技术 | 有道CEO周枫:NVidia Volta GPU深度学习性能提升近10倍

周枫注:NVidia新的Volta GPU的最大特点就是增加了张量核Tensor Core,现在有了更多架构信息,以及实际的性能数据。
本文转自周枫的微信公众号(youdaozhoufeng)
在2017年的Hot Chips会议上,NVIDIA展示了更多关于他们新的Volta架构的信息。具体来说,话题是NVIDIA Tesla V100 GPU。目前,英伟达已经开始在数量有限的情况下提供基于Volta的GPU,本季度我们预计DGX-1将得到V100更新。在深度学习领域,这一代的NVIDIA硬件明显跨越了AMD的最新产品。
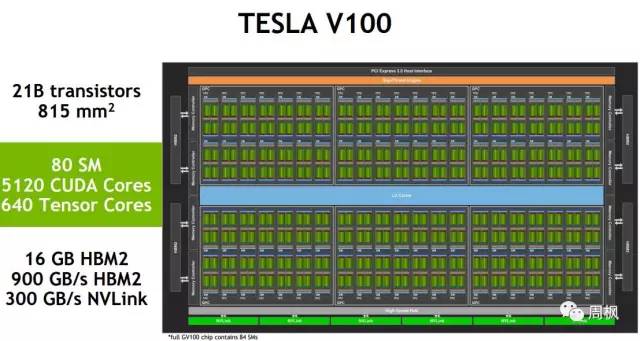
NVIDIA Tesla V100概述
可以看到,NVIDIA Tesla V100有80个流处理器(SM)。这张幻灯片上的小脚注,我们可以从座位上清楚地看到。该公司表示,完整的GP100芯片包含84个流处理器,因此NVIDIA是采用了Binning,以提高产量。
在性能方面,英伟达特斯拉(Tesla V100)的数字有时会令人难以置信。
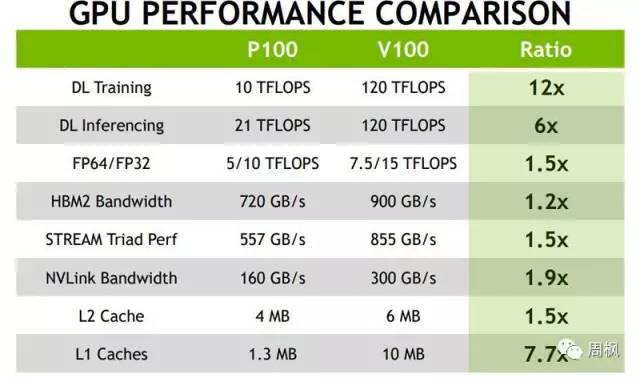
NVIDIA Tesla V100和P100比较
这里的关键是NVIDIA正在采用更大的缓存,并为深度学习空间增加特定的加速器,同时增强了整体带宽。
我们确实想要快速展示一下SM核心。人们会注意到SM核心有一个大的张量核(Tensor Core)。在这里NVIDIA这代的关注点就很明确了。
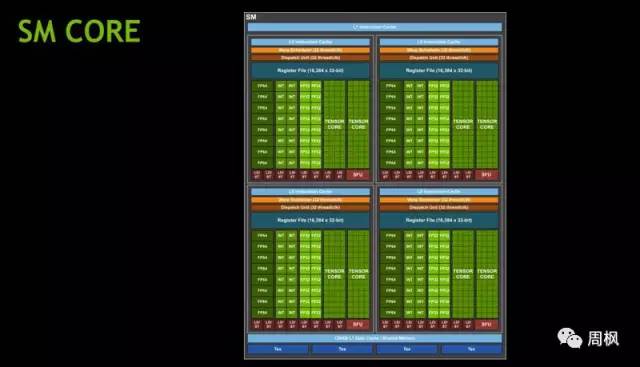
英伟达V100 SM核心
我们不会花太多时间来讨论英伟达在SM方面所呈现的文本。和大多数的架构改进一样,新的NVIDIA Volta GV100 SM是为了更多的性能而设计的。
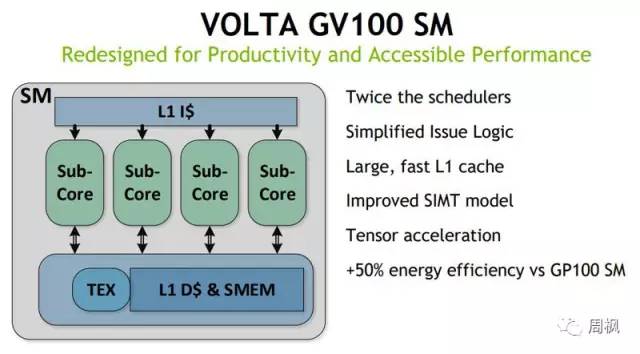
英伟达Volta GV100 SM
同样,这里是微架构视图:
