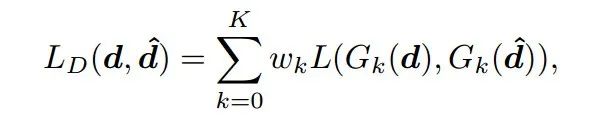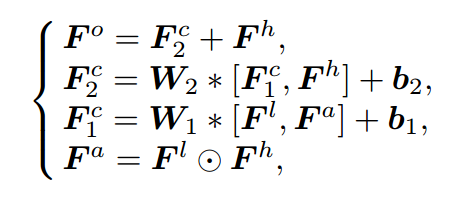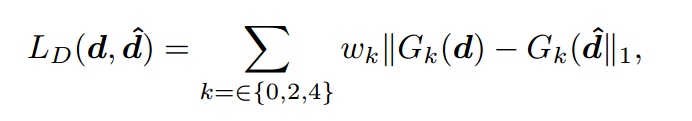点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:将门创投
![]()
From: 大连理工;编译: T.R
近年来,随着深度学习的发展,深度估计任务的性能得到了极大的提升,多层级CNN结构具有非常强的表达能力,使得更为精确的单目深度估计成为可能。为了有效训练模型进行深度估计,一个良好设计的损失函数显得尤为重要,它可以有效测量出预测结果与目标间的差异,从而指导模型更好地进行学习。
人们曾提出很多种损失函数用于深度估计,但这些损失函数并不尽如人意。因此,需要在不同空间中探索用于深度估计的有效训练损失。
本文将介绍一种多层嵌入损失的新方法,让深度估计更加清晰。
![]()
论文链接:
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123500307.pdf
代码链接:
https://github.com/scott89/CLIFFNet
先前,人们提出了很多种损失函数用于深度估计,包括可以有效处理重尾分布的Huber损失与深度意识损失,可以平衡深度与尺度关系的尺度不变性损失与深度梯度损失等等。在这些损失函数的指导下,大量的深度估计模型实现了优异的估计结果。但这些损失函数大多基于手工设计,而且需要依赖丰富的领域知识,缺乏泛化性、无法捕捉多尺度上下文信息,同时还对标签的噪声和局外点过度敏感,造成了不稳定的网络训练过程。
为了解决这些问题,需要在不同空间中探索用于深度估计的有效训练损失。
在这些问题的引导下,本文的作者提出了一种
在分级嵌入空间中计算损失函数用于深度估计模型训练
的思路。一方面,设计了生成多层级嵌入的生成器
HEGs (hierarchical embedding generators)
, 来从深度图中抽取特征,构建不同层级的子空间,随后通过计算出的基准深度嵌入和预测出的深度嵌入间的距离来构建损失函数。
为了找到合适的分层嵌入,研究人员利用多任务方法训练HEGs。 结果表明,
在相关任务上进行训练,即使在没有额外标注的情况下,也能显著提升深度估计的性能。
同时研究还发现,广泛使用的
梯度损失函数
也是HEGs的一个特例,但在合适的训练后,HEGs的性能可以轻松超越手工设计的损失函数。此外,研究人员还提出了
CLIFF (cross level identity feature fusion)
模块作为基础构建深度估计网络,通过有效结合高级特征的稳定性、语义特征和底层特征的高分辨、局域信息,优化深度估计结果和细节分辨率。
与先前直接在原始的深度图空间中进行比较的方法不同,本研究提出了一种
在学习到的嵌入空间中定义损失
的方法,这一嵌入空间不是手工定义的,而是通过相关任务学习得到的有效嵌入空间。在此思想的指导下,需要设计出一个
嵌入生成器G (d,θ)
,G输入深度图在参数θ的作用下获取嵌入特征,这里的θ就可以用数据驱动的方式学习得到。
为此研究人员提出了一个
多层CNN构成的HEG
,输入一次深度图可以获取K个层级的卷积特征图作为嵌入特征,最终按照下面的函数计算得到目标深度和预测深度间的层级损失:
其中K代表了对应的层级,0级代表恒等变换G0(d) = d。所以这种方式融合了原始深度空间和嵌入空间的联合损失。那么现在面临的问题就是:如何学习HEGs嵌入提取器的参数?如何构建这个嵌入特征抽取模型?
