沈向洋博士清华就职演讲全录:构建负责任的 AI

整理 | 杨晓凡、蒋宝尚
编辑 | 贾伟




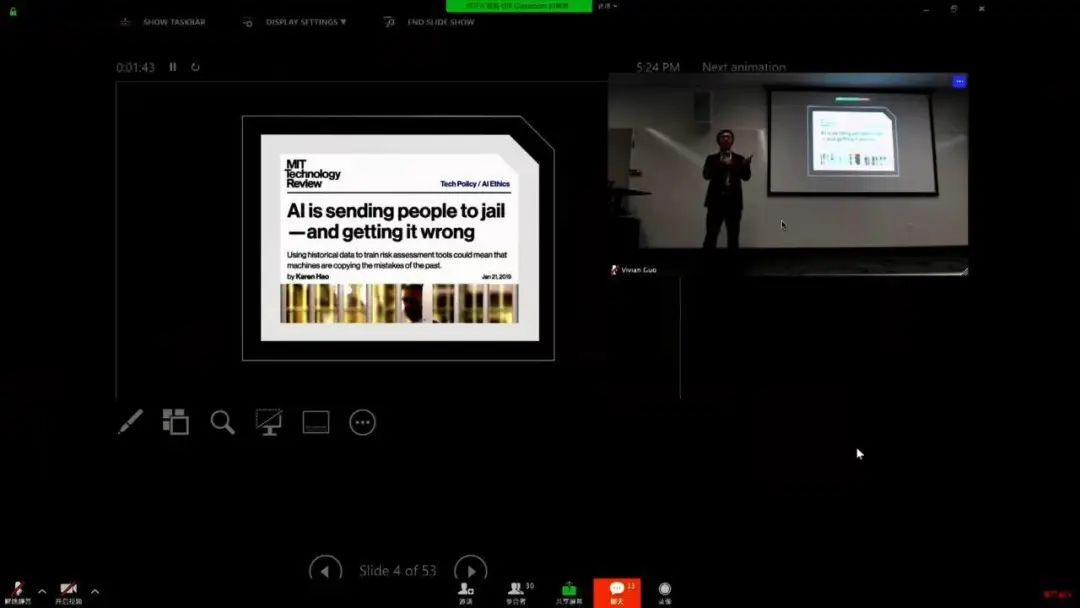
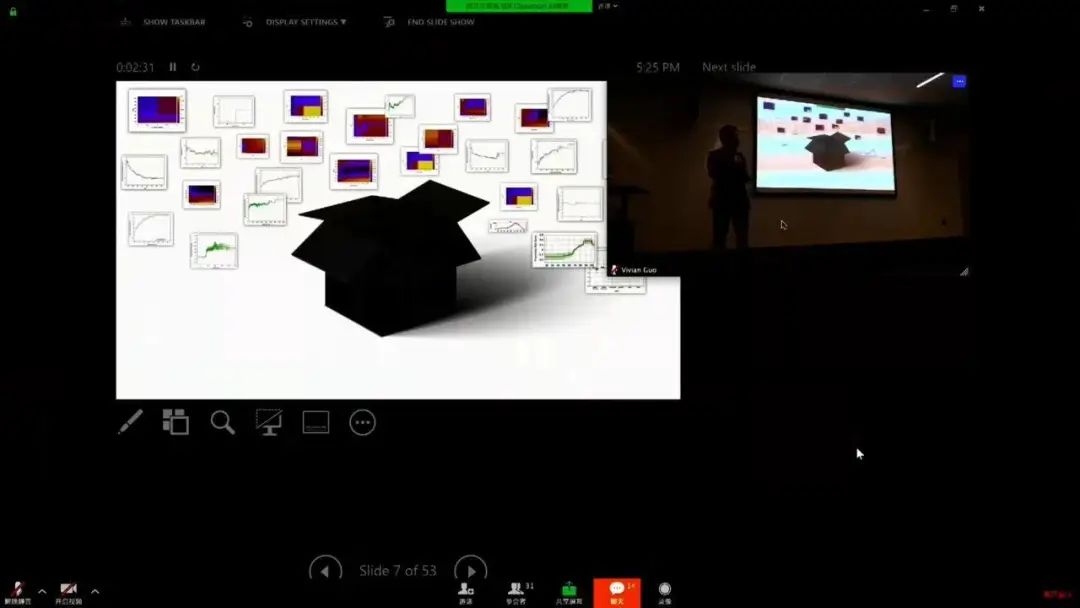
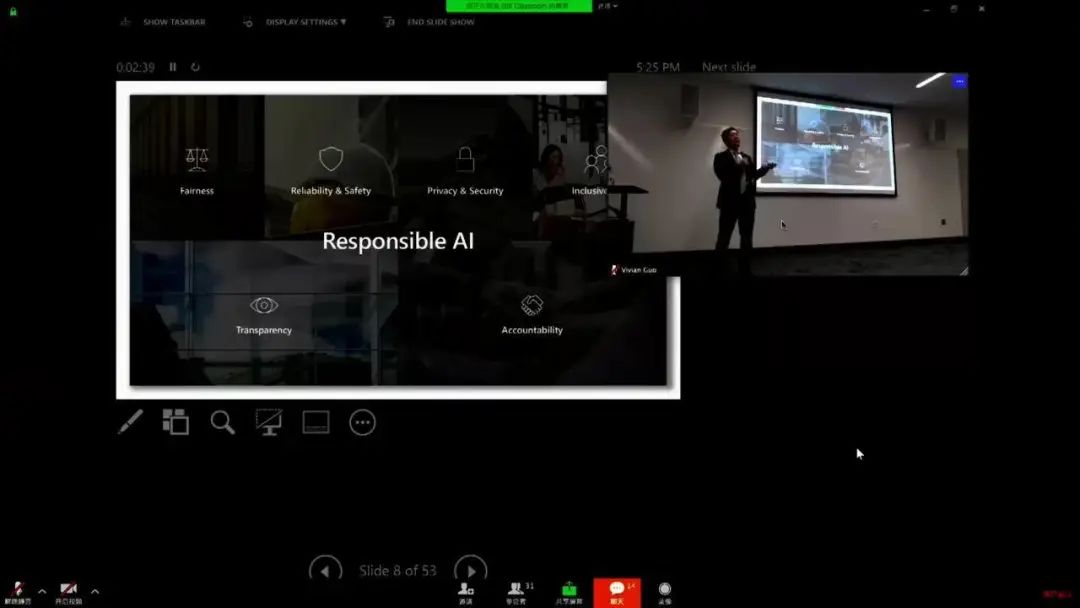
