
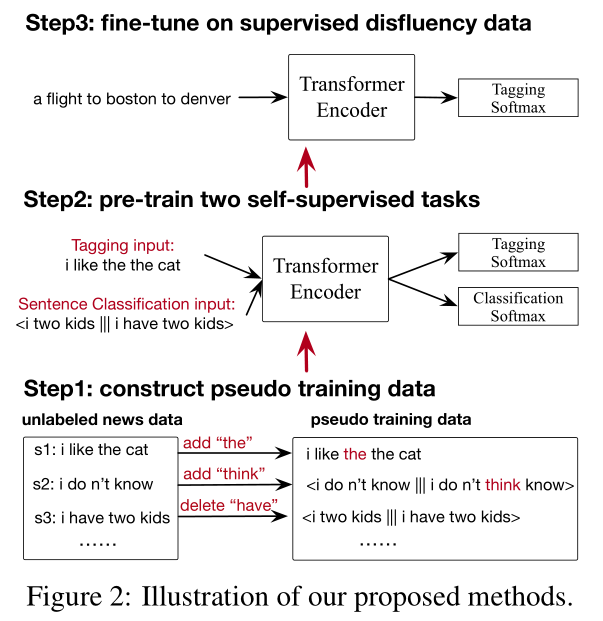
摘要: 现有的不流利检测方法大多严重依赖人工标注的数据,而在实践中获取这些数据的成本很高。为了解决训练数据的瓶颈,我们研究了将多个自监督任务相结合的方法。在监督任务中,无需人工标记就可以收集数据。首先,我们通过随机添加或删除未标记新闻数据中的单词来构建大规模的伪训练数据,并提出了两个自我监督的训练前任务:(i)标记任务来检测添加的噪声单词。(ii)对句子进行分类,区分原句和语法错误句子。然后我们将这两个任务结合起来共同训练一个网络。然后使用人工标注的不流利检测训练数据对训练前的网络进行微调。在常用的英语交换机测试集上的实验结果表明,与以前的系统(使用完整数据集进行训练)相比,我们的方法只需使用不到1%(1000个句子)的训练数据,就可以获得具有竞争力的性能。我们的方法在全数据集上进行训练,明显优于以前的方法,在英语Switchboard上将错误率降低了21%。
成为VIP会员查看完整内容

相关内容

专知会员服务
25+阅读 · 2020年7月1日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
39+阅读 · 2020年1月30日
Arxiv
6+阅读 · 2018年3月27日
相关主题




相关VIP内容
专知会员服务
25+阅读 · 2020年7月1日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
39+阅读 · 2020年1月30日
相关资讯