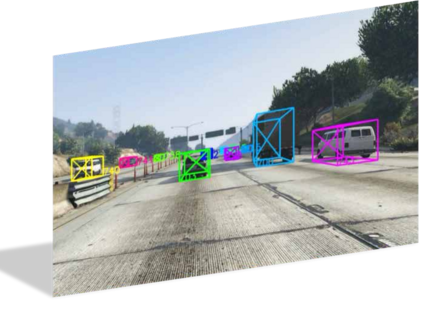
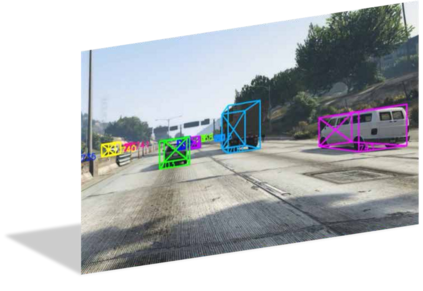
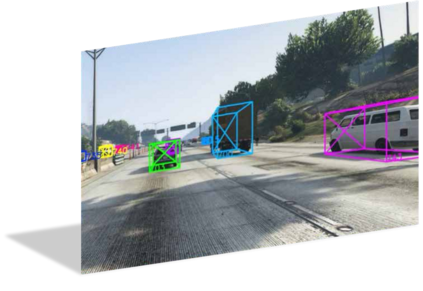
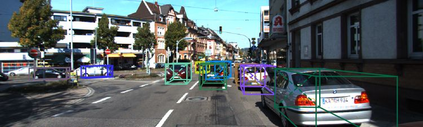
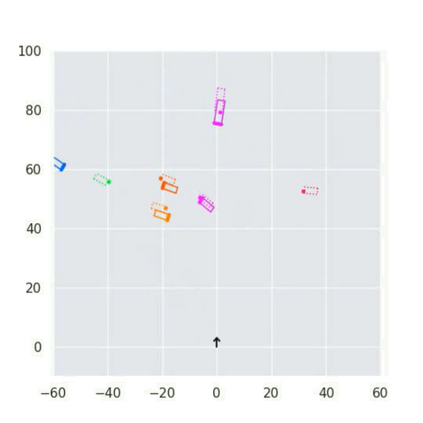
