大会|惊喜与挑战并行的NSDI 2017

编者按
计算机网络系统领域顶级会议NSDI 2017于三月末在美国波士顿召开。会议结束之后,我们邀请了微软亚洲研究院的联合培养博士生肖文聪与我们分享了他的此次参会的心得体会。你还可能看过他此前分享的SoCC的参会体验。
会议简介
NSDI的全称是Networked Systems Design and Implementation,是USENIX旗下的旗舰会议之一,也是计算机网络系统领域久负盛名的顶级会议。与网络领域的另一顶会Sigcomm相比,NSDI更加侧重于网络系统的设计与实现,众所周知的大数据系统Spark就发表在2012年的NSDI大会上。
NSDI特别重视文章质量,会议采用严格的双盲评审,每篇文章都要经过两轮总计六到八个审稿人审阅,之后还需要经过程序委员会的讨论筛选。最后,今年的NSDI在投稿的两百多篇文章中收录了学术论文40篇,录取率为18%。
本届NSDI在美国波士顿举行,大会总共持续三天,分为13个session,从数据中心到无线网络,从安全隐私到异常检测,从存储系统到分布式计算,既有经典的网络问题负载均衡(Load balance)和调度(Scheduling),也有视频检测系统和分布式机器学习系统等新场景下的新问题,可以说是涵盖了网络系统研究的方方面面。每个session仅有三四篇文章,每篇文章都需要在大会上作近半小时的口头报告并接受提问。除了Oral环节外,第二天的晚上还设有一个单独的Poster session,总共录取了量少质优的22篇poster,展示了来自年轻PhD学生的很多新思路和新想法。

搭讪,演讲,被搭讪
早在我第一次去开会的时候,我的导师、微软亚洲研究院副院长周礼栋博士和我在研究院的指导老师(mentor)伍鸣就告诉我,开会最重要的是什么:交流!然而很多事情都是知易行难。我不禁回想起两年前我第一次参与国际学术会议的时候的尴尬,当时由于对自己英语口语和口音的不自信,即便是面对欢迎晚宴上坐在身旁的研究员,我也不知道该如何开口。我现在还记得,在我完成那年的暑期实习并从美国总部微软雷德蒙研究院离职的那天,我的指导老师还分享给我不少经验,其中之一就是关于语言交流的问题。因为英语并不是我们的母语,我们在与别人的交流中存在着理解上的偏差是很经常出现的,不断训练自己提升语言能力当然重要,但更重要的是要永远保持耐心,去倾听、理解、询问,为达到一致的理解(context)去不断尝试沟通和表达自己。仔细回想,算上大四那年,我已经在微软亚洲研究院的系统组实习快4年了,几乎每个研究员都在科研上给予过我帮助,而组里轻松而扎实的学术氛围,坚持科研与产品相结合的实践方法更是深深影响了我。我何其荣幸能得到这么多人孜孜不倦的教诲,点点滴滴只能牢记于心,不断践行。这次的大会上,我在茶歇期间成功搭讪了好几位优秀学者并与Poster 环节超过一半的人都进行了交流,相比于上次,也算是小有进步。

系统组参会人员合照
实际上开会聊天是很高效的交流手段,而吃饭时间更是极好的沟通的机会。如果遇到一些年长的研究员,他们经常会分享一些高层次的对于研究方向和领域发展的思考,甚至是一些人生经验。如果遇到跟自己相关领域的论文的作者,那么就很容易能聊到论文新方法下的一些细节问题,其实透过作者读论文往往是最快的方法!众所周知,很多国际顶级学术会议涉及领域的范围很广,就拿NSDI来说,网络系统领域的研究跨度很大,而近几年交叉领域的新工作也比较多,聊天时经常会遇到自己可能还没接触到的研究面,这时候与同行的交流经常能脑洞大开,相互激发新想法。这次的NSDI恰好是在学术重镇波士顿举行,波士顿周围汇聚了很多著名的高校,包括著名的麻省理工学院(MIT)和哈佛大学。这带来的一个好处就是参会的人不只有网络系统相关的研究员和论文作者,更有不少来自这些高校的PhD们,他们使参会人员更加多元化。俗话说的好,他山之石可以攻玉,很多前瞻性的文章和新颖的方法就是在这样的跨界交流中提炼的。
