ImageNet识别率一次提高1%:谷歌AI新突破引Jeff Dean点赞
选自arxiv
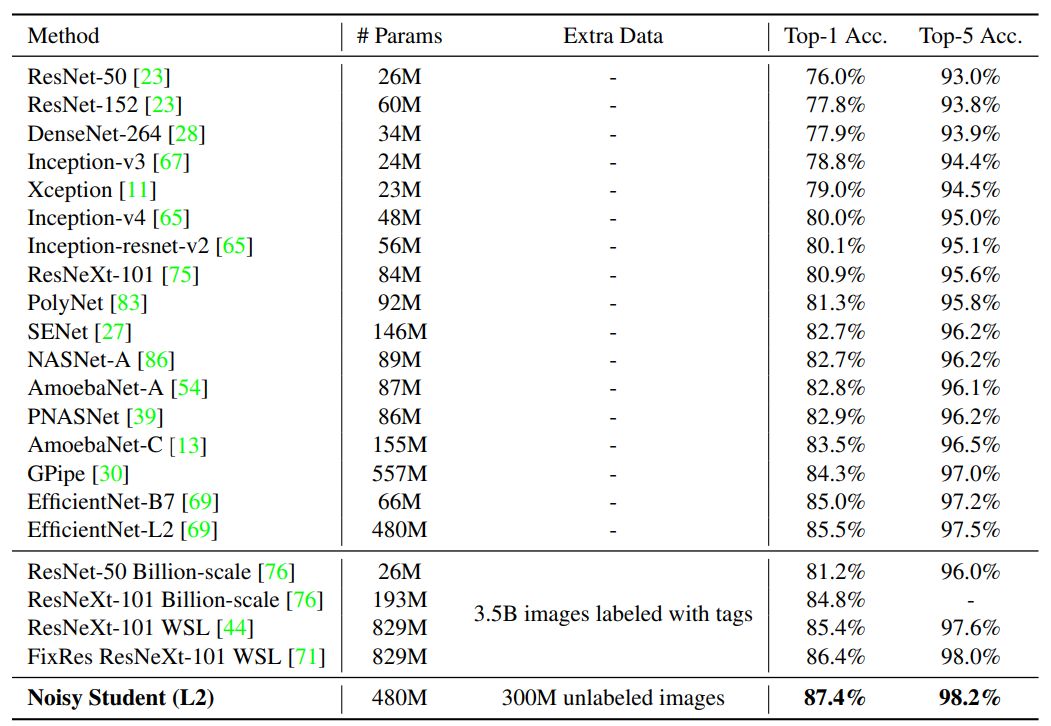
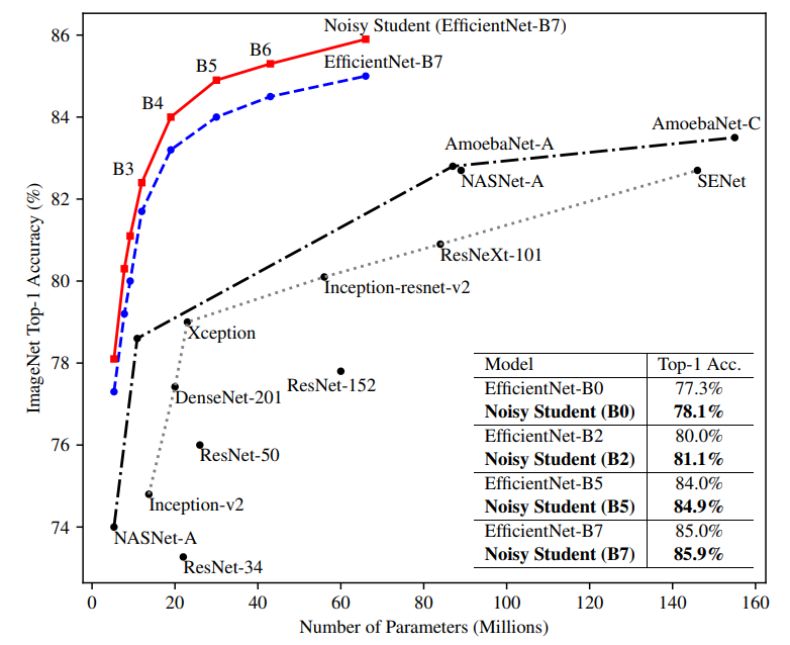
ImageNet 上的图像分类模型似乎已经成熟,要达到新的 SOTA 已经非常难。 近日,Quoc Le 等提出了一个新的方法,在这一数据集上再次提高了 SOTA 性能一个点。 而且这一方法让模型在鲁棒性上也有很大的提升。
论文地址:https://arxiv.org/abs/1911.04252

1)在标注图像上训练一个教师模型;
2)利用该教师模型在未标注图像上生成伪标签(pseudo label);
3)在标注和伪标注混合图像上训练一个学生模型。最后,通过将学生模型当做教师模型,研究者对算法进行了几次迭代,以生成新的伪标签和训练新的学生模型。
研究者表示,实验说明,一项重要的方法是,学生模型在训练中应当被噪声干扰,而教师模型在生成伪标签的时候不需要。这样,伪标签能够尽可能逼真,而学生模型则在训练中更加困难。
为了干扰学生模型,研究者使用了 dropout、数据增强和随机深度几种方法。为了在 ImageNet 上实现稳健的结果,学生模型也需要变得很大,特别是要比普通的视觉模型大很多,这样它才能处理大量的无标注数据。


