上海科技大学ACL2018高分论文:混合高斯隐向量文法

作者丨赵彦鹏、张力文、屠可伟
单位丨上海科技大学
研究方向丨NLP、机器学习
自然语言处理领域的传统方法着重于处理离散符号之间的复杂结构,但近几年随着深度学习的兴起,出现了很多将符号向量化结合神经网络的方法。而将深度学习方法与传统 NLP 方法有机结合将会是自然语言处理领域未来的一个重要方向。
本文介绍了一篇来自于上海科技大学的 ACL 2018 论文“Gaussian Mixture Latent Vector Grammars”。该论文将传统的上下文无关文法与深度学习中的符号向量化思想相结合,提出了一种全新的“隐向量文法”,拓展了前人在文法向量化方面的工作,并获得了不错的实验效果。
该论文在 ACL 2018 审稿中获得了 6/5/5 的高分,是 ACL 2018 为数不多获得 6 分评审的长文。按 ACL 2018 的官方说明,6 分意味着审稿人认为这篇论文有可能改变整个领域并值得推荐最佳论文。据官方统计,ACL 2018 长文评审中仅有 0.4% 是 6 分,即总共只给出了约 12 个 6 分。
■ 论文 | Gaussian Mixture Latent Vector Grammars
■ 链接 | https://www.paperweekly.site/papers/2033
■ 源码 | https://github.com/zhaoyanpeng/lveg
背景
成分文法分析(Constituency Parsing)旨在得到句子的结构化表示,即得到句子所对应的语法树。语法树蕴含着一句话的生成过程,对于机器翻译、自然语言理解等任务大有裨益。
在成分文法分析中,最简单的模型是概率上下文无关文法(Probabilistic Context Free Grammars),但是这种模型假设文法规则的概率和其所在的上下文位置无关。因此,其在文法分析中表现效果很差。

为了提升文法分析精度,现有的方法尝试尽可能减弱上下文无关假设的错误影响。比较有代表性的方法有句法标注(Johnson. 1998; Klein et al. 2003),即在语法树中的句法类别上标注出其父节点或者兄弟节点的句法信息;词汇标注(Collins. 1997; Charniak. 2000),即在语法树中的句法类别上标注出其对应的句子成分的中心词。这些方法的基本思路是细化句法类别,但是受限于手动标注或者数据稀疏性问题。

因此,之后出现了自动学习细粒度句法类别的方法,即隐变量文法(Latent Variable Grammars (Matsuzaki et al. 2005; Petrov et al. 2007))。隐变量文法为每个句法类别关联一个离散隐变量,离散隐变量的取值表示具体的句法子类别,原始句法类别的子类别个数以及文法规则的参数可以通过最大似然的方法自动学习得到。但是这种模型对于每个原始句法类别,只能建模其有限个句法子类别。

最近,深度学习(Deep Learning)技术不断推动自然语言处理领域的发展。其中一个比较重要的方法是将离散的符号如单词、句法类别等赋予连续向量化的表示。这种向量化的表示能用于编码一个离散符号的上下文信息,精确地表示其句法功能和语义信息 ,从而能够量化不同符号之间的差异。
在成分文法分析领域,Socher et., 2011 & 2013 将 Recursive Neural Networks 扩展并用于文法分析任务,其思路即为使用连续向量来表示句法子类别,从而在文法分析中得以使用上下文信息,以此获得更好的文法分析精度。然而这些模型在文法分析中不能使用动态规划算法进行确切推理。

通过总结以上工作,我们发现不断细化句法类别,能够得到更加精确的文法分析精度。因此,我们希望得到一个能够建模尽可能多的句法子类别的文法分析模型。同时,受深度学习技术中离散符号向量化表示的启发,我们也希望能够借助连续向量来表示句法子类别。
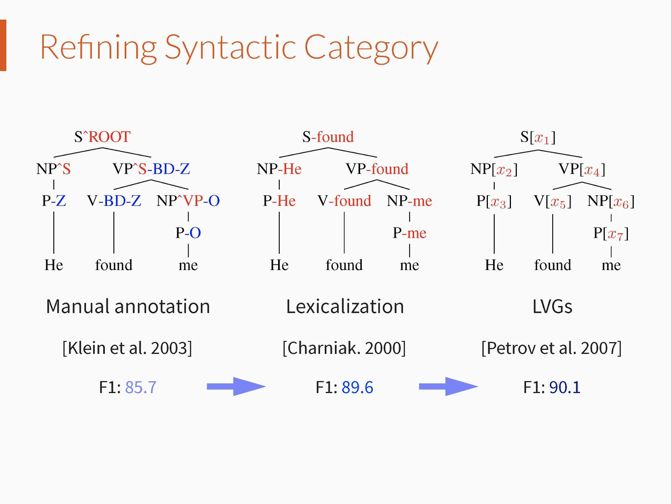
方法
我们提出隐向量文法(Latent Vector Grammars (LVeGs)),将传统的上下文无关文法和深度学习技术连接在一起。类比隐变量文法,隐向量文法为文法规则中的每个句法类别关联一个隐向量空间,用来表示其句法子类别的连续向量空间。
在这个连续向量空间中,每个向量代表一个句法子类别,因此 LVeGs 能够建模每个句法类别的无穷个句法子类别。需注意的是,在隐变量文法中,句法子类别构成的文法规则具有一个表示该规则概率的参数;而在隐向量文法中,句法子类别构成的文法规则具有一个表示该规则权重密度的参数。