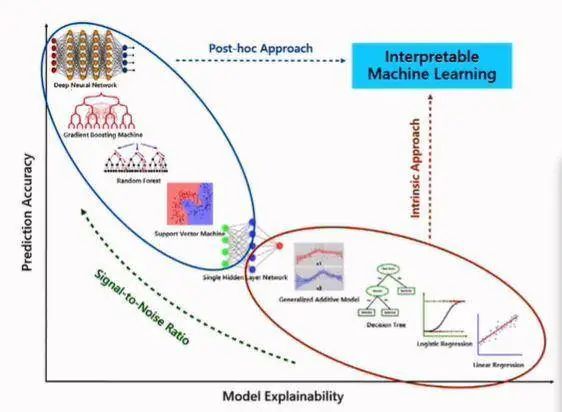

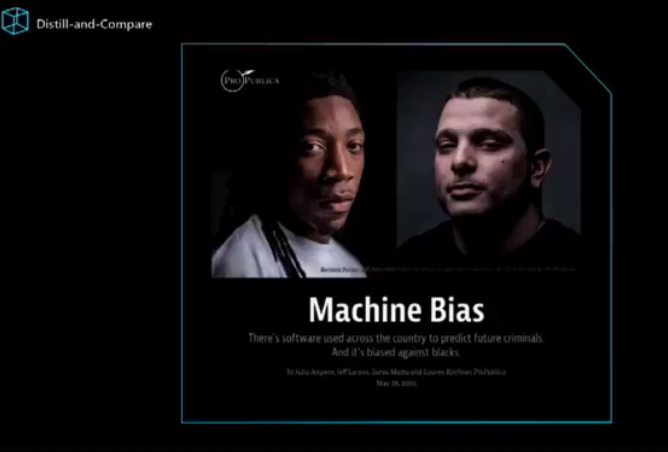
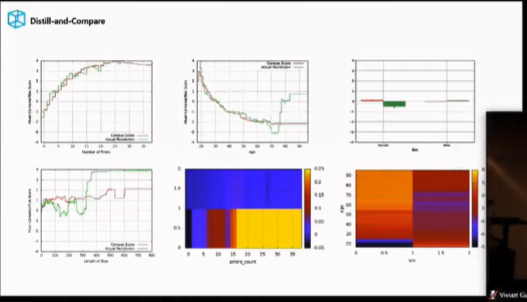
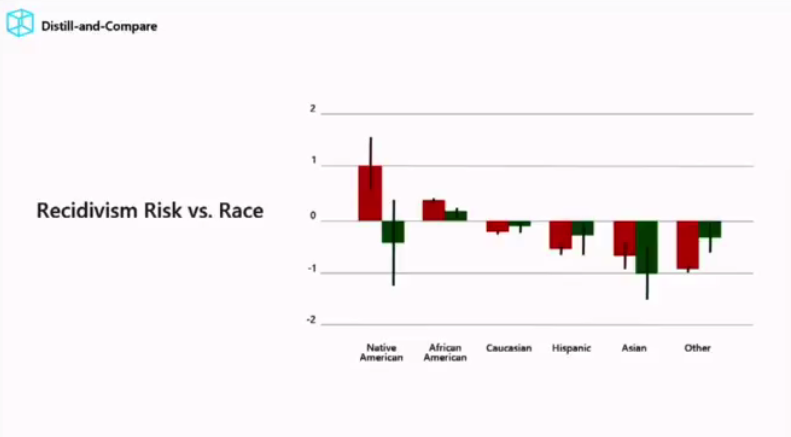