研究者首先利用标准交叉熵损失和标注图像来训练老师模型。然后,他们使用该老师模型在未标注图像上生成伪标签。这些伪标签既可以是柔性的(连续分布),也可以是硬性的(onehot 分布)。接着,研究者训练学生模型,该模型最小化标注和未标注图像上的联合交叉熵损失。最后,通过将学生和老师模型的位置互换,他们对训练过程进行了几次迭代,以生成新的伪标签和训练新的学生模型。
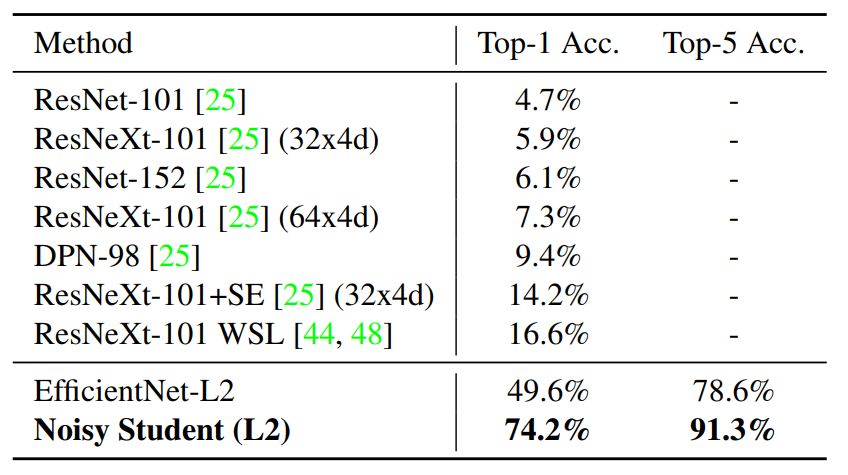
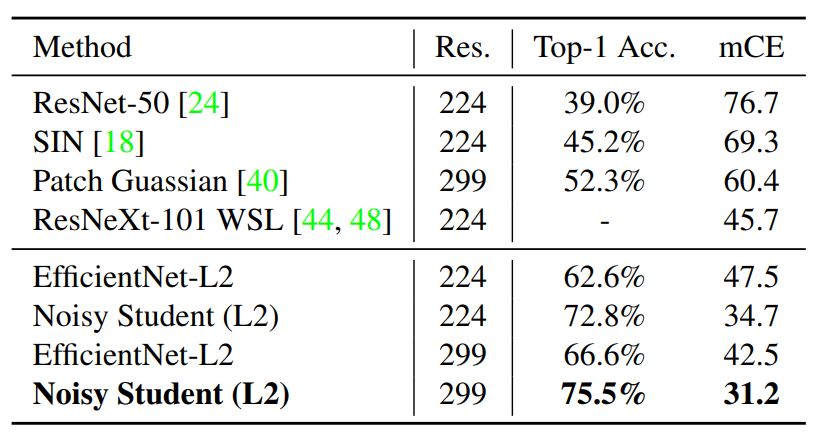
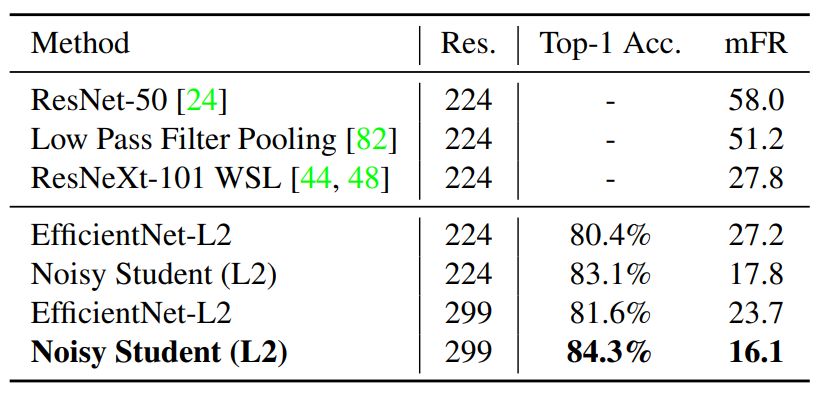
在这一部分中,研究者描述了实验的各种细节与实现的结果。他们展示了新方法在 ImageNet 上的效果,并对比了此前效果最佳的模型。此外,研究者还重点展示了新方法在鲁棒性数据集上的卓越表现,即在 ImageNet-A、C 和 P 测试集,以及在对抗样本上的鲁棒性。


登录查看更多
相关内容

ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别; [2]一个典型的类别,如“气球”或“草莓”,包含数百个图像。第三方图像URL的注释数据库可以直接从ImageNet免费获得;但是,实际的图像不属于ImageNet。自2010年以来,ImageNet项目每年举办一次软件比赛,即ImageNet大规模视觉识别挑战赛(ILSVRC),软件程序竞相正确分类检测物体和场景。 ImageNet挑战使用了一个“修剪”的1000个非重叠类的列表。2012年在解决ImageNet挑战方面取得了巨大的突破,被广泛认为是2010年的深度学习革命的开始。
Arxiv
3+阅读 · 2018年8月2日
Arxiv
5+阅读 · 2018年1月17日


相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年8月2日
Arxiv
5+阅读 · 2018年1月17日