-
训练抽取嵌入特征的任务要与深度估计任务有相关性
,否则就无法让深度估计任务受益。例如,利用图像分类任务进行HEG预训练后,在进行深度估计后得到的性能与随机初始化HEG近似,这就意味着它没有获取对于深度估计有效的信息。
-
相关任务尽量无需额外的数据标注
,目的是使这种方法可以便捷地迁移到其他数据集上,同时更为公平。
在上述原则的指导下,研究人员选择了基于深度图的
场景分类
任务和
深度重建
任务作为得到HEG的预训练任务。
首先,针对基于深度图的场景分类任务,目前像NYU-Depth V2和Cityscape数据集都有多个场景,包含了场景元数据,无需复杂的标注。
通过学习识别深度图与场景间的关系,HEG可以捕捉输入深度图上的关键信息,可以有效地帮助后续的深度估计任务。
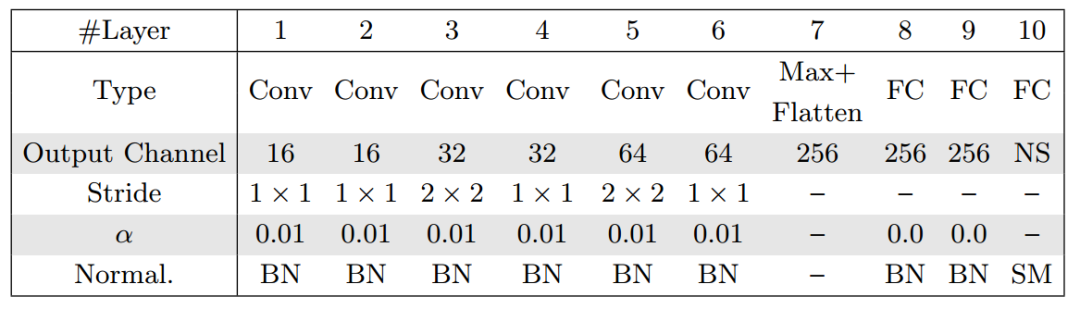
下表显示了这一任务中的编码器结构,中间层输出的特征图就可以作为计算出的分层嵌入来训练深度估计网络。这里的嵌入抽取器被定义为HEG-S。
![]()
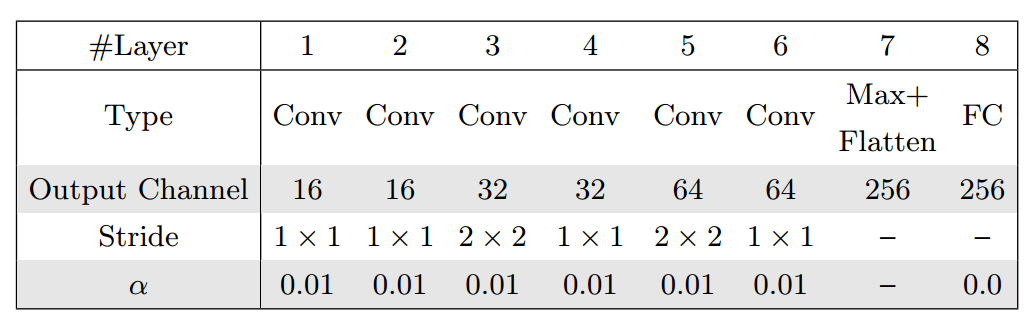
随后,研究人员还设计了新的编码器解码器架构,对深度重建任务进行训练,抽取深度图中具有代表性的特征。用编码器和解码器中间的压缩结构对特征的维度进行了浓缩和进一步抽取,让网络去捕捉最具代表性的特征,同时避免网络直接记忆输入深度图输出一致的深度图。这一嵌入抽取器被定义为了HEG-R,会被在后文中用于最终的损失计算,下表为重建过程的编码器架构。