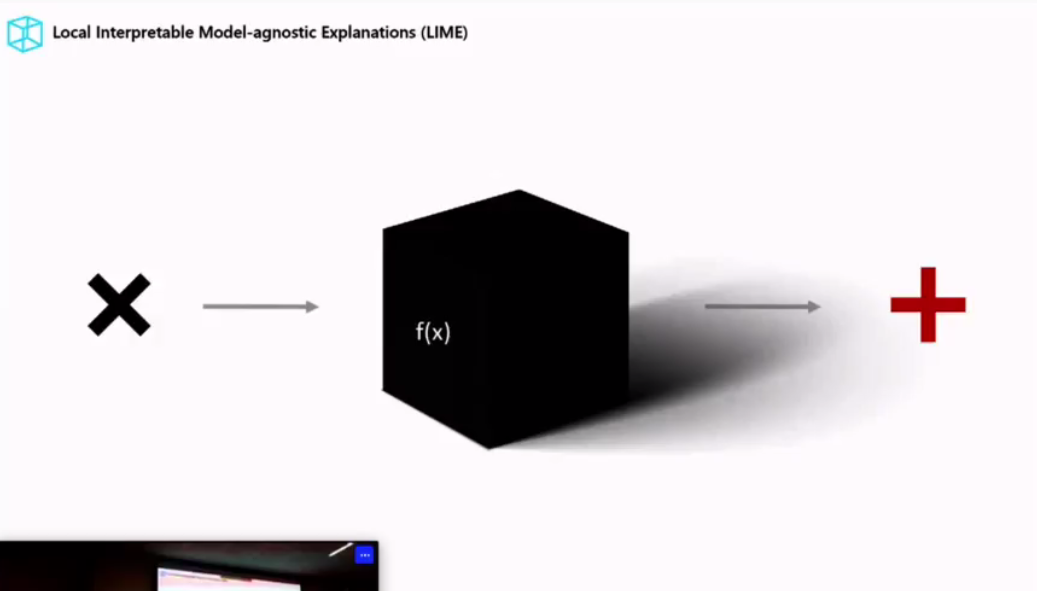
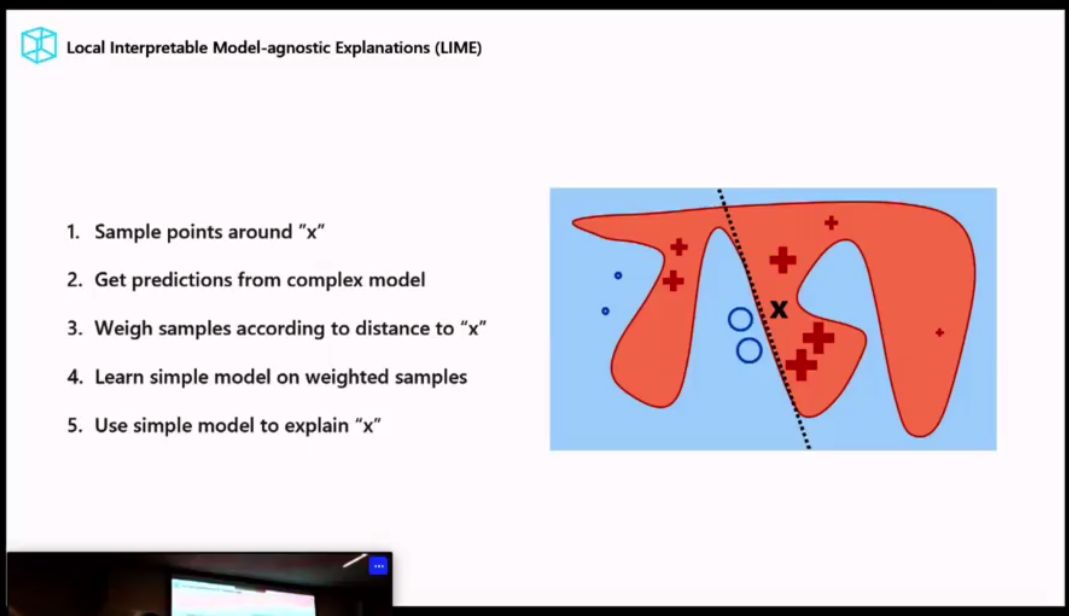



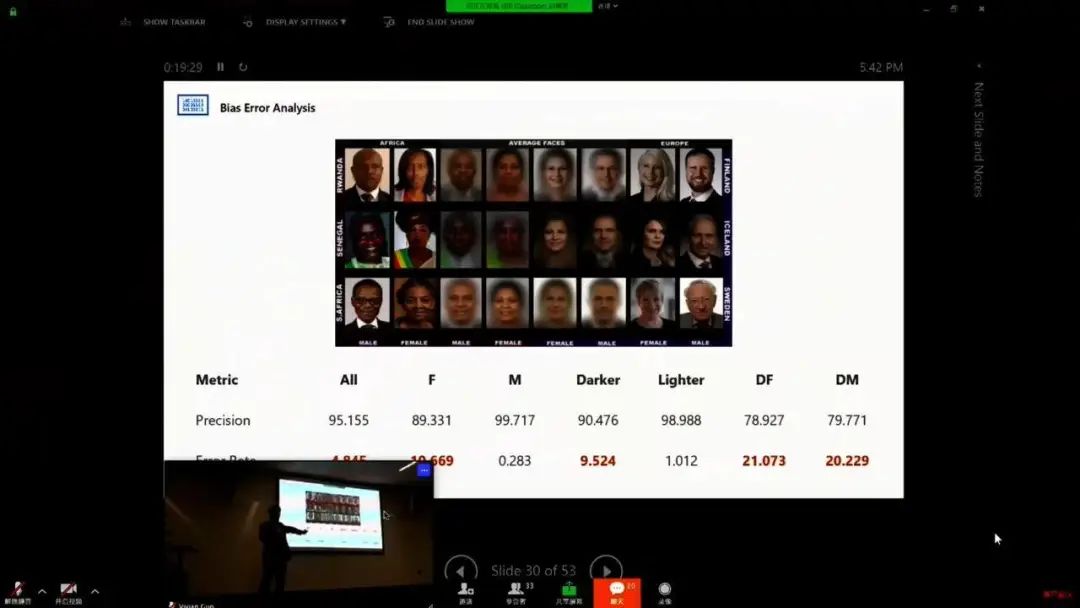
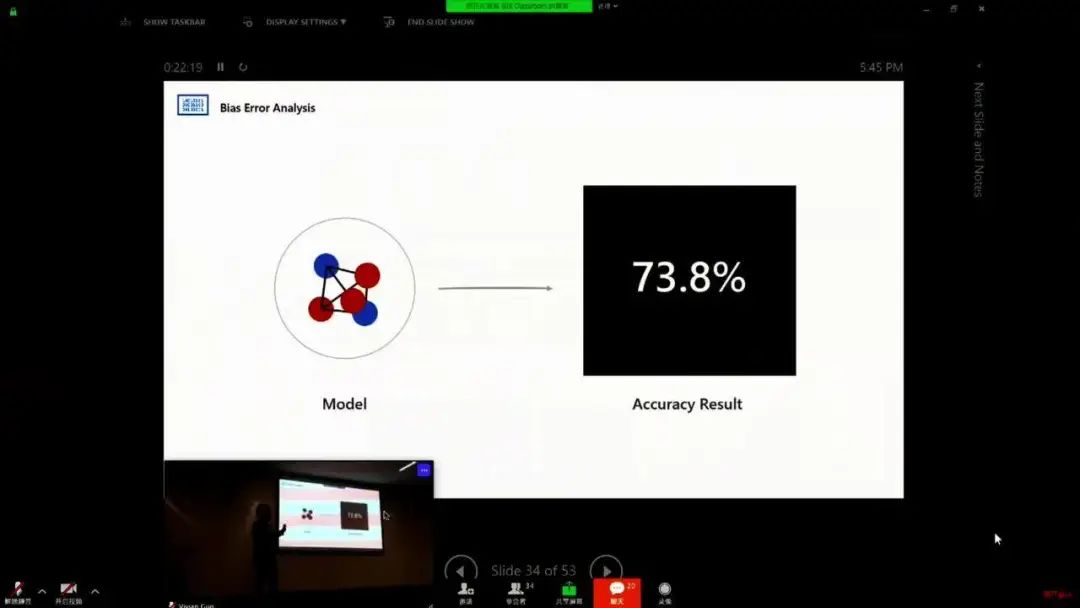
