer采用HRNet中的多分辨率并行设计。首先HRFormer在stem和第一阶段都采用卷积,因为研究结果已经证明了卷积在图像处理的前期表现得更好。
并且HRFormer在整个处理过程中保持高分辨率流,并行处理中、低分辨率流有助于提高高分辨率表示。利用不同分辨率的特征图,HRFormer模型能够模拟图像的多尺度变化。
同时HRFormer通过与多尺度融合模块交换多分辨率特征信息,能够混合使用短距离和长距离注意力。在每一个分辨率下,HRFormer使用采用局部窗口的自注意力机制来降低内存消耗和计算复杂度。
研究人员还将表示映射划分为一组非重叠的小图像窗口,并在每个图像窗口中分别进行自注意力,这个操作将内存和复杂度从二次降低到到线性。
并且在前馈网络(feed forward network)中引入了3×3深度卷积,使得这个卷积层能够跟踪局部窗口的自注意力来在没有直接连接的图像窗口之间交换信息。这有助于扩展接收范围,对于密集的预测任务至关重要。
HRFormer的输出由四个不同分辨率的特征图组成,可以用于不同的任务。
图像分类,需要将四个分辨率特征映射映射到一个向量,输出通道分别更改为128、256、512和1024。应用卷积对它们进行,并输出到2048通道的最低分辨率特征图。最后应用全局平均池操作到最终分类器;
姿态估计,只需要在最高分辨率特征图上应用回归头(regression head);
语义分割,将语义分割头应用到所有低分辨率表示上采样到最高分辨率的级联表示上。
在实验部分,研究人员对模型在上述三个任务中的性能分别进行了实验,并在各种benchmark上取得了更好的性能。
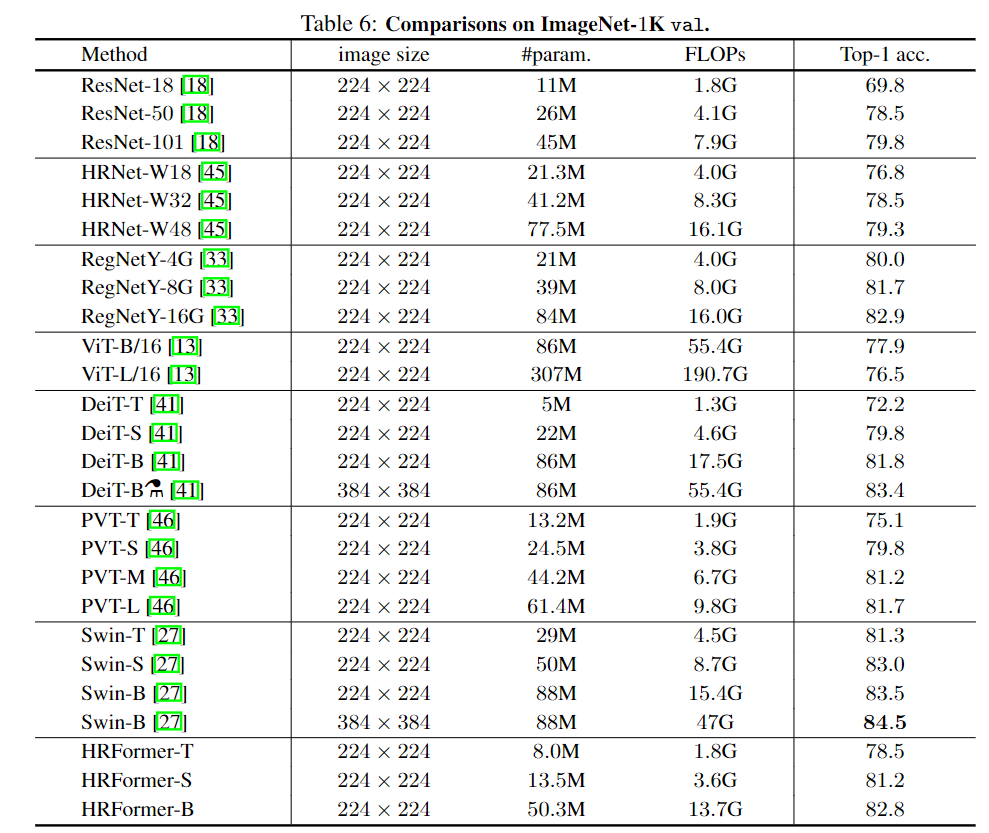
在图像分类中,研究人员主要在ImageNet-1K进行了比较,它由128m列图像和50k值图像组成,共有1000个类。训练过程使用AdamW优化器、余弦衰减学习率计划、权重衰减为0.05以及一包递增策略(包括rand递增、mixup和cutmix策略),将所有batch size为1024的模型训练300个epoch。HRFormer-T和HRFormer-S的训练使用了8×32G-V100 GPU,HRFORMER-B使用了32×32G-V100 GPU。