这是我第二次参加国际学术会议,而不同于以往,这次我需要在大会上就自己的工作做近半小时的口头报告。这里要非常感谢我在微软亚洲研究院系统组的同事们,从PPT到演讲内容他们都帮我进行了细致的修改,还安排了三次的排练并教会我很多演讲上的技巧。
尽管是早有准备,但我在前往波士顿的飞机上却还是愈发的紧张和焦虑。然而就在当我刚到会场进行注册的时候,我遇到了去年暑期在雷德蒙研究院实习时认识的研究员Amar,他的一句“温控 ”(在英语使用者看来我的名字Wencong是应该这么发音) 和爽朗的笑声把我的思绪从阴冷的波士顿带回了美丽的西雅图的夏天,到那个大家都非常努力非常有爱的99号楼,一切的紧张和压抑瞬间得到了缓解。当我站上演讲台之后,与其说有那么点紧张更不如说是一种兴奋,看着下面目光灼灼的“同学们”,我觉得自己更像一个传播知识的老师,责任重大。
在完成了演讲之后的茶歇,一位不认识的研究员突然跑过来,我看了一下名牌才发现,竟是大名鼎鼎的PowerGraph和GraphX的作者Joseph!他称赞了我们的工作,并分享了他的一些相关的思考,包括系统设计层面以及机器学习等。我非常开心自己的工作得到了肯定,通过自己的一些微小的工作,能让大家在分布式系统的设计实现上看到一个新的方法,有一些新的启发,我很自豪也很满足。
焦点透视
下面我将从获奖论文、微软Azure的重磅工作、数据中心研究、以及机器学习相关系统4个方面介绍一些NSDI上的论文。
获奖论文
本届NSDI共颁发了两个奖项,Community Award(社区贡献奖)和Best Paper Award(最佳论文奖)。其中Community Award被Dropbox斩获,而来自Korea Advanced Institute of Science and Technology (KAIST) 的mOS则在众多欧美名校的顶级网络系统工作中脱颖而出,摘得了唯一的Best Paper Award!
Dropbox在论文The Design, Implementation, and Deployment of a System to Transparently Compress Hundreds of Petabytes of Image Files for a File-Storage Service中介绍了他们的图像数据压缩系统Lapton【1】,已经部署在Dropbox这样一个世界范围的云存储系统中,可以无损压缩JPEG图像文件到原来大小的77%。截至到2017年1月,已经压缩高达数百个PB的数据,节省了46PB的存储空间。这个系统已经在Github进行了开源。
KAIST的mOS则主要解决带有状态的网络数据流层面的MiddleBox的编程可重用性问题。MiddleBox是指网络中部署的带有除了包转发以外功能的系统,比如说防火墙就是一个常见的MiddleBox应用,用于过滤未经许可的网络流量。电信系统中对于蜂窝数据流量的计算和实时监控也是另外一个典型的MiddleBox应用。实现MiddleBox应用通常需要对于每个连接的数据包和状态进行监控和处理,从而需要自己实现很多相应的包转发等功能,KAIST的研究员提出了一套高层次编程接口,使得用户只需要专注于实现MiddleBox的应用,隐藏了底层数据流处理的逻辑,避免了复杂而易错的数据流管理部分的重复性编程。而在底层,mOS通过一个高效而灵活的事件系统,支持百万量级并发流事件的处理。mOS系统已经在Github上开源,相信会给MiddleBox的研究和产品带来诸多的便利。
微软Azure的重磅工作
微软在这样一个网络系统领域的盛会中继续保持着自己的重量级地位,参与了总共40篇文章中的9篇文章的工作,为工业界之最,表现抢眼。而微软的研究员也在本届NSDI的多个session中担任主席。在近几年的网络系统研究中,一方面微软研究院不仅自己发表研究文章,并且还联合其他多个科研机构以及其学生合作发表了多篇研究文章,另一方面微软的产品部门Azure也不断发表文章介绍了他们在实际生产环境中的先进工作和经验。