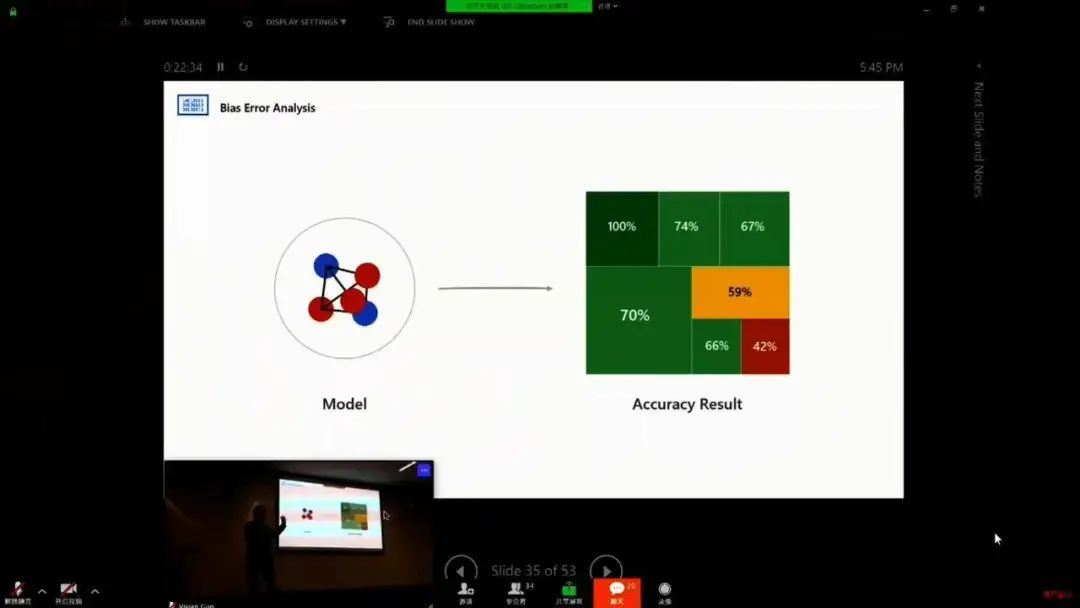
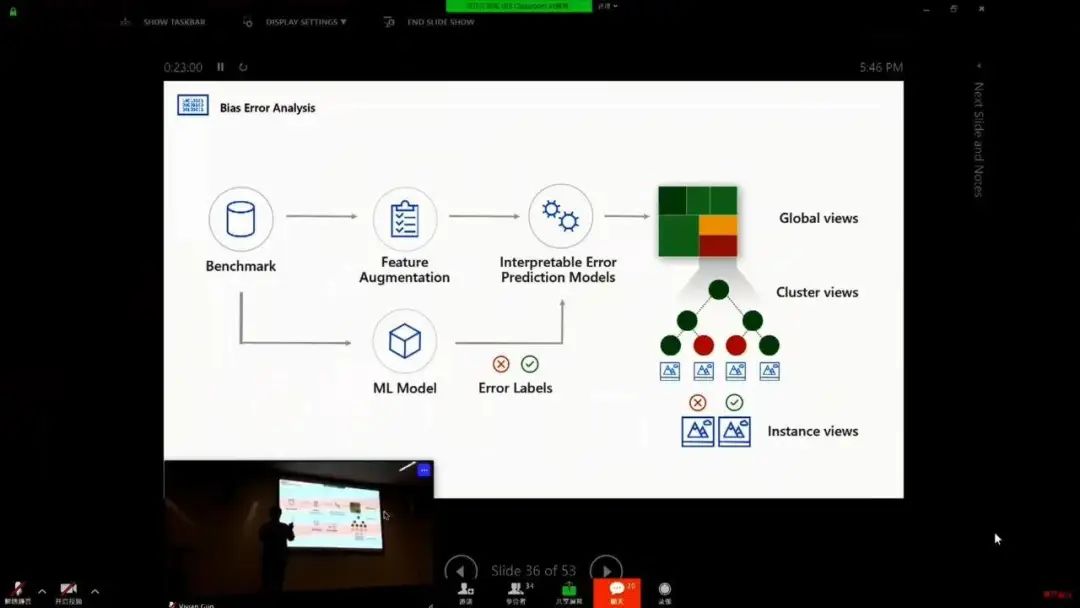
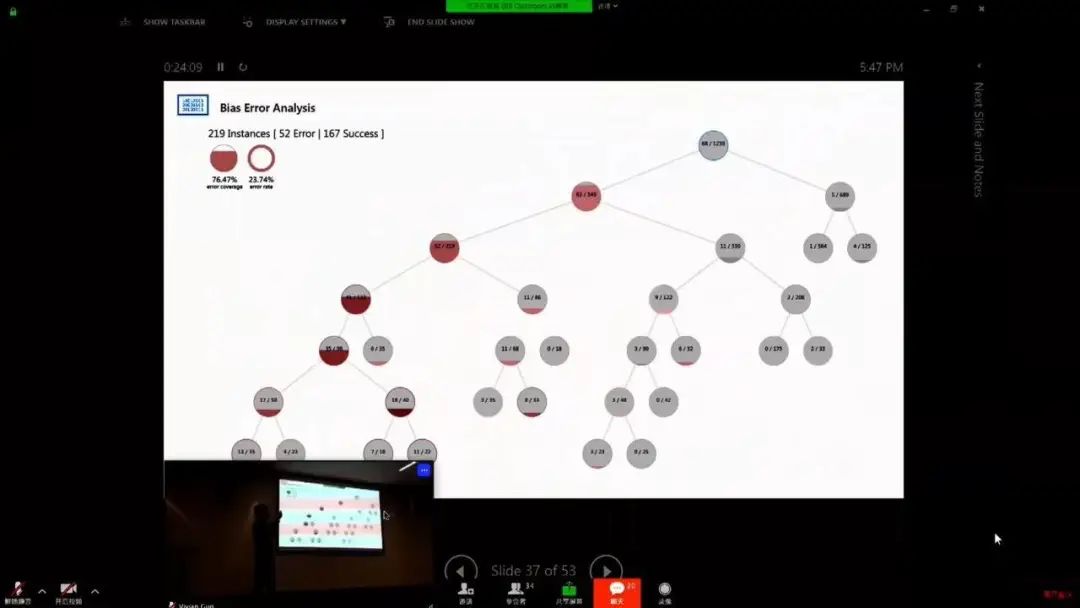
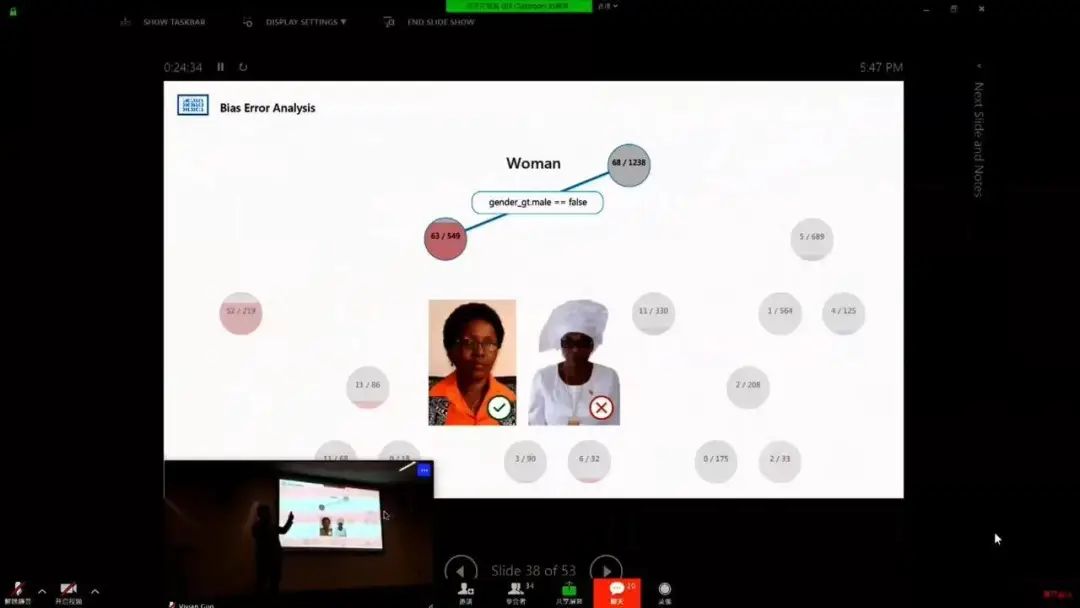