研究人员将一些代表性cnn方法和ViT方法进行了比较,其中所有模型都只在ImageNet-1k上进行了训练。为了公平起见,没有包括在较大数据集(如ImageNet-21K)训练的ViT-Large模型的结果。
实验结果可以看出,HRFormer-B比DeiT-B 模型性能提高了1.0%,同时节省了近40%的参数和20%的FLOPs。
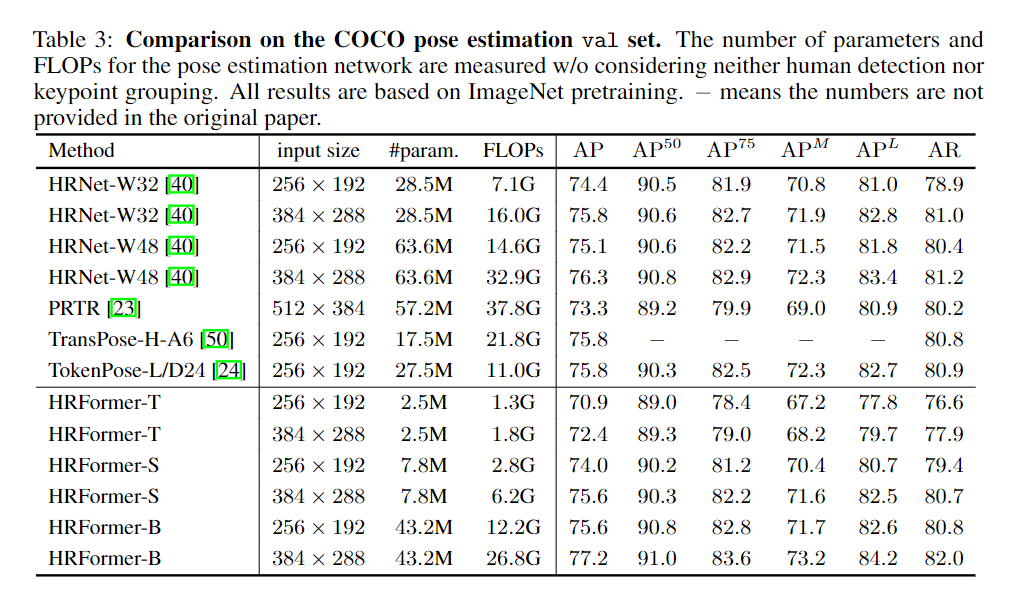
在人体姿势估计的实验中,研究人员使用了超过20万张图像和25万个标有17个关键点的人体实例的数据来比较性能。并且在COCO train2017数据集上训练模型,包括5万7千张图片和150K个人体实例。
训练的设置遵循mmpose的大多数默认训练和评估设置,并将优化器从adam更改为adamw。
对于训练的batch size,由于GPU内存有限,研究人员选择256作为HRFormer-T和HRFormer-S的batch size,HFormer-B则为
128。
COCO姿态估计任务的每个HRFormer实验需要8×32g-v100gpu。
和一些代表性卷积方法相比,HRFormer-B的参数量降低了32%,FLOPS减少了19%,提高了0.9%的性能。相比HRNet-W48,HRFormer-B性能提高约0.7%,并且有更少的参数量。
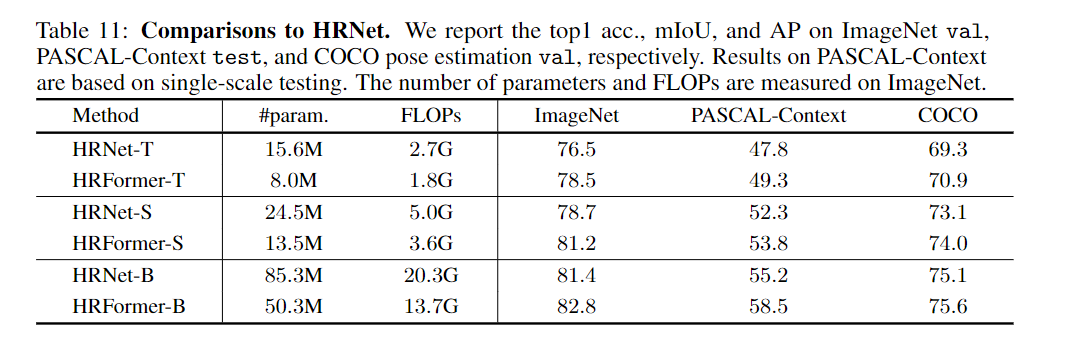
在消融实验中,作者通过将所有的Transformer替换为由两个3×3卷积组成的常规基本块,将HRFormer 与具有几乎相同架构配置的卷积HRNet 在ImageNet、Pascal Context和Coco进行比较。
可以观察到,在模型和计算复杂度较低的各种配置下,HRFormer 在三个任务上分别以2.0%、1.5%和1.6%性能显著优于 HRNet,而只需要大约50%的参数和FLOPS。
参考资料:
https://arxiv.org/abs/2110.09408?
![]()