何恺明最新一作论文:无监督胜有监督,迁移学习无压力,刷新7项检测分割任务
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
何恺明的一作论文,又刷新了7项分割检测任务。
这一次,涉及的是无监督表征学习。这一方法广泛应用在NLP领域,但尚未在计算机视觉中引起注意。
Facebook AI研究院的何恺明团队受此启发,采用对比损失(constrative loss)法,即从图像数据中采样键(或令牌),并由经过训练、与字典相匹配的编码器表征。
新的方法,名叫MoCo(Momentum Contrast)。其预训练模型经过微调可以迁移到不同的任务上。

在ImageNet、CoCo等数据集上,MoCo甚至在某些情况下大大超越了监督预训练模型。
研究团队表示:
这表明,在许多视觉任务中,无监督和有监督的表征学习之间的鸿沟已经大大消除。
方法原理
那么,MoCo究竟是怎么实现的呢?
像查字典一样的对比学习
对比学习(constrastive learning),可以看做是在训练编码器来完成字典查找任务。
假设字典中有一个与编码查询(query)相匹配的键(key,表示为k+)。对比损失函数中,当查询与k+相似,且与所有其他键不同时,函数值较低。
在这篇论文中,研究人员采用的对比损失函数如下:
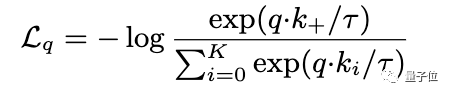
这是一种无监督目标函数,用来训练表征查询和键的编码器网络。
动量对比(MoCo)
用一句话来说,对比学习就是一种在高连续性输入(如图像)上构建离散字典的方法。
MoCo方法的核心,是将上述字典作为数据样本队列来进行维护,这样一来,字典就能重复使用已编码的键,字典就可以比通常更大,并且可以灵活地、独立地设置为超参数。
这是一本动态字典,其样本会逐渐被替换,但始终代表着所有数据的抽样子集。
其次,需要考虑的是更新编码器的问题。
使用队列可以让字典变大,但也会让通过反向传播来更新键编码器这件事变得更困难。
研究人员假设这种困难是编码器的快速变化降低了键的表征一致性所造成的,于是,他们提出了动量更新的方法。
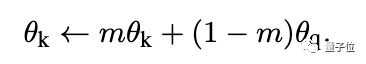
