AI说 | 叮咚音箱不智障,全靠CRF技术棒
AI说是京东大数据推出的解密人工智能及大数据专业知识、探索行业科技前沿的技术专栏。本期栏目邀请到了NLP研发部的数据挖掘工程师高维国畅谈CRF在叮咚音箱中的应用。
人机交互基于人工智能和大数据,是人与计算机之间使用某种对话语言,为完成确定任务的人与计算机之间的信息交换过程。在人机交互技术领域,存在多种交互方式,比如体感交互、眼动跟踪、语音交互、生物识别等方式,今天要介绍就是京东在语音交互方面的实践——叮咚音箱。
叮咚音箱是一款搭载智能语音助手的产品。用户可以购物、点歌、查新闻、查天气、闲聊。在叮咚音箱的NLU(nature language understand)自然语言理解模块中, CRF(conditional random field )条件随机场模型起到重要的作用。分词、词性标注、命名实体识别、槽值提取等都是CRF模型的重要应用。
本文将从CRF概述和音箱分词两大模块阐述观点。
CRF概述
CRF(条件随机场),是指在给定观测序列条件下,计算状态序列的条件概率分布模型。观测序列是用户可以观测到的序列,可以认为是机器学习中输入变量X,而状态序列是我们需要模型预测的序列,可以认为是要预测的标签序列label。
首先我们通过槽值提取任务的例子来了解下CRF模型中的一些基本概念。槽值提取(slot filling)是一个序列标注任务,可以用CRF建模。可以简单把槽值提取理解为识别某个词是哪种类型的过程。接下来的例子会帮助我们理解什么是CRF模型以及什么是槽值提取。
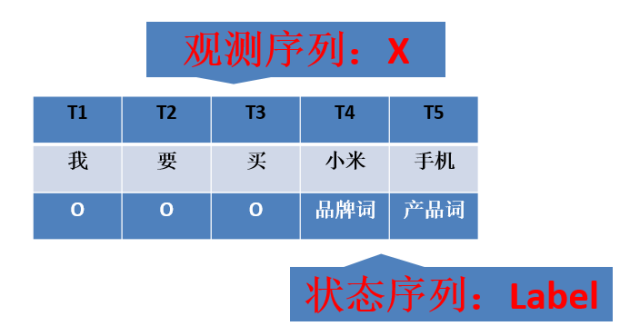
CRF槽值提取序列标注例子
在上图中,我们期望CRF模型根据“我/要/买/小米/手机”观测序列(X),识别出“O/O/O/品牌词/产品词”这样一个状态序列(Y)。即:识别出小米是品牌词,手机是产品词。这里的“品牌词”、“产品词”就是一个槽,而“小米”“手机”是对应的槽值,将槽值“小米”“手机”与槽“品牌词”“产品词”对应上就是槽值提取任务。其中“我”对应T1时刻,“要”对应T2时刻,以此类推。(其中用“/”来分割各个分词结果以及预测值,O代表other。)
CRF条件随机场可以用概率图的方式来表示。以下是CRF条件随机场对应的概率图:
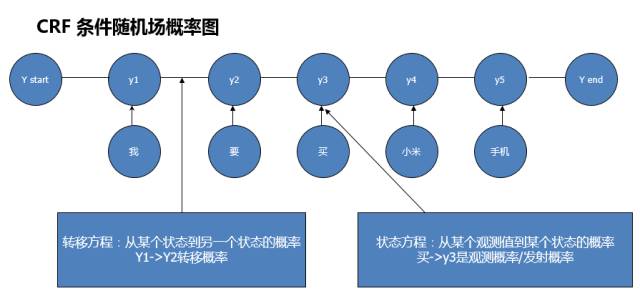
CRF概率图
在上图中:y1、 y2、 y3、 y4、 y5 表示状态序列,“我”“要”“买”“小米”“手机”是观测序列。y1结点到y2结点之间的边(即各个状态结点之间的边)表示转移概率, “我”结点到y1结点的边(即各个观测结点和状态结点之间的边)表示观测概率。