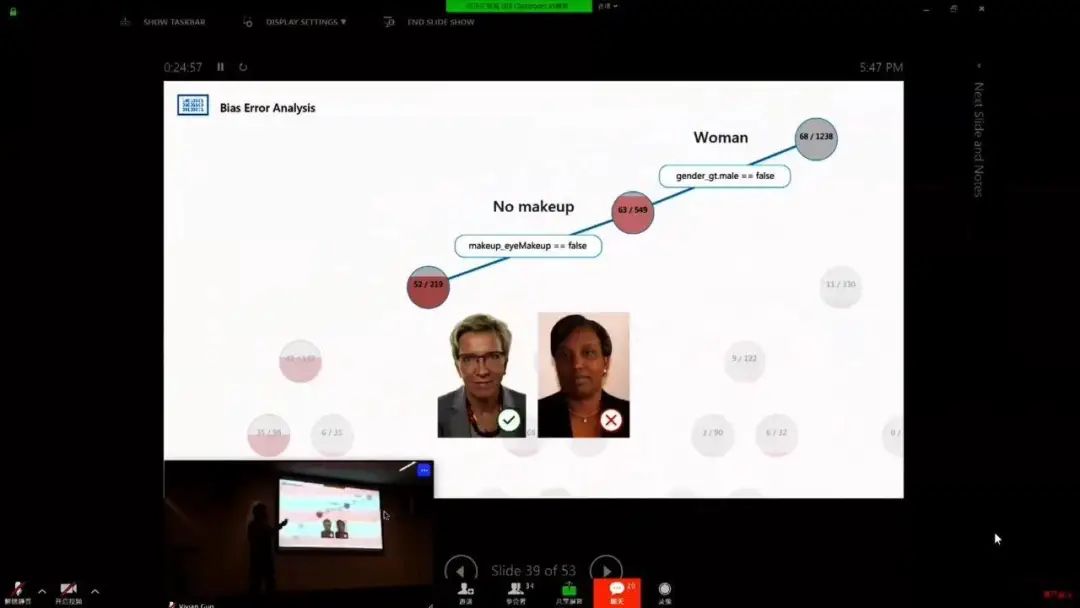
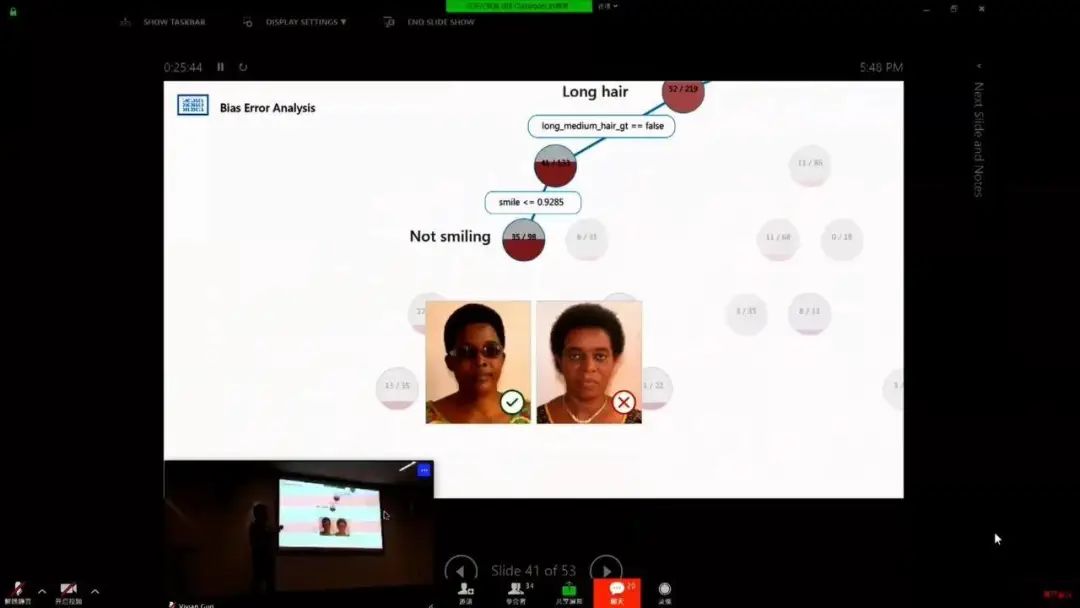
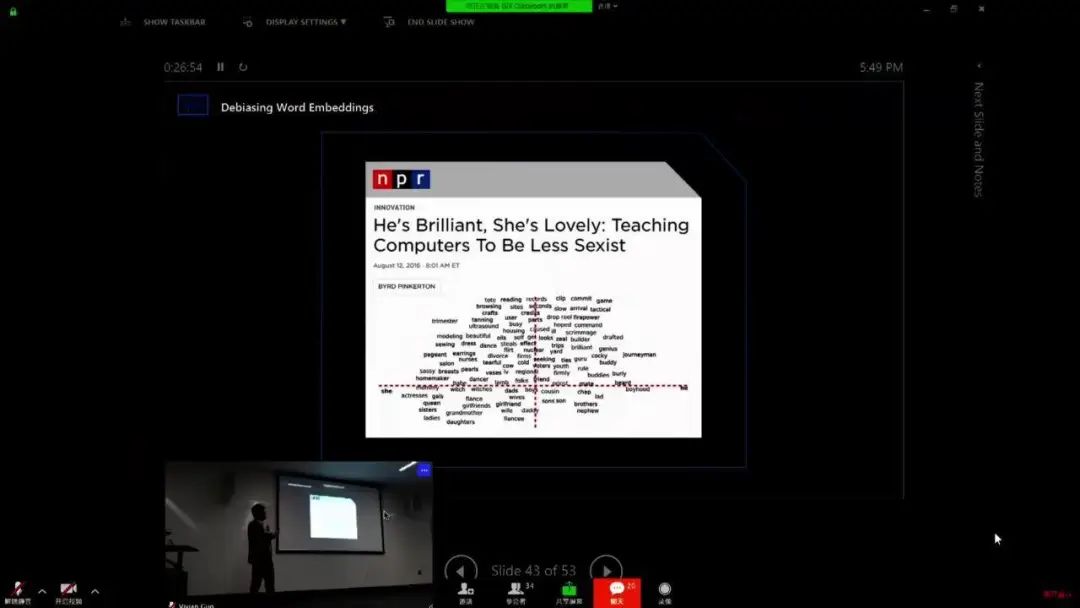
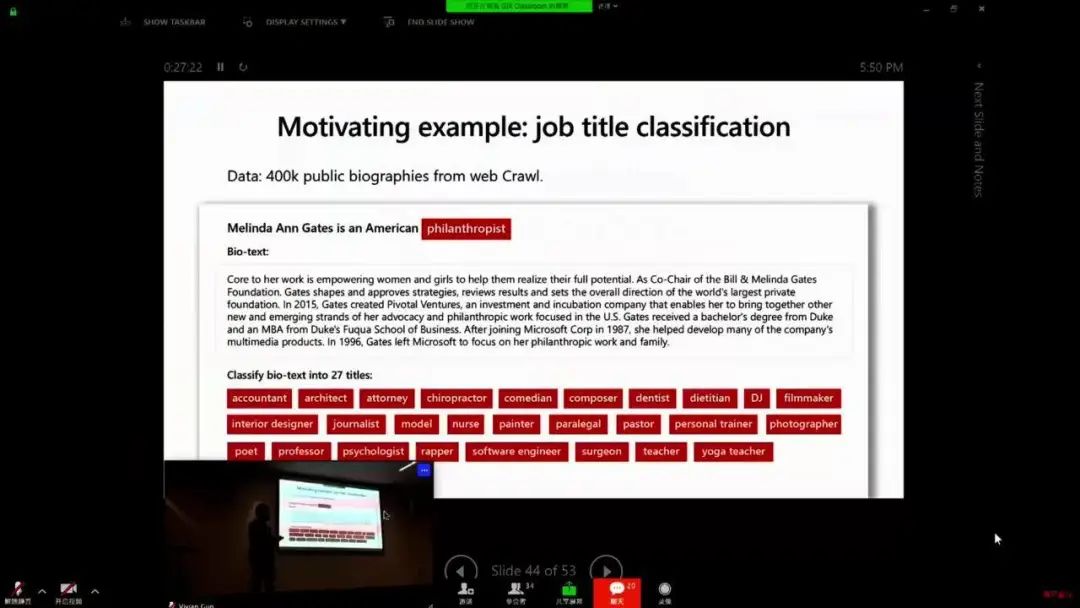