Azure云服务是世界上最大的公有云服务之一,微软Azure的数据中心散布在世界各地,包含高达百万量级的机器数目。Azure把虚拟机卖给客户,需要给虚拟机的网络提供防火墙、负载均衡等网络功能,鉴于此,微软的Azure team在数据中心设计中大规模实践SDN。
在本届NSDI的SDN and Network Design session,微软Azure数据中心负责Host SDN team的Daniel Firestone介绍了他们长达8年的Host SDN的项目经验,披露了核心系统——Virtual Filtering Platform (VFP) 【3】这样一个端系统上的可编程端虚拟交换机的设计和实现细节。VFP已经部署在超过一百万台的Azure服务器上,稳定的支持IaaS和PaaS的服务长达4年的时间。
第一阶段的VFP项目着重在可编程性上,允许不同用户能独立的编写网络策略而不相互影响,并且支持网络连接层面的状态化信息,还能够编写灵活的网络策略。
第二阶段的VFP项目则着重关注在可维护性和性能两个层面,一方面提供热部署的功能,另一方面在基于FPGA 实现的SmartNIC的支持下,通过Unified Flow Table设计和Hardware Offloads,使得VFP在保持最开始的灵活软件定义的特性下,能够高效的支持40Gbps和50Gbps的高速数据中心网络。进一步的,SmartNIC对每个服务器上运行着的虚拟机抽象出一块虚拟网卡,虚拟机通过SR-IOV技术即可直接访问这块虚拟网卡,使得虚拟机收发网络数据包都不需要CPU计算单元的参与,做到了CPU-bypass,既节省了CPU资源又降低了网络延迟,并且更具经济性。

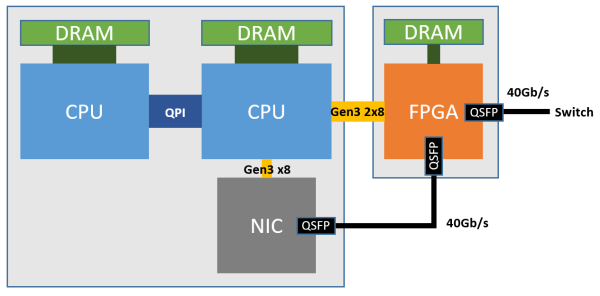
在如今的Azure数据中心中,正如下图所示,每一台服务器上都插上了一块FPGA,部署在本机网卡与外部网路之间,并通过PCIe连接到服务器上,FPGA 之间通过 LTL (Lightweight Transport Layer) 通信,在微秒级别的时间内就可以到达数据中心内任何的FPGA,真正做到了低延迟高带宽。这样一种部署的方式和软硬件协同设计的方法让FPGA从CPU中接手网络功能并进一步加速了SDN,使得Host SDN得以在如今的高带宽数据中心网络中部署。软件定义网络以这样一种全新的方式与硬件相融合,兼具灵活性与高效性。
持续火爆的数据中心研究
数据中心的研究一直是NSDI上的焦点,很多的工作都围绕着数据中心的网络来展开。
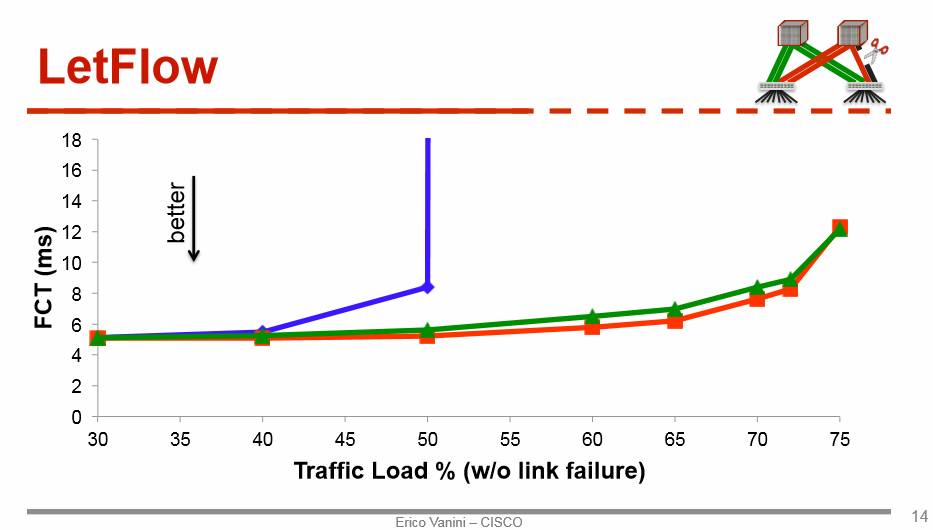
负载均衡(Load balance)和拥塞控制(Congestion control)一直是数据中心网络中的经典问题。在14年的Sigcomm上,思科发表了CONGA,在如今看来仍然是state-of-art的congestion-aware load balance机制,在今年的NSDI上,他们又卷土重来,在文章Let it flow【4】中提出了一个非常简单的负载均衡方法,延续了他们在CONGA里面的思路:与其在每个数据包上做负载均衡,不如考虑在Flowlet的粒度上做。这里的Flowlet可以认为是以时间维度来切分的批量网络包。其简洁的新负载均衡算法,一言以蔽之,即只要随机的安排Flowlet到可用的网络路径上即可均衡流量。这种看似随机的做法其实却能非常好的感知网络拥堵,从而做到负载均衡。这一做法的深层次原因在于:在拥塞严重的路径上,Flowlet的大小会降低,而在通畅的路径上,Flowlet的大小会增长。这一机制(下图绿色) 比现有的很多流量均衡方法都有显著优势,而比起复杂的机制CONGA(下图红色),也只有10~20%的差别。