在这个公式中,只有θq是通过反向传播更新的。动量更新会使得θk的演化比θq更加平稳。
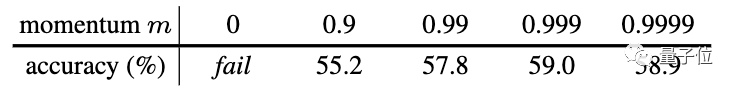
在实验中,研究人员还发现,相对较大的动量(m=0.999)会比较小的动量(m=0.9)要好得多。这表明缓慢演变的键编码器是利用队列的关键所在。
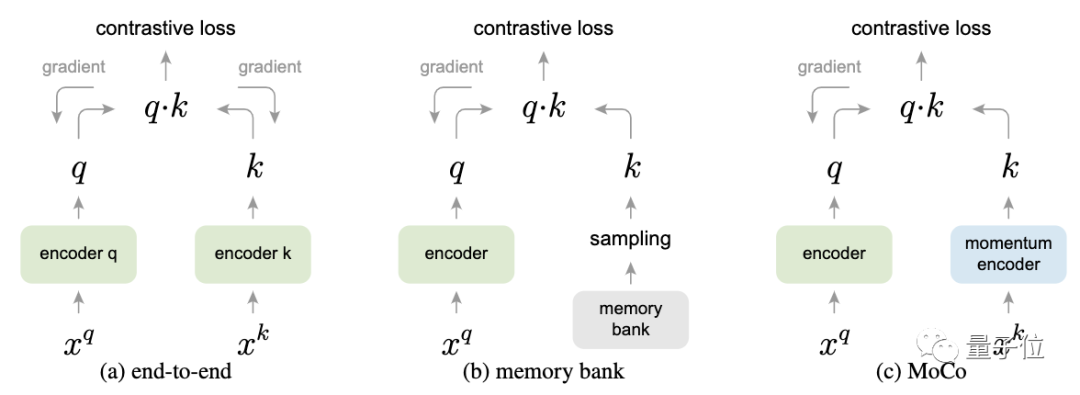
△三种不同对比损失机制,仅展示一对查询和键的关系
从这张图中,可以看到三种不同对比损失机制的不同。
端到端方法,是通过反向传播对计算查询和键的表征进行端到端更新。
Memory bank方法中,键的表征是从存储库中提取的。
而MoCo方法则通过基于动量更新的编码器对键进行动态编码,并维持键的队列。
实验结果
MoCo的表现究竟如何,还是要用数据说话。
研究团队在ImageNet-1M和Instagram-1B这两个数据集上进行了测试。
ImageNet-1M是ImageNet的训练集,包含1000种不同类别的128万张图片。而Instagram-1B数据集则包含10亿(940M)Instagram上的公开图像。
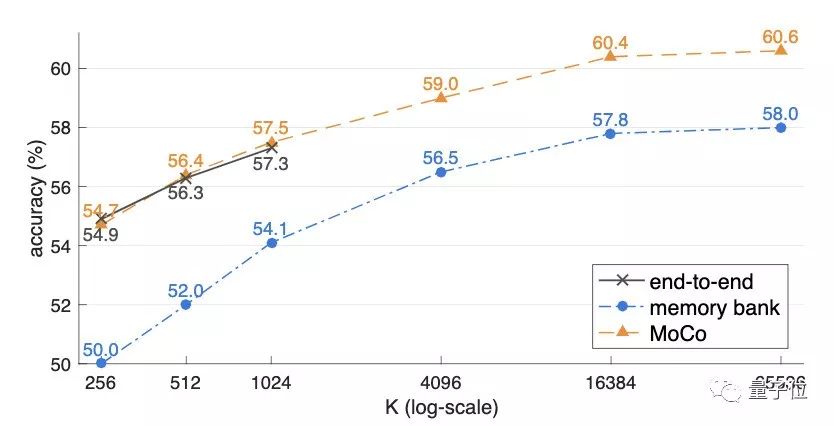
在三种不同机制的对比中,字典规模越大,三种方法的表现就越好。
当K较小时,端到端方法的表现与MoCo差不多,但其批处理大小受限,在8个32GB的V100上,最大的mini-batch仅为1024。并且,即使存储空间足够大,由于端到端方法必须满足线性学习率缩放规则,否则精度会下降,其增长趋势能否推及到更大规模是存疑的。
而memory bank的准确率则始终比MoCo低了2%以上。
在ImageNet上,MoCo表现出色。
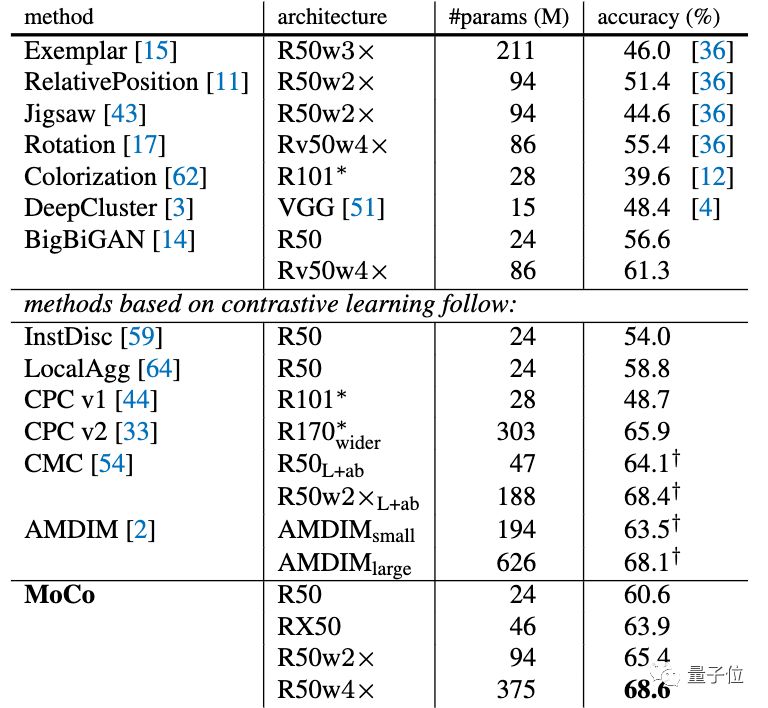
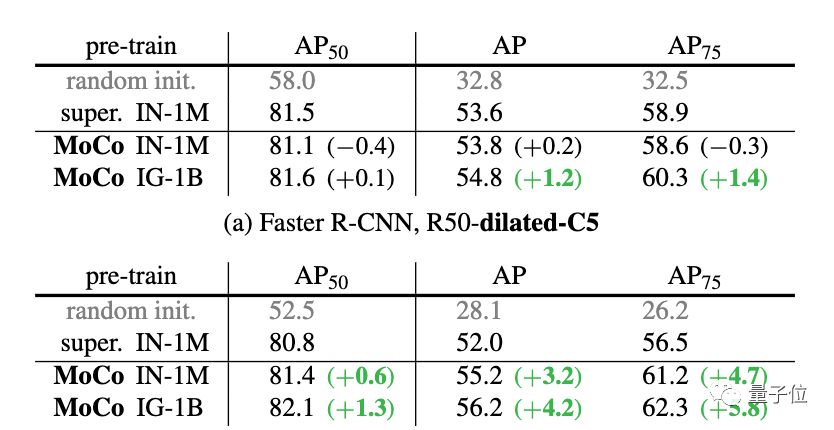
并且在针对不同的任务进行微调之后,MoCo可以很好地迁移到下游任务中,表现甚至优于有监督预训练模型。
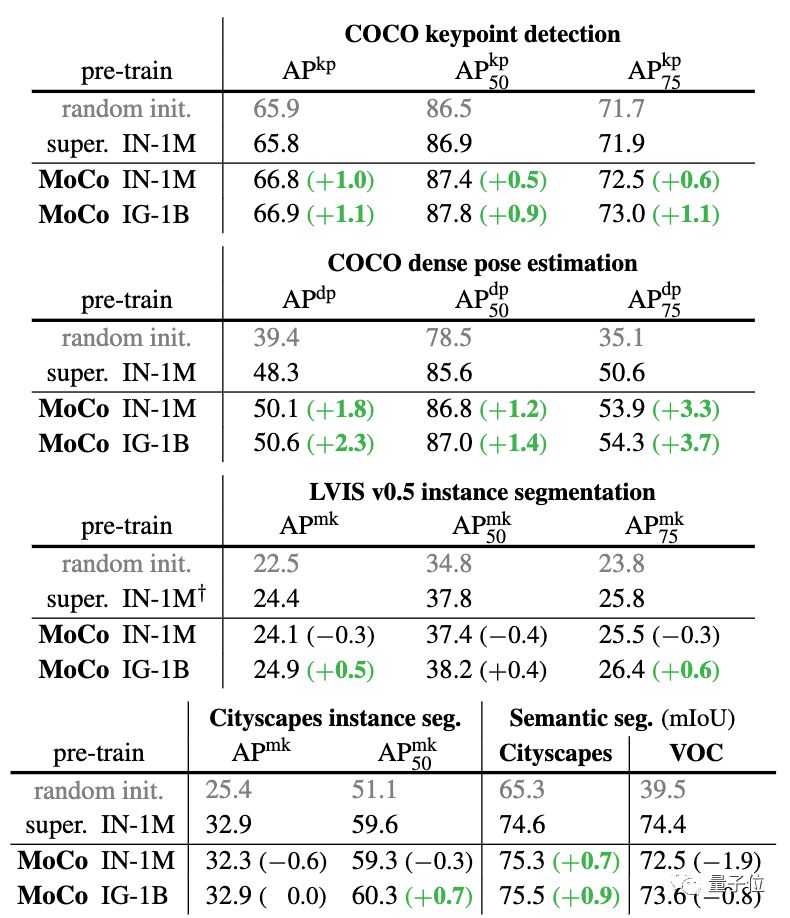
而PASCAL VOC,COCO等其他数据集上的7种检测/细分任务中,MoCo的表现也优于其他有监督预训练模型。甚至有十分明显的提升。