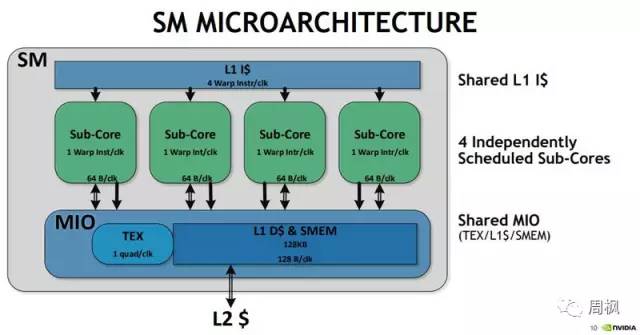
NVIDIA Volta V100 SM微架构
和sub-core视图:
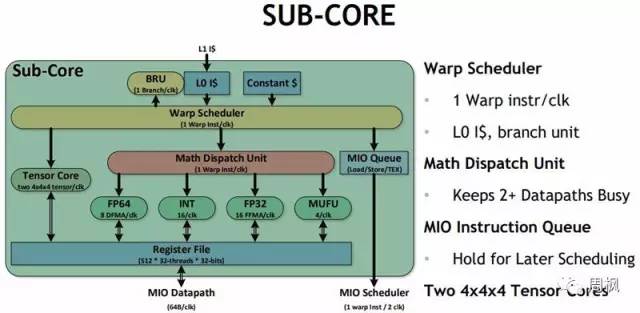
NVIDIA Volta V100 Sub Core
这里的关键是两个4x4x4张量核。这就是让Volta成为革命性飞跃的秘诀。
NVIDIA的另一个领域是L1缓存和共享内存。
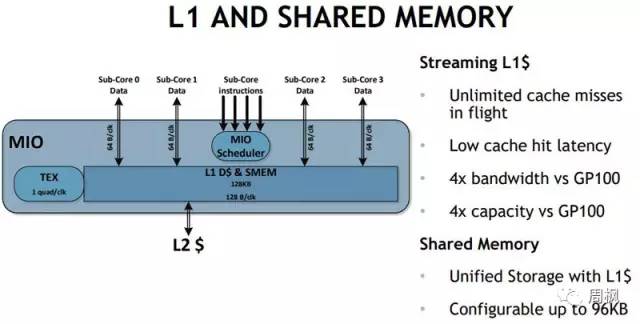
NVIDIA Volta V100共享内存
如果您知道您的工作负载可以利用这些数据局部性,那么现在可以将缓存作为共享内存使用。由于NVIDIA增加了L1和L2缓存,我们看到了比游戏所需的更多的计算驱动架构。
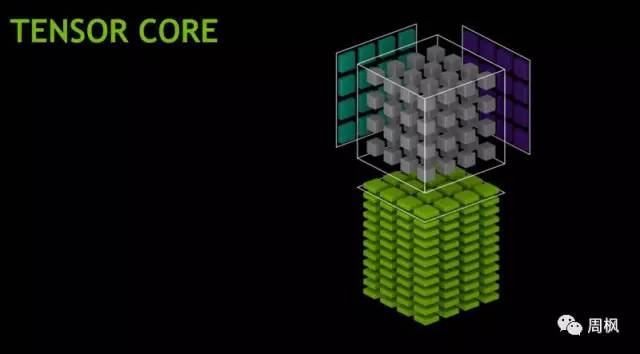
英伟达V100的张量核(Tensor Core)
张量核可以进行混合精度的4×4矩阵数学。
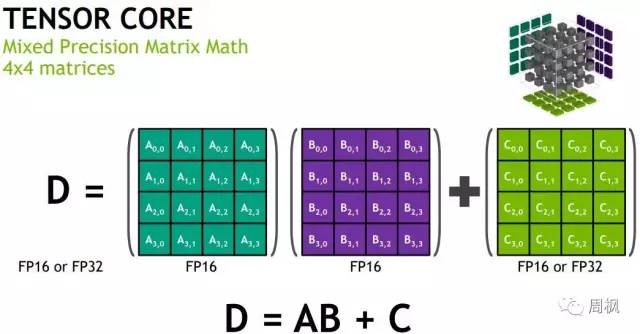
NVIDIA V100张量核心数学
这是训练深度学习模式的关键操作。通过改进调度,NVIDIA可以做16×16矩阵数学。
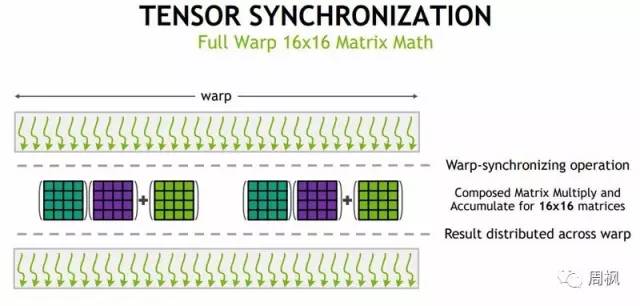
英伟达V100张量同步
这是NVIDIA在Volta张量操作上展示的另一个视图,展示了如何使用较低的精度FP16输入并到达FP32输出。
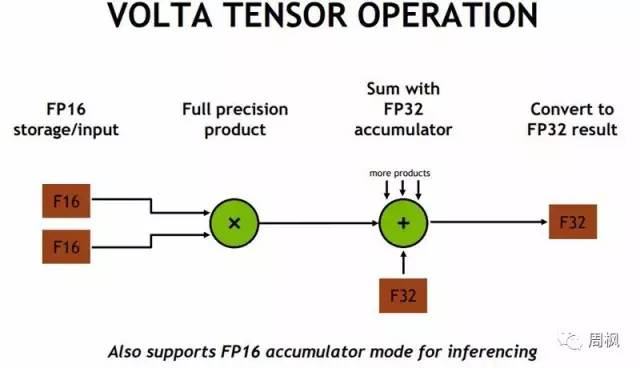
英伟达V100张量操作
在结果方面,英伟达声称一些操作将会出现9.3倍的加速。
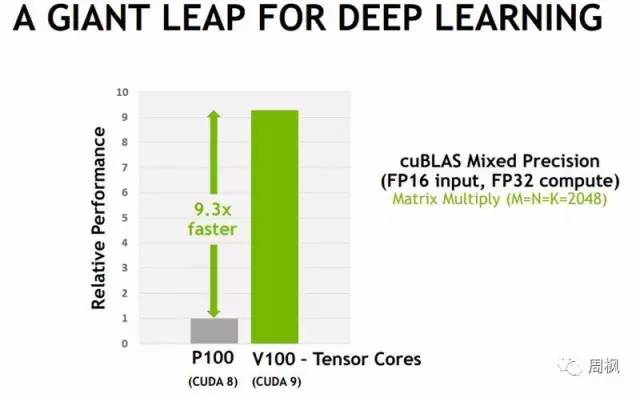
NVIDIA V100和P100深度学习性能比较
我们需要注意的是,以上NVIDIA将CUDA 8与CUDA 9软件的收益,和特定工作负载下的硬件收益结合在一起。
NVLINK更新
NVIDIA声称新的GV100 NVLINK将提供更多的带宽,达到1.9x,我们在GP100上看到的。