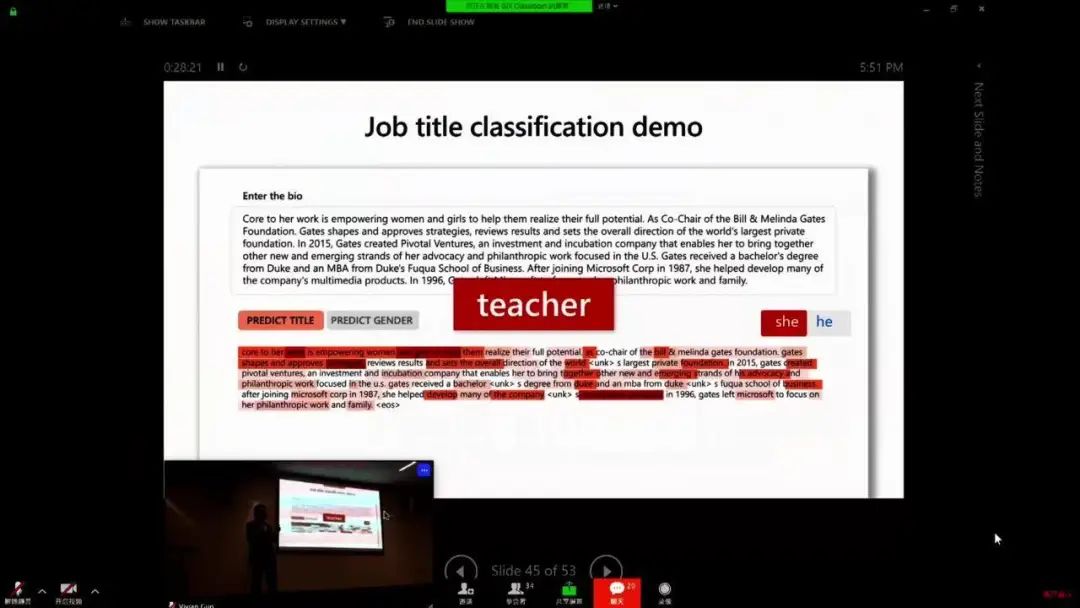
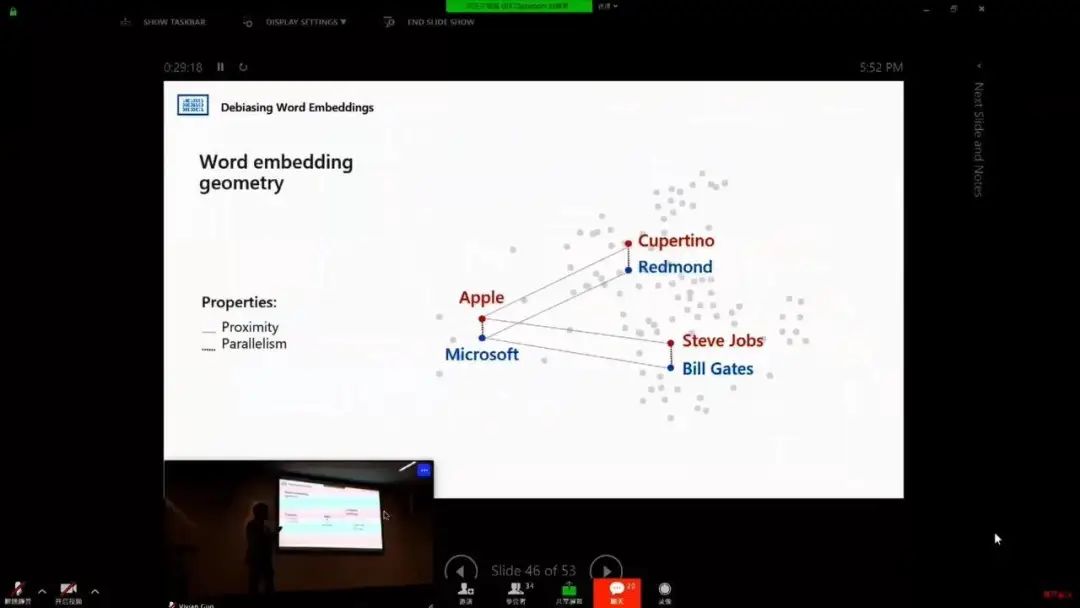
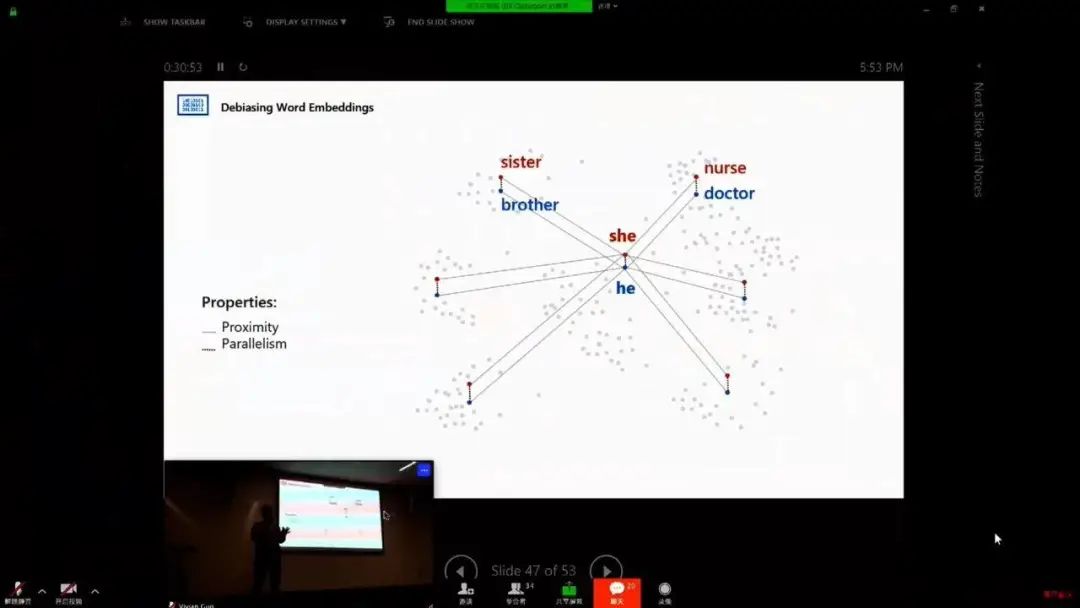
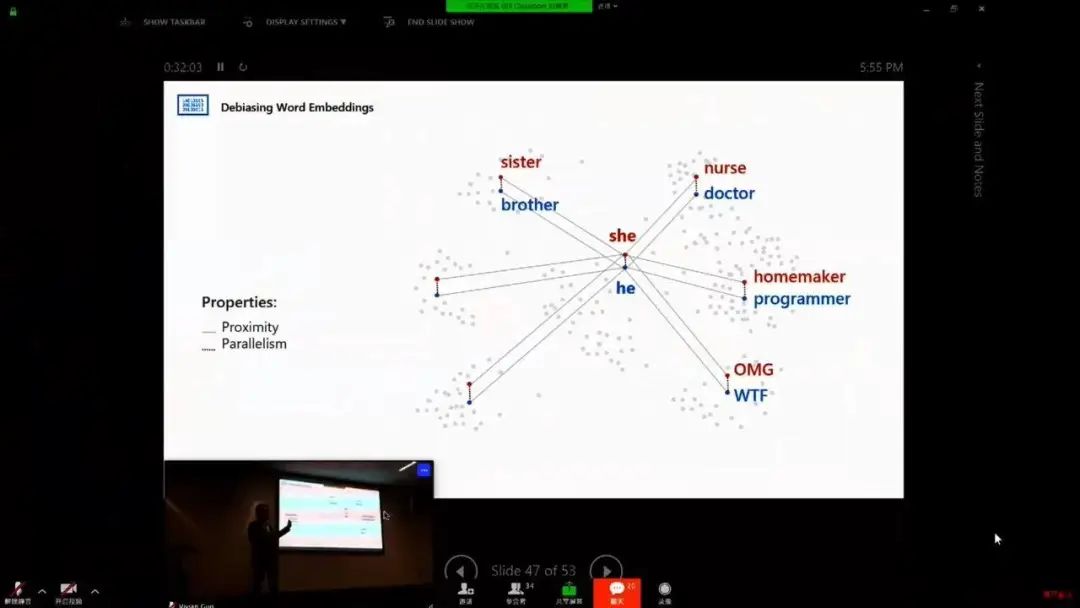