CRF模型的训练过程就是求解转移概率和观测概率的过程;CRF模型预测就是通过这2个概率来计算最短路径。接下来我们介绍下CRF模型及其训练方法和预测。
CRF模型
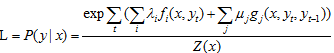
该公式是CRF条件随机场对应的假设函数,P(y|x)表示在输入为观测序列的条件下,输出为某个状态序列的条件概率。
例如P(”O/O/O/品牌/产品”|”我/要 买/小米/手机”)。分子表示概率图中各个最大团概率的乘积;分母是归一化因子。(无向图中任何两个结点均有边连接的结点子集称为团。最大团就是不能在加入任何一条边的团。)
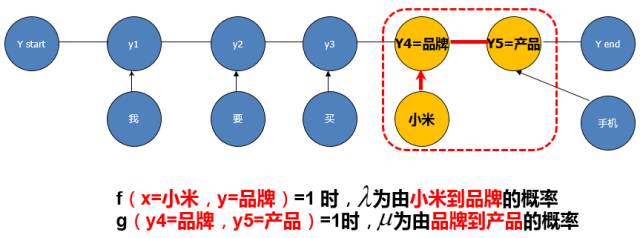
CRF公式示例图
以上整个图的概率等于该图中各个最大团对应随机变量概率的乘积。以红色方框中的子图来举例:该图的团是{结点“小米”,y4结点}的子图和{结点y4,结点y5}的子图,同时这两个子图都是最大团,而{结点“小米”, y4, y5}不是最大团,因为结点“小米”与y5没有边。对于红色方框中的子图概率为P(品牌|我/要/买/小米)*P(产品|品牌)。其中表示由小米到品牌的概率,表示由产品到品牌的概率。
模型训练
CRF条件随机场模型的训练是求解转移概率和观测概率的过程,其采用L-BFGS方式来求解。
(L-BFGS是求解优化问题的有效方法之一,相关详细介绍可以参考《统计学习方法》)
模型预测
当通过L-BFGS求出转移概率和观测概率之后如何预测呢?我们采用Viterbi算法 (动态规划算法)来预测。条件随机场的预测问题是给定条件随机场p(y|x)和观测序列X,求条件概率最大的状态序列Y,即对观测序列进行标注。我们通过Viterbi算法选择概率最大的那条路径。下面通过一个例子说明下viterbi算法的计算过程。
例如:观测序列为“小米/ 手机”,我们要预测的状态序列为“品牌/产品”(小米是T1时刻,手机是T2时刻)。从T1时刻到T2,一共有4条路。在这个例子中我们假设从11结点转移到22结点的概率最大,在T1时刻到11结点的路径最大概率和到12结点的路径最大概率相同。到T2时刻一共有4条路径,每个路径的概率值见下图。


T2时刻手机应该预测为品牌还是产品?在求T2时刻的最大概率路径时我们采用Viterbi来求解。
过程如下:T2时刻一共有4条路径可以选择,即11结点到21节点,11结点到22结点,12结点到21结点,12结点到22结点,其中11结点到22结点的概率最大通过Viterbi算法选择概率最大的一条路径是:小米是品牌,到手机是产品的概路径,因为11到22的概率最大。T2时刻的概率最大值等于T1时刻概率最大值(即11结点的概率最大值)加上由11结点到22结点的概率值。