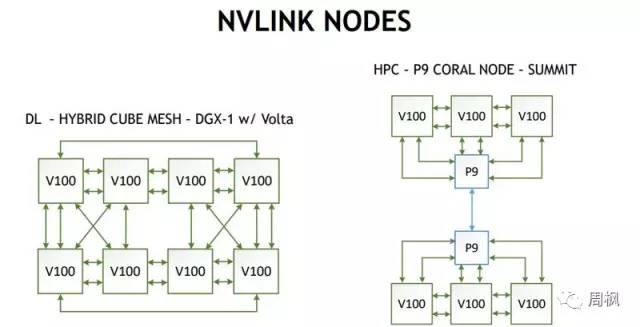
NVIDIA NVLINK节点
GV100将有多达6个NVLINK连接,它允许一些拓扑结构,以方便GPU与GPU连接。这当然是一种比我们在PCIe交换机中看到的得到更多GPU间带宽的方法。单根v双根深度学习的GPU到GPU系统。
最后的话
在NVIDIA的Tesla Volta V100演讲中,有一些关键的结论。首先,很明显,驱动数据中心的销售是这一代产品的一个架构目标。第二,我们必须考虑所有这些添加的逻辑是否对消费级产品有意义。英伟达在深度学习领域取得成功的关键之一是,高性能的CUDA训练可以在使用该公司的游戏GPU的台式电脑上进行。从NVIDIA展示的图中来看,人们不得不怀疑张量核(Tensor Core)是否会成为游戏产品线的一部分。NVIDIA Tesla V100作为高端产品自然拥有高端功能,但在V100设计中,似乎有很多用于非传统GPU(游戏)任务的硅。
(以上内容来自servethehome.com文章的有道机翻,稍加修正,看原文戳原文链接)
原文地址:
https://www.servethehome.com/nvidia-v100-volta-update-hot-chips-2017/
译文地址:
https://mp.weixin.qq.com/s/1f-D87NJ5IozLGF45Qs3xg
精选福利
关注AI科技大本营,进入公众号,回复对应关键词查看分类专题;回复“入群”,加入AI科技大本营学习群。
回复“深度学习”,一文囊括30篇深度学习精华文章。
回复“机器学习”,一文推荐30篇机器学习优质文章。
回复“访谈”,查看吴喜之、周志华、杨强、蚂蚁金服漆远、今日头条李磊的独家访谈实录。
回复“资源”,一文梳理机器学习,深度学习,神经网络等各方面的资源。
回复“视频”,5分钟的视频带你轻松入门人工智能。
回复“程序员”,带你了解别人家的程序员如何学好AI。
回复“数据”,帮你弄清楚人工智能与数据科学之前的关系。
回复“课程”,跟我一起免费学习:谷歌大脑深度学习&Fast.ai最实战深度学习&David Silver深度强化学习。