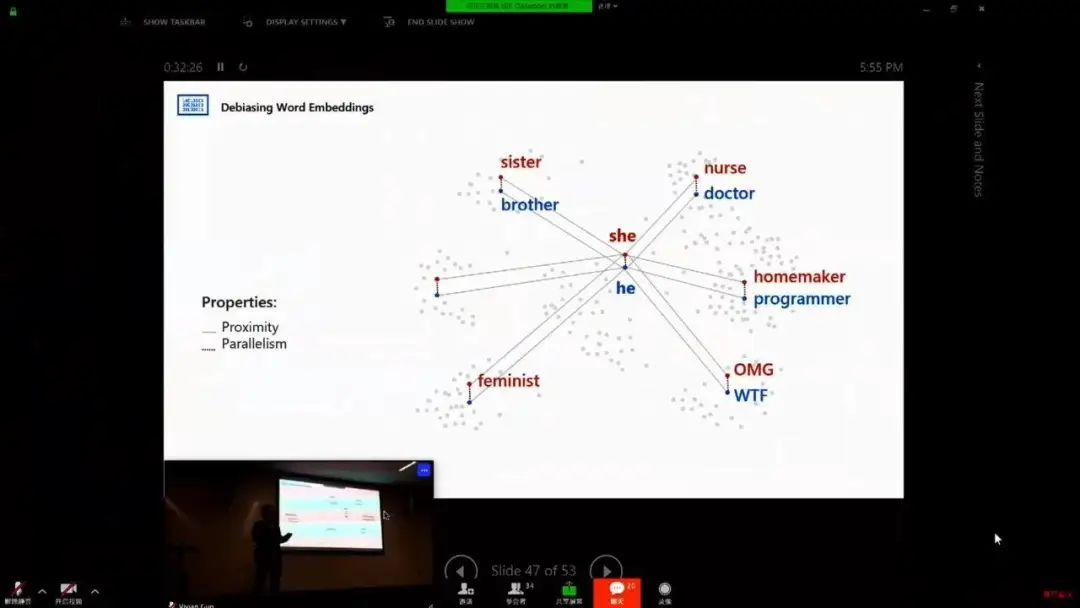
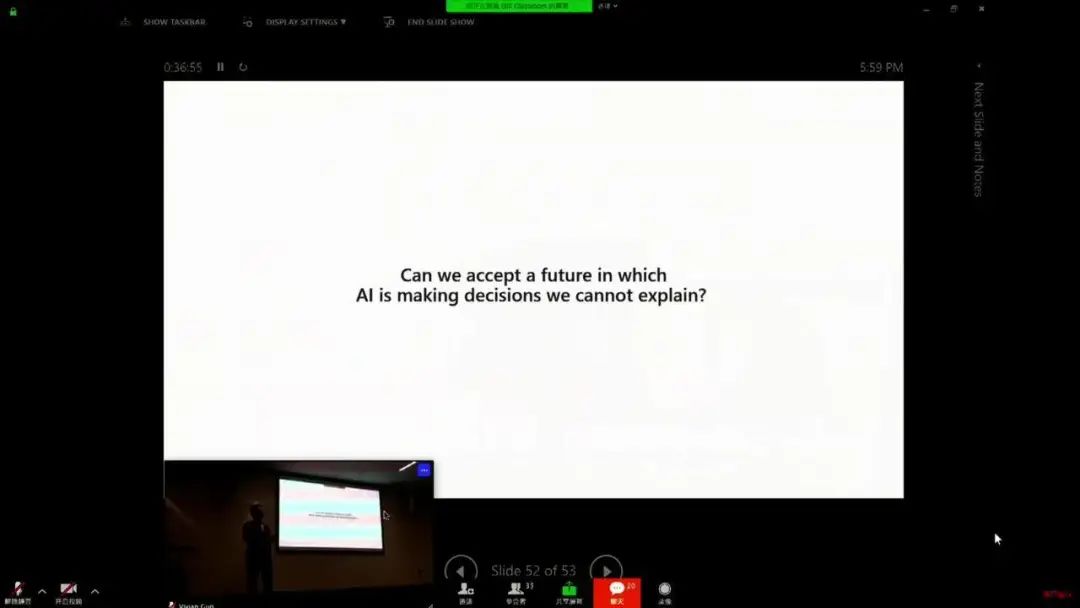
AI 偏见



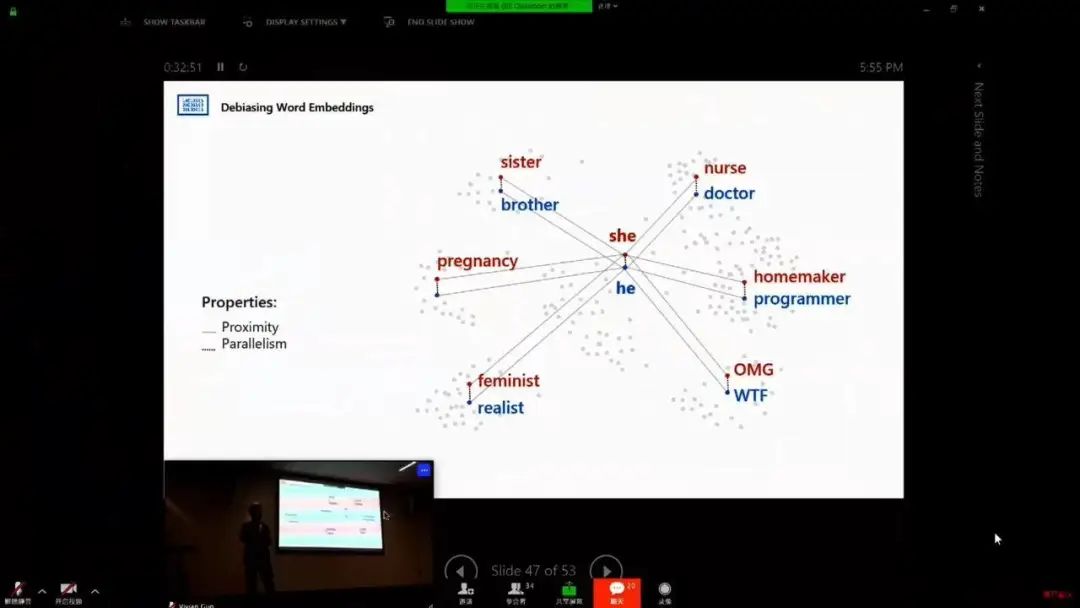
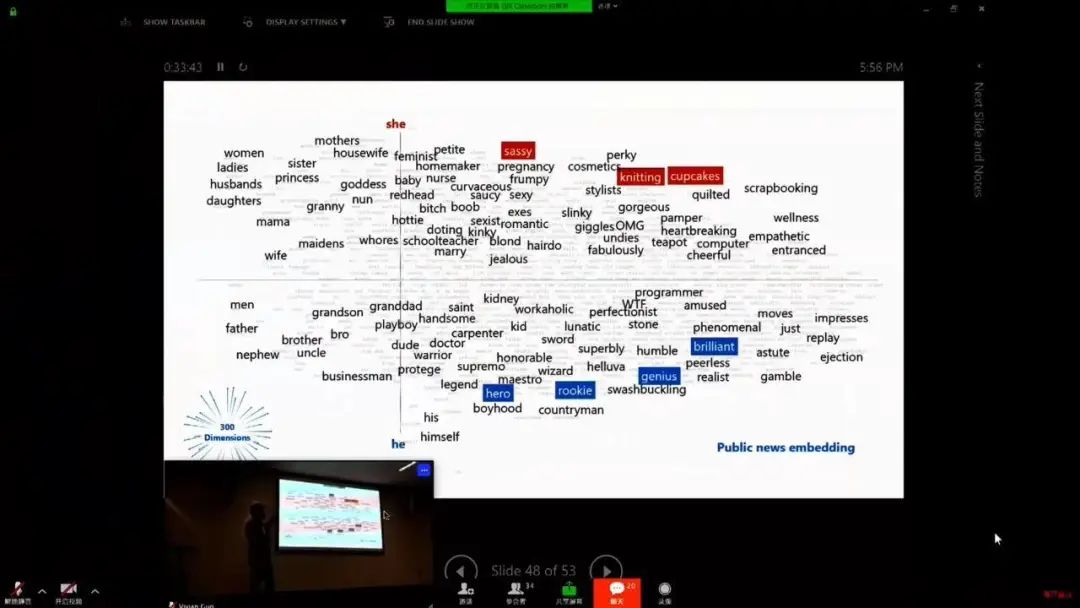