通过间接任务,获取到度量估计结果与目标差异的分层嵌入抽取器HEG-R/HEG-S后,研究人员开始正式构建深度估计网络。
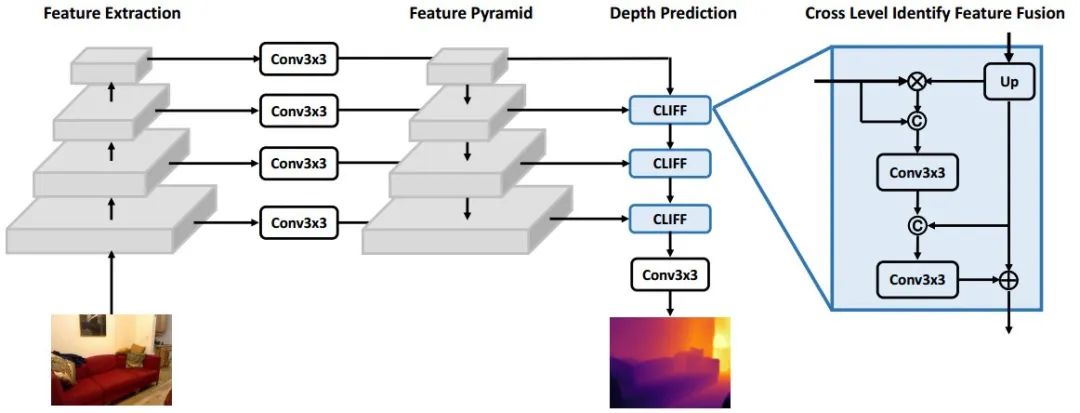
这一全卷积网络架构包含了特征抽取、特征金字塔和深度估计三个主要部分。
特征抽取子网络直接从单张RGB图像中抽取多尺度特征,并通过跳接层将特征传递给后续的特征金字塔部分。最后的深度估计子网络将基于特征金字塔进行深度估计。下图显示了模型的完整结构:
为了充分利用特征金字塔的信息,一些方法直接对高层特征进行上采样与底层特征进行融合。虽然高层特征非常鲁棒,但这种直接上采样的方式会使得预测结果很模糊。另类方法是渐进式地融合特征,将高层特征逐渐地进行上采样,并与相应尺度的低层级特征进行融合。但这种方法受到底层特征较大的影响,而底层特征在很多场景下并不稳定。为了有效解决特征融合的问题,研究人员提出了
用CLIFF模块来融合不同层级的特征。
为了有效融合更为可靠的高层级特征和分辨率更高的底层特征,
CLIFF采用了注意力机制来实现融合,强化底层特征的稳定性。
这一模块输入高级特征和低级特征,并将高级特征上采样到低级特征对应的大小,通过相乘的方式实现注意力,从而得到增强后的低层特征。随后,为了对高层特征、原始低层特征和优化后的低层特征进行有效融合,
引入了额外两个卷积来对其进行处理和组合。
第一个卷积层通过输入原始的和优化后的低层特征来对低层特征进行选择与融合;随后输出与高层特征合并后输入到第二个卷积层中进一步融合低层与高层特征图。最后,为了便于梯度的传输、保留高层语义信息,将低层特征Fl和高层特征Fh直接相加获得恒等变化Fo。其公式定义如下图所示:
经过多个CLIFF模块的处理,最终获得的特征被馈入到卷积层中进行深度估计。
在获取深度后,模型的损失函数由先前获取的嵌入(特征)生成器进行计算,通过HEG-S 和 HEG-R加权计算出最终的不同层级的损失结果:
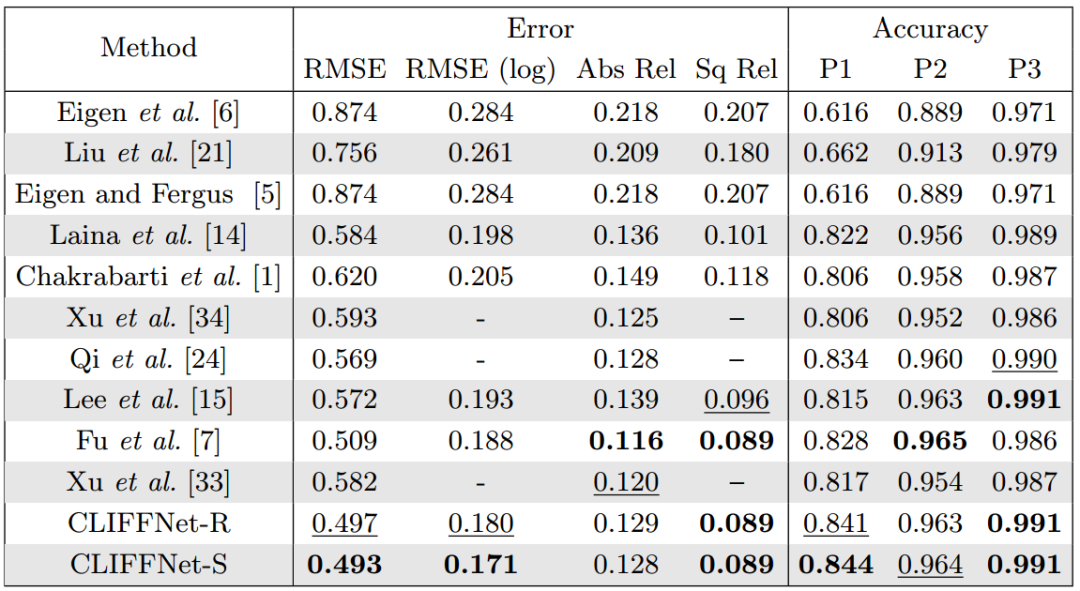
研究人员在NYUv2和Cityscapes上训练了CLIFFNet,以36.89M的参数在1080TI上实现了37.86FPS的速度。具体的性能见下表所示 (CLIFFNet-R/CLIFFNet-S分别在训练过程中使用了HEG-R/HEG-S获取分层嵌入损失) :
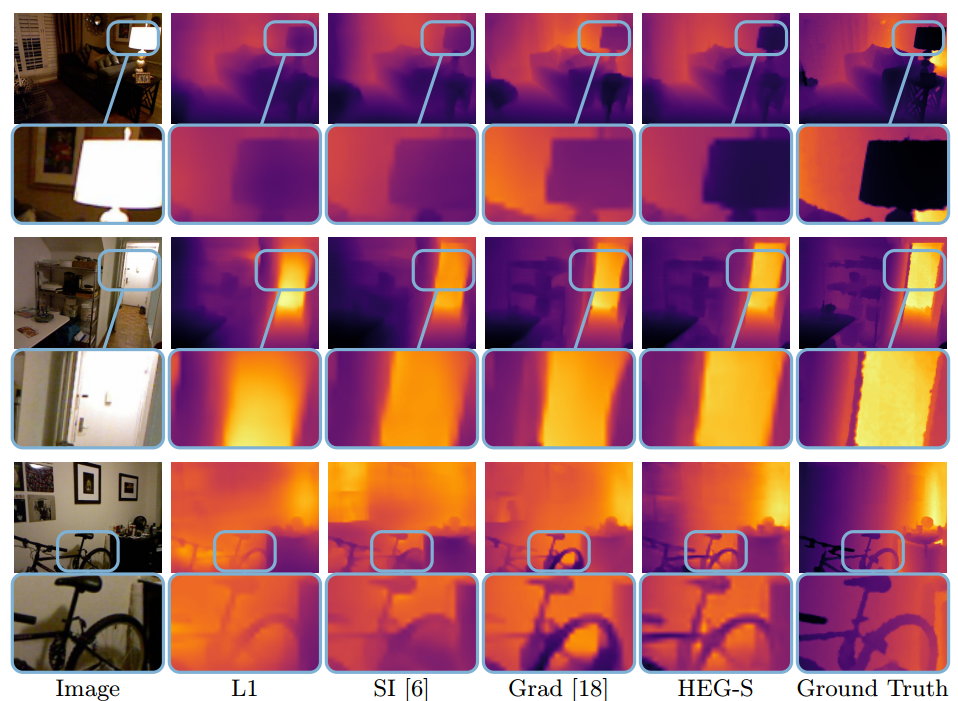
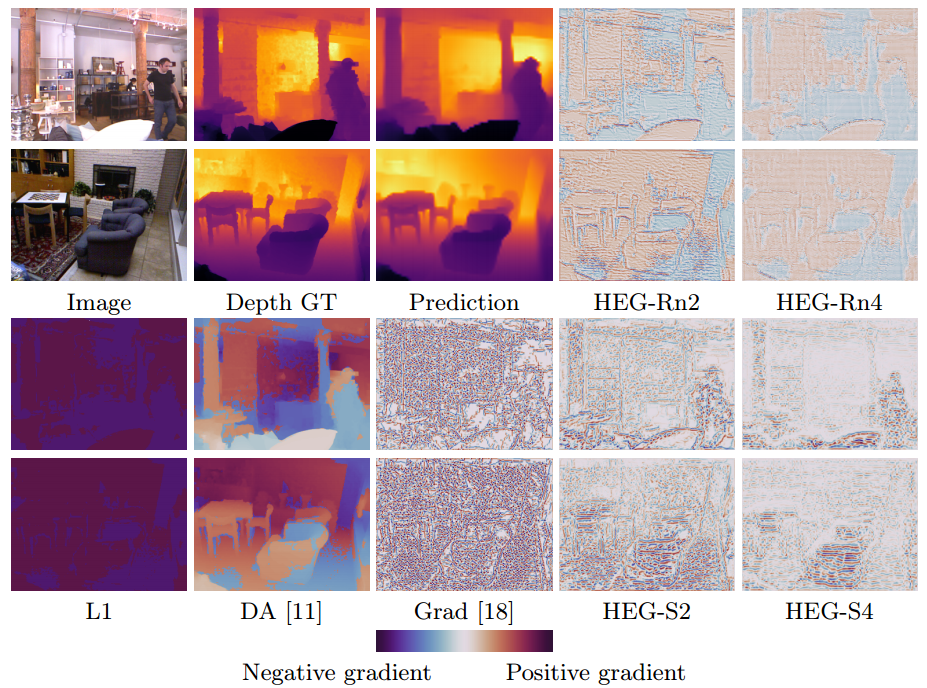
下图显示了与各种算法的性能比较,可以看到
这种方法得到的深度图细节更为丰富准确,超过了其他先进的深度估计算法
:
通过下图,还能详细地比较模型不同嵌入层提取出的损失图:
re:
http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123500307.pdf
https://kinsta.com/blog/embed-google-form/
https://unbabel.com/blog/why-humans-speak-7000-languages/
下载:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()