在另一个工作Flowtune【5】中,MIT的研究员则关注网络带宽分配的收敛速度问题。在数据中心网络中,网络管理者会事先基于不同的策略定义优化的目标,把网络的带宽迅速的分给当前的数据流。这个优化目标是事先定义好的,比如说可以是流之间公平性(Fairness)或者流完成时间(FCT)。传统的网络带宽分配这方面工作基本都是基于数据包(packet)这个粒度,收敛到目标状态所需要的时间相对较长。这篇文章提出按照Flowlet的粒度来分配网络带宽,每一个Flowlet都由一个中心化的控制器来决定发送速率。这里面关键的问题是如何快速计算出收敛到的最优速率,针对这一挑战,他们提出了一个新的Newton-Exact-Diagonal方法来解决这个问题,并且设计实现了一个在CPU上的多核并行可扩展的系统。
机器学习和网络系统
随着机器学习和人工智能系统的迅速发展,以及这些技术在生产环境中的大规模应用,很多网络系统的工作开始研究如何针对性的优化这些新应用。这届的NSDI大会上涌现出了不少跟机器学习相关的文章,研究员们并不只停留于设计实现网络系统来为机器学习算法应用服务,还有更多的学者将机器学习方法应用到网络系统的实际问题之中,而这个角度的工作相对来说是比较少的,十分令人欣喜。
Curator【6】是华盛顿大学和Nutanix合作的系统,它是一个部署在后端的MapReduce-style的框架,用于处理存储系统中的后台任务,比如说磁盘碎片整理,冷热数据搬运,备份数据等。论文介绍了他们多年来在分布式存储系统设计上的经验。值得一提的是,他们提出了用强化学习的方法来去确定SSD和HDD中分别存储的数据量,并称相较于经验性的阈值策略方法会降低20%的延迟。
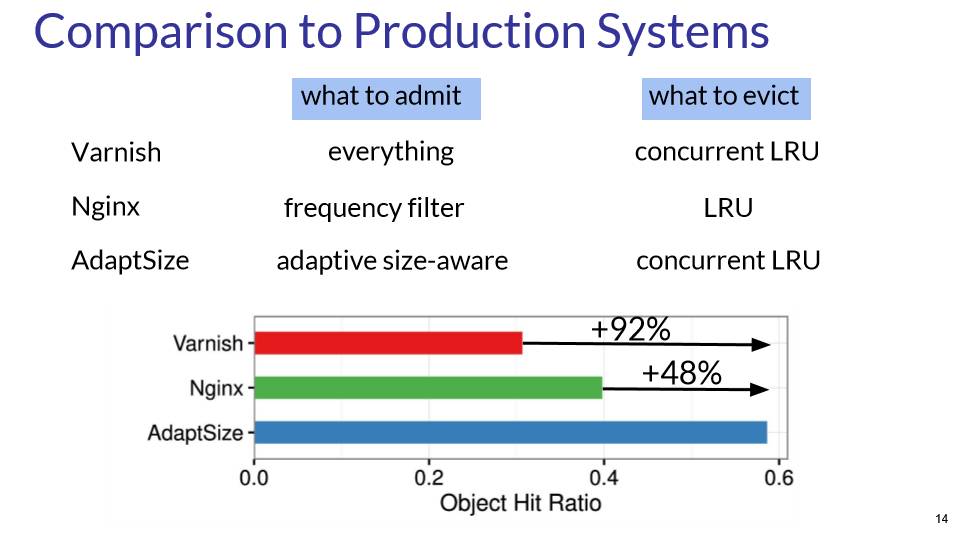
无独有偶,这种动态阈值的思想在这届NSDI大会中关于内容分发网络(CDN)相关的工作AdaptSize【7】也得到了体现。CDN是一种节点散落在不同地理位置的大规模分布式系统。举例来说,很多网络应用中需要的资源,例如视频和图片等这样的静态资源,就可以预先缓存在就近的节点上。当用户请求数据时,CDN系统根据网络状态的实际情况重定向用户请求到就近节点上,以方便用户的访问。这样既减轻核心服务器的负载压力,又降低了获取资源的延迟,提高了用户体验。在CDN上,一般会区分冷热数据,把用户经常访问的热数据 (Hot object) 放在内存这样的低访问延迟的存储模块中,而剩下的放在磁盘中,这样内存中的热数据就构成一个缓存。这里最关键的问题就是,什么样的数据需要放进内存,现有的做法无非是把全部都放进去然后根据访问频率把低频的踢出,或者是基于一个阈值把小数据放进去,毕竟小数据更加划算。这篇文章采用一个马尔可夫模型,根据请求的模式 (Request pattern) 自动调节相应阈值决定缓存的文件大小,进而获得更好的缓存命中率。这个论文的结果非常的令人振奋,相比于现有的其他方法有近20个百分点的提升!
不只是CDN,这种方法很容易应用到其他的相似场景,即上层有复杂而多变的数据访问模式(Access pattern)的带有缓存的系统。
更进一步的说,在系统中引入机器学习方法来代替固定的阈值,我认为是一个相对通用的方法,并且这种方法有可能在很多情况下都会有好处。系统或者网络本身也许能学习感知到上层不同应用不同的数据访问模式,从而自适应其特性,调整到更加合适的配置之下。然而这又为系统本身增加了复杂性和不确定性,毕竟稳定性、简单可靠、乃至可复现是基础设施平台一直以来的追求。所以说,这并不是放诸四海皆准的灵丹妙药,但是也是一个很有趣的新思路。