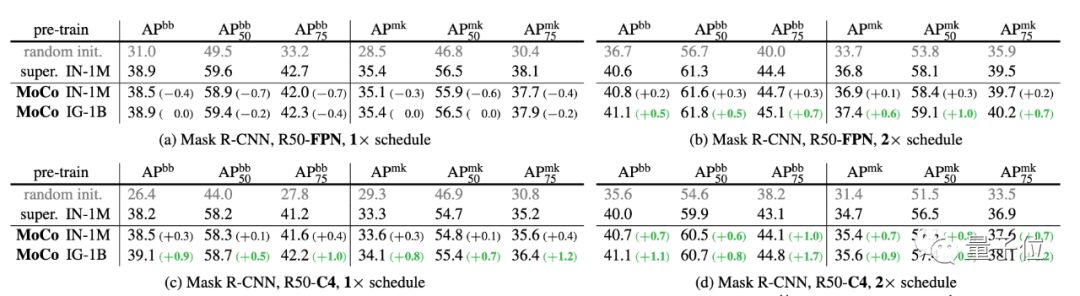
另外,在Instagram语料库上进行预训练的MoCo性能始终优于在ImageNet上训练的结果,这表明MoCo非常适合大型的、相对未整理的数据。
Facebook AI研究院的华人们
论文的研究团队,来自Facebook AI研究院(FAIR)。
一作何恺明,想必大家都不陌生。作为Mask R-CNN的主要提出者,他曾三次斩获顶会最佳论文。

何恺明大神加持,论文的其他几位作者实力也不容小觑。
Haoqi Fan,毕业于卡内基梅隆大学机器人学院,是FAIR的研究工程师。研究领域是计算机视觉和深度学习。有多篇论文入选ICCV、CVPR、AAAI等国际顶会。

吴育昕,FAIR研究工程师,本科毕业于清华大学,2017年于卡内基梅隆大学获得计算机视觉硕士学位。本科期间就曾在谷歌、旷视实习。

谢赛宁,本科毕业于上海交通大学,18年获加州大学圣迭戈分校CS博士学位。现在是FAIR的研究科学家。
另外一位论文作者Ross Girshick,同样是FAIR的研究科学家。博士毕业于芝加哥大学,曾在UC伯克利担任博士后研究员。

传送门
论文地址:
https://arxiv.org/abs/1911.05722
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
大咖齐聚!第一批参会嘉宾重磅揭晓
量子位 MEET 2020 智能未来大会启幕,李开复、倪光南、景鲲、周伯文、吴明辉、曹旭东、叶杰平、黄刚等AI大咖与你一起读懂人工智能。观众票即将售罄,扫码报名预定席位 ~


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !