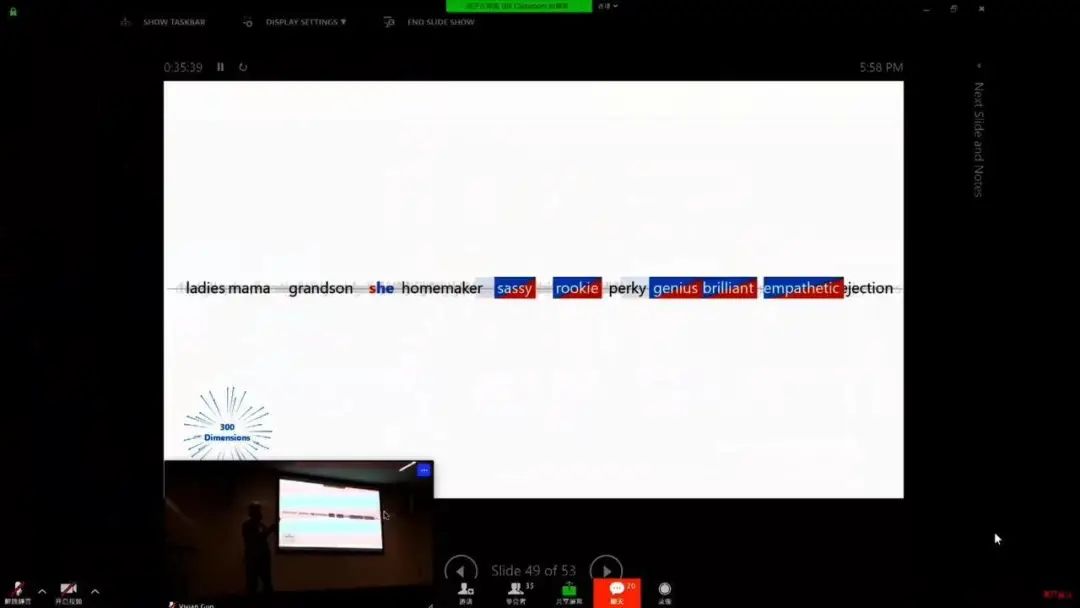
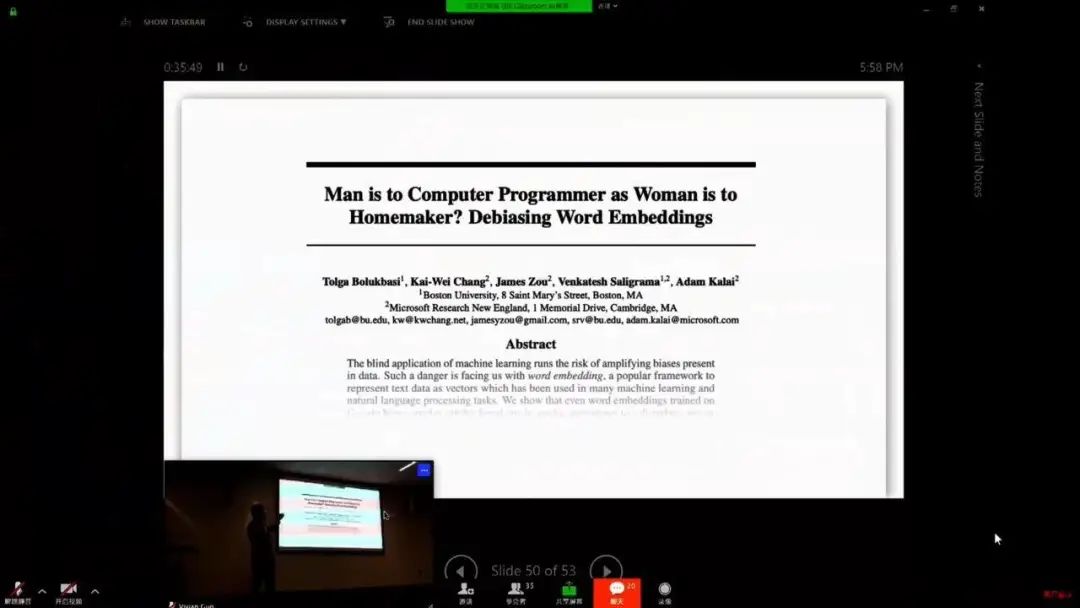
登录查看更多
相关内容

专知会员服务
34+阅读 · 2020年3月18日



相关VIP内容
专知会员服务
34+阅读 · 2020年3月18日
相关资讯
相关论文