CherryPick【8】是来自耶鲁和微软等四个机构的多方合作项目,其研究关注在云系统的调度层面,一个云端服务可以应用不同的系统配置。然而,为了达到相同的性能,不同的配置可能会导致高达12倍乃至更多的成本耗费上的差别,这一点在重复性作业 (recurring job) 上显得尤为突出。自动的在低搜索空间下为云端服务找到最优配置所带来的经济性自然是不言而喻。文章使用了一个简单的贝叶斯优化 (Bayesian Optimization) 来帮助优化搜索过程,决策搜索哪个配置下的运行性能,以及什么时候停止搜索以找到最优的系统配置。我觉得这个工作建模的系统指标项还是相对来说比较简单的,仅考虑任务占用的VM、CPU、内存、磁盘、网络等静态系统指标,并不考虑数据、系统当前总资源占用、任务间的相互干扰之类的当前整个系统状态相关的问题。其使用简单模型针对这一特定问题固然有其好处,但是不一定适合更加复杂的情况。正如Google曾透露他们已经试图用强化学习优化一些调度问题一样,我相信机器学习在系统领域应用的研究才刚刚开始。采用数据驱动的方法,通过对于数据的分析和问题的建模,可以帮助我们加深对于复杂系统的理解,减少乃至避免经验性的阈值和静态配置,而这些新的方法论最终将反过来影响网络系统的设计。
VideoStorm【9】是普林斯顿的Haoyu在微软研究院实习的时候做的工作。随着DNN在图像视频领域的物体识别追踪上的不断发展,利用这一方法实时的分析监控摄像头的数据,完成如车辆追踪这样的人工智能任务已成为现实的需求。这篇文章针对这样一个典型的人工智能应用,探讨在给定资源下,综合考虑多种视频流任务的不同质量和不同延迟这一需求,如何分配云端资源来同时处理成千上万个视频流数据任务的方法。这个系统已经在美国华盛顿州的贝尔维尤市完成部署,为实时交通数据的分析服务。这个实际的问题是深度学习从理论走向实践的过程中会遭遇的现实挑战,随着更多这种应用的部署,相关的网络系统都蕴含着更多类似的新研究机会。
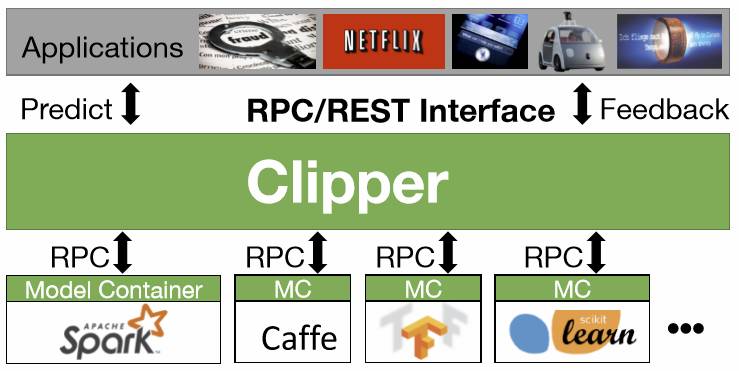
Big Data session中的四篇文章有三篇跟机器学习相关,第一篇是来自于伯克利RICE实验室,其前身是AMPLab,其产出不止包括有影响力的论文,更是有影响力的开源项目和创业公司,由Databricks公司主导的Spark项目已经在大数据领域发展出繁荣的生态链。而在这次的NSDI上,他们发表了Clipper【10】系统。这是一个以通用性和低延迟为目标的机器学习服务(serving) 系统,对用户端提供统一的接口,而底层则适配多种框架,包括 Spark MLlib,Caffe,Tensorflow,Scikit-Learn等,从而简化这种服务系统的部署工作。Clipper系统通过应用缓存(caching),批处理(batching),以及自适应模型选择(adaptive model selection)来优化延迟,提高吞吐率、准确率、和鲁棒性。在当前机器学习技术广泛应用,深度学习框架繁荣发展的现状下,Clipper携Spark在大数据系统上的领先地位和MLlib,试图用一个前端框架一统model serving部分,可以说是雄心勃勃。然而不同于大数据时代,如今深度学习有更多的底层框架,比如说CNTK和MXNet,也更加依赖异构的硬件平台,比如说GPU、FPGA和以Google的TPU为代表的ASIC,以及计算密集型应用要求对于性能上的极致压榨,这些都为大一统平台带来了更多的挑战。这次他们能否成功,我们将拭目以待。
第二篇则是来自CMU的Gaia【11】,讨论如何设计系统来对基于全球分布(geo-distributed)的机器学习数据进行训练。现在很多全球化的服务,比如说搜索引擎,都是部署在世界各地的数据中心中就近服务世界各地的用户。数据中心内部一般都部署有低延迟高带宽的网络,而数据中心间的互联网(WANs)则可能很慢,直接在不同数据中心间的数据上训练机器学习模型,其训练过程会严重受限于数据中心间的网络,文章报告了高达53x的性能下降。这个工作通过解耦数据中心内部和外部的同步模型来优化性能,提出了一个新的一致性模型 (Approximate Synchronous Parallel) 来进一步的减少数据中心间的网络通信,并且保持机器学习模型的收敛率。这个工作和Google日前宣布的Federated Learning的工作都是旨在考虑互联网范围内机器学习模型的训练问题,后者将训练数据分散到成千上万的用户手机中,协同训练机器模型以提升模型质量,降低延迟。一方面数据中心间乃至普通互联网中的网络存在带宽低、延迟高、不稳定等问题,另一方面机器学习模型又具有一定程度的容忍错误和延迟更新的特性,这涉及到网络和机器学习算法的协同设计(co-design)的问题,非常的有趣。
第三篇是我们的工作TuX²(图学习)【12】,是一个为分布式机器学习设计的全新图计算引擎。
图计算是一个经典的问题,很多的图计算系统都专注为诸如PageRank这样的经典图计算问题优化,提供简单而并行无关的编程模型,并且可以在系统内部感知图结构进行系统层面优化,从而高性能地进行横向扩展,支持海量数据。我们的上一个工作,被录取在SoCC’15上的GraM【13】已经可以高效支持高达万亿(trillion)边数的超大规模图计算。
基于我们对于机器学习应用的思考,我们发现多种重要的机器学习算法都有内在的图结构模型。然而与图计算算法不同,机器学习算法并不是很适合用现有的图计算引擎来处理,原因可以分为两个层面,其一是缺乏对于重要机器学习概念的支持,例如小分批(mini-batch)和宽松的一致性模型,其二原有图模型过于简单并且在模型抽象上灵活性过低,从而为机器学习算法编程和高效执行都带来了问题。
有鉴于此,为了利用图计算的优势同时又解决上述的问题,我们提出了分布式机器学习系统——图学习TuX2 (Tu Xue Xi)。TuX2相比于传统的图计算引擎,在数据模型、调度模型、编程模型三个方面都做了关键的扩展,全新的图模型MEGA更是使得分布式图计算引擎在保持原有的高效性的同时拥有更多的灵活性,支持Mini-Batch和灵活一致性模型等关键的机器学习概念,并且更适合编写复杂的机器学习算法。

性能方面, 在高达640亿条边的大规模数据上的实验充分说明,TuX2相比当前最好的图计算引擎PowerGraph和PowerLyra都取得了超过一个数量级上的性能提升,这一成绩背后离不开我们的异质性(heterogeneity)图节点优化和新编程模型MEGA。而对比现有的两大机器学习系统,Petuum和ParameterServer,TuX2在大幅度减少代码量的同时带来了至少48%的性能提升,这主要是因为我们的图编程模型MEGA的高层次抽象以及图计算系统基于图结构优化。
要知道,大规模分布式机器学习模型的训练成为很多产品线的重要部分并且耗时良久,我们系统显著的性能提升(Efficiency)有效的节省了计算资源,而其扩展性(scalability)使得支持更大规模的数据成为可能。
我们的愿景是希望TuX2能够真正连接图计算和分布式机器学习两个研究领域,让更多的机器学习算法和优化能够很简单的在图计算引擎上实现,从而利用好众多的图结构优化技术来进行系统层面的优化,将两个领域的研究工作更好的结合在一起,为人工智能的未来服务。

肖文聪,本科毕业于北京航空航天大学计算机学院,2014年加入北京航空航天大学与微软亚洲研究院的联合培养博士生项目,导师是北航的李未院士和微软亚洲研究院副院长周礼栋博士。研究方向是大规模分布式图计算和机器学习系统。
相关论文:
【1】Lapton:The Design, Implementation, and Deployment of a System to Transparently Compress Hundreds of Petabytes of Image Files for a File-Storage Service
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/horn
