
题目: Smooth Adversarial Training
摘要:
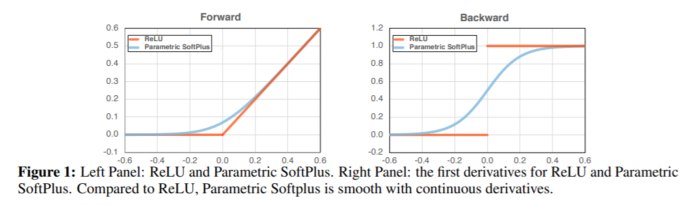
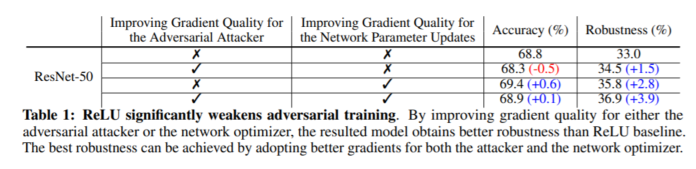
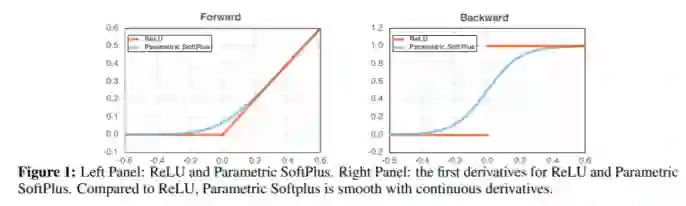
人们通常认为,网络不能兼具准确性和鲁棒性,获得鲁棒性意味着失去准确性。还普遍认为,除非扩大网络规模,否则网络架构元素对提高对抗性的健壮性影响不大。本文通过对对抗训练的仔细研究,提出了挑战这些共同信念的证据。主要观察结果是,广泛使用的ReLU激活功能由于其不平滑的特性而大大削弱了对抗训练。因此,提出了平滑对抗训练(SAT),在其中我们用ReLU平滑近似代替了ReLU,以加强对抗训练。SAT中平滑激活函数的目的是使它能够找到更难的对抗示例,并在对抗训练期间计算出更好的梯度更新。与标准的对抗训练相比,SAT提高了“free”的对抗鲁棒性,即准确性没有降低,计算成本也没有增加。例如,在不引入其他计算的情况下,SAT可将ResNet-50的鲁棒性从33.0%提高到42.3%,同时还将ImageNet的准确性提高0.9%。SAT在较大的网络上也能很好地工作:它可以帮助EfficientNet-L1在ImageNet上实现82.2%的准确性和58.6%的鲁棒性,在准确性和鲁棒性方面分别比以前的最新防御提高9.5%和11.6%。
成为VIP会员查看完整内容
相关内容
专知会员服务
36+阅读 · 2019年11月12日

相关VIP内容
专知会员服务
36+阅读 · 2019年11月12日
相关资讯
相关论文