接下来我们会介绍下CRF的一个重要应用:分词。
叮咚音箱分词
叮咚音箱支持的场景包括购物、百科、音乐、闲聊等。为了更好的理解用户意图,我们需要有准确的分词模型,但互联网公开的中文分词模型在这些领域效果都比较差。
以下是原有Stanford中文分词模型在购物语句上的分词结果:
荣/事达/电水壶/多少钱
帮/我/妈/买/一 个/美/的/洗衣机
在上面这2个例子中荣事达被错误的分成“荣/事达”;而“美的”被错误的分成“美 /的”。错误的分词结果会导致叮咚音箱错误的理解用户意图,返回错误结果,影响用户体验。为了解决在这些垂直领域分词错误的问题,我们需要训练自己的分词模型。
本节内容包括:叮咚音箱分词、分词后处理以及强制分词人工干预字典方法。
叮咚音箱分词
我们使用 Stanford 开源分词工具包来进行分词模型的训练。该工具包提供了分词模型训练以及预测的方法。之所以选择Stanford工具包主要是因为其提供了一整套NLP解决方案,包括模板匹配、分词、词性标注、NER、句法树等中文模型。
接下来本节从模型的训练数据、特征两个方面介绍叮咚音箱分词。
叮咚音箱分词的训练数据大概有20万条标注数据,其中7万条来自于Chinese tree bank 8.0公开的测评数据,剩余的13万条数据是叮咚音箱场景下的数据,重点是购物、音乐、百科、闲聊场景下的语料。该部分数据采用人工标注的方法获得。
分词特征的设计是Stanford 分词工具包的一大亮点。它加入了大量的特征工程,既有离散特征也有连续特征。
离散特征包括:Char类型特征、各种Char类型的unigram/bigram特征;描述词性特点的特征:Unicode类型特征、Shape String类型特征;字典先验特征;以及以上各种特征的组合。
连续特征包括:字向量特征,word2vec预训练的字向量。
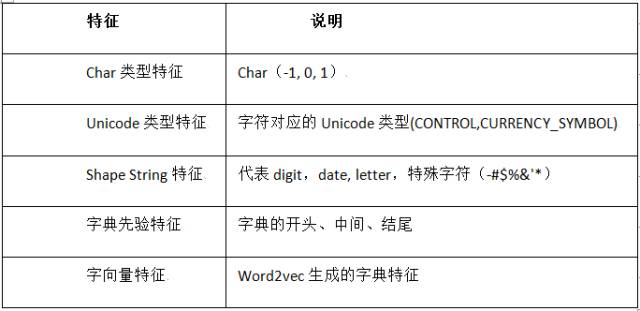
以下详细介绍各个类型特征:Char类型特征、字典先验特征。
Char类型特征举例:Char特征有unigram、bigram以及对应组合三种大类型特征。
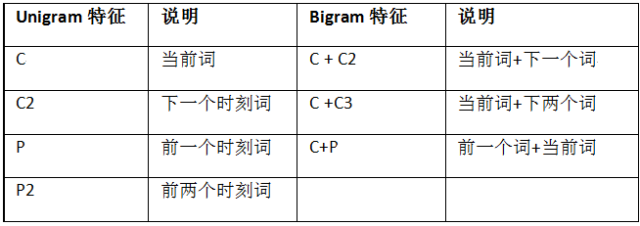
还是以“我要买小米手机”为例,在T4时刻“小”对应Char特征如下:
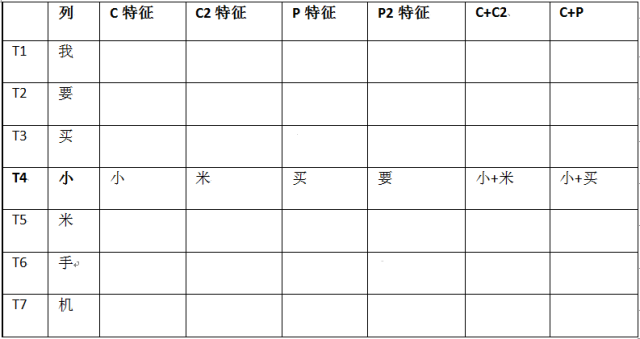
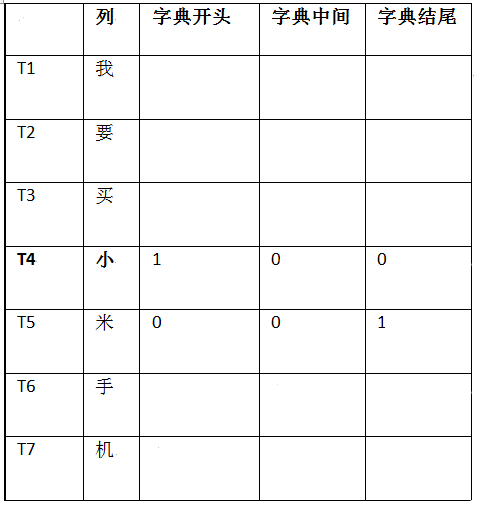
字典先验特征:该特征需要准备字典,通过字典先验知识来帮助分词模型更好地分词。字典先验特征主要包括某个char是字典的开头,中间还是结尾。
继续以“我要买小米手机”为例:
因为“小”和“米”组成的“小米”在字典中存在,且“小”是某个词的开头,“米”是某个词的结尾,所以在T4/T5时刻“小”“米”对应字典特征如下(1代表是、0代表非)
经过模型训练数据准备,添加模型特征后,我们训练了自己的分词模型。评测方法采用SIGHAN backoff2005提供的评测脚本工具进行评测。
以下是对各大分词系统在叮咚数据集上的评测结果(数值代表F1-score):
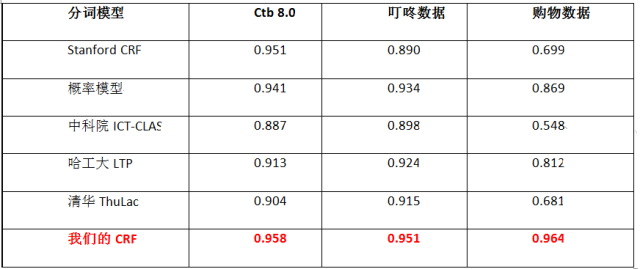
从上图中可以看到开源的中文分词模型在我们场景下的分词效果都不太好。这也是我们开发自己分词模型的原因。在人工标注的购物语料上我们的分词模型达到了0.964。
分词后处理
分词的后处理包括以下几部分:
• 处理外国人名。例如,乔治・华盛顿
• 处理时间, 比分等。 例如, 10:30, 3:0
• 处理百分比。 例如, 60%
• 处理小数点。 例如, 3.1415
• 处理千位分隔符。 例如, 1,000
强制分词
在使用分词模型时我们也会遇到一些分错的情况,为了及时地解决分词bad case,我们在分词后处理阶段加入强制分词功能。
强制分词是通过规则的方法将某几个词强制合并在一起或者将某个词强制拆分的一种分词方法。例如某个分词结果是“美 的 空调”,通过强制分词功能后我们的分词结果为“美的 空调”。强制分词的优点是可以快速准确的解决分词问题,但也存在覆盖率低的缺点。
以下是强制分词字典举例:
股票代码:我们可以把某几个字合并为一个分词结果。例如分词结果为“股票 代码”,强制分词结果为“股票代码”
强光 手电:我们也可以把某几个字分割为我们需要的分词结果。例如分词结果为“强光手电”,强制分词结果为“强光 手电”
以上就是叮咚音箱分词模型的简单介绍。该分词模型已经在线上使用,是叮咚音箱NLU自然语言理解模块中的一个重要组成部分。
接下来我们会从数据、特征、模型三方面考虑优化现有分词模型。
1.从深度和广度扩充分词标注数据。我们后续还会继续加入更多的标注数据,提高数据的覆盖度。同时现有20万的分词数据,只覆盖了购物、音乐、百科领域。后续还需继续扩充其他领域。
2. 特征工程在传统CRF模型中占有重要作用,后续我们会考虑加入更多分词特征,优化分词效果。
3.近几年深度学习方法在图像领域效果已经超过传统方法,后续我们会考虑将深度学习方法应用到分词应用中。希望通过端到端非特征工程的方法,深度学习分词模型效果能达到或者超越传统CRF分词模型。
高维国
资深算法工程师;2015年加入京东。主要从事自然语言处理相关工作:罗盘好评差评分析,query数量词识别,商品标题核心产品词识别及属性识别;为叮咚智能语言助手提供分词、词性标注模型以及指令百科意图分类等。