【2】mOS: A Reusable Networking Stack for Flow Monitoring Middleboxes
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/jamshed
【3】VFP: A Virtual Switch Platform for Host SDN in the Public Cloud
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/firestone
【4】Let It Flow: Resilient Asymmetric Load Balancing with Flowlet Switching
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/vanini
【5】Flowtune: Flowlet Control for Datacenter Networks
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/perry
【6】Curator: Self-Managing Storage for Enterprise Clusters
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/cano
【7】AdaptSize: Orchestrating the Hot Object Memory Cache in a Content Delivery Network
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/berger
【8】CherryPick: Adaptively Unearthing the Best Cloud Configurations for Big Data Analytics
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/alipourfard
【9】VideoStorm:Live Video Analytics at Scale with Approximation and Delay-Tolerance
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/zhang
【10】Clipper: A Low-Latency Online Prediction Serving System
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/crankshaw
【11】Gaia: Geo-Distributed Machine Learning Approaching LAN Speeds
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/hsieh
【12】Tux²: Distributed Graph Computation for Machine Learning
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/xiao
【13】GraM: scaling graph computation to the trillions
http://dl.acm.org/citation.cfm?id=2806849&CFID=926649994&CFTOKEN=39893429
你也许还想看:
引领风骚,对话未来——WWW2017参会有感
回顾AAAI|如何参加国际顶级人工智能大会?
AAAI |如何保证人工智能系统的准确性?
大会|NIPS 2016:机器学习的盛典
大会|CIKM 2016:大数据科学的前沿与应用