可以证明,通过将隐变量文法中的离散变量取值转换为 One-hot Vectors,隐向量文法框架能够囊括隐变量文法,即隐变量文法可以看做是隐向量文法的一种特例。组合向量文法(Compositional Vector Grammars (Socher et al., 2011 & 2013))同样是赋予句法子类别连续向量化表示,我们能够证明该模型也是隐向量文法的一种特例。
隐变量文法用于文法分析是一个 NP-hard 问题。而由于隐变量文法是隐向量文法的一种特例,隐向量文法分析同样是 NP-hard 问题,因此只能借助近似求解的方法。比较常用的一种近似文法分析方法是 Max-Rule-Prod(Petrov et al., 2007),这种方法的求解目标是得到一个所有文法规则都正确的概率最大的语法树。
该方法的核心是对于输入语言,计算每个文法规则在每个可能的上下文位置的后验概率。为了能够高效的计算这些后验概率,我们将文法规则的权重密度函数定义为混合高斯分布,因为混合高斯分布具有在积分、乘法、加法运算上的闭合属性。我们称这种模型为混合高斯隐向量文法(Gaussian Mixture LVeGs)。
在这种定义下,对于每个文法规则,其权重密度函数的自变量为对应句法类别的子类别向量的串联。比如,对于文法规则 r: A -> B,权重密度函数为 W_r([a; b]),其中 a 为句法类别 A 的子类别向量,b 为句法类别 B 的子类别向量。文法规则的后验概率计算完毕之后,应用动态规划算法比如 CYK 算法可以高效地完成成分文法分析任务。


我们使用判别式学习方法 (Discriminative Learning)学习隐向量文法,即最大化给定输入句子的条件下正确语法树的条件概率。我们使用 Adam(Kingma et al., 2014)作为优化算法。在假设对角高斯分布的前提下,我们可以推导出梯度计算的闭式解。
实验中,我们通过成分文法分析和词性标注(Part-of-speech (POS) Tagging)两个任务验证隐向量文法的有效性。需要注意的是用于词性标注任务的隐马尔科夫模型(Hidden Markov Models)可以看做是上下文无关文法(Context Free Grammars)的一种特例,因此,隐向量文法模型同样适用于词性标注任务。在学习和推理中,由于隐向量文法模型目前尚未考虑句子成分或者词汇的上下文信息,因此为了公平对比,我们在实验中主要选择未应用上下文信息的文法分析模型作为对比模型。

我们首先在 POS Tagging 实验中对比了 Diagonal 和 Spherical 高斯分布的差异,实验结果表明这两种不同的设定对于模型性能的影响并不明显。而因为 Spherical 高斯的参数更少,我们主要以 Spherical 高斯设定下的 GM-LVeGs 为实验模型。
其次,我们在 Parsing 和 Tagging 两个任务中对比了不同类别的学习方法:生成式(Generative Learning)和判别式学习方法,实验表明 GM-LVeGs 总能取得更好的结果。
在 Parsing 实验中,我们把 GM-LVeGs 与组合向量文法模型和隐变量文法模型最好的系统实现 Berkeley Parser(Petrov and Klein, 2007)进行对比,实验结果显示 GM-LVeGs 同样优于这两类文法分析模型。
值得一提的是, 在标准测试集 WSJ(Penn Treebank WSJ)上,GM-LVeGs 在 F1 指标上高出 Berkeley Parser 0.92%。
总结
我们的工作主要有以下贡献。首先,我们提出隐向量文法模型(LVeGs)。其中每个句法类别关联一个隐向量空间,用来表示句法子类别的连续空间,因此 LVeGs 可以建模无穷多的句法子类别。我们证明隐变量文法和组合向量文法模型可以看做是 LVeGs 的特例。
其次,我们提出混合高斯隐向量文法模型(GM-LVeGs)。其中文法规则的权重密度函数定义为混合高斯分布,这样可以得到高效的推理和学习;我们在成分文法分析和词性标注任务上证明 GM-LVeGs 能够得到很好的结果。
我们的模型具有很多可以扩展的方向。比如在现有的设定中,每个文法规则的权重密度函数具有相同的高斯分量个数,未来可以尝试通过 Split、Merge 或者稀疏约束的方法自动决定每个文法规则的权重密度函数中高斯分量的个数。
另外一个扩展方向是将词汇和句子成分的上下文信息考虑进来,比如使用非对角高斯,或者通过神经网络模型来预测高斯参数。此外,也可以对所有句法类别的子类别空间使用一个相同的连续向量空间,这样可以将句法类别的差异性建模进来。
研究组招聘
上海科技大学信息学院屠可伟老师研究组主要从事自然语言处理、机器学习、知识表示等人工智能领域的研究,近两年已在 ACL、EMNLP、AAAI、ICCV 等顶级会议上发表了十多篇高水平论文。现招收硕士研究生、博士后和研究助理,欢迎对自然语言处理和机器学习有兴趣的同学联系屠老师。
更多信息请访问:
http://sist.shanghaitech.edu.cn/faculty/tukw/


关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文



