【导读】国际万维网大会(The Web Conference,简称WWW会议)是由国际万维网会议委员会发起主办的国际顶级学术会议,创办于1994年,每年举办一届,是CCF-A类会议。WWW 2020将于2020年4月20日至4月24日在中国台湾台北举行。本届会议共收到了1129篇长文投稿,录用217篇长文,录用率为19.2%。这周会议已经召开。来自美国Linkedin、AWS等几位学者共同给了关于在工业界中可解释人工智能的报告,讲述了XAI概念、方法以及面临的挑战和经验教训。

人工智能在我们的日常生活中扮演着越来越重要的角色。此外,随着基于人工智能的解决方案在招聘、贷款、刑事司法、医疗和教育等领域的普及,人工智能对个人和职业的影响将是深远的。人工智能模型在这些领域所起的主导作用已经导致人们越来越关注这些模型中的潜在偏见,以及对模型透明性和可解释性的需求。此外,模型可解释性是在需要可靠性和安全性的高风险领域(如医疗和自动化交通)以及具有重大经济意义的关键工业应用(如预测维护、自然资源勘探和气候变化建模)中建立信任和采用人工智能系统的先决条件。
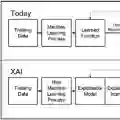
因此,人工智能的研究人员和实践者将他们的注意力集中在可解释的人工智能上,以帮助他们更好地信任和理解大规模的模型。研究界面临的挑战包括 (i) 定义模型可解释性,(ii) 为理解模型行为制定可解释性任务,并为这些任务开发解决方案,最后 (iii)设计评估模型在可解释性任务中的性能的措施。
在本教程中,我们将概述AI中的模型解译性和可解释性、关键规则/法律以及作为AI/ML系统的一部分提供可解释性的技术/工具。然后,我们将关注可解释性技术在工业中的应用,在此我们提出了有效使用可解释性技术的实践挑战/指导方针,以及在几个网络规模的机器学习和数据挖掘应用中部署可解释模型的经验教训。我们将介绍不同公司的案例研究,涉及的应用领域包括搜索和推荐系统、销售、贷款和欺诈检测。最后,根据我们在工业界的经验,我们将确定数据挖掘/机器学习社区的开放问题和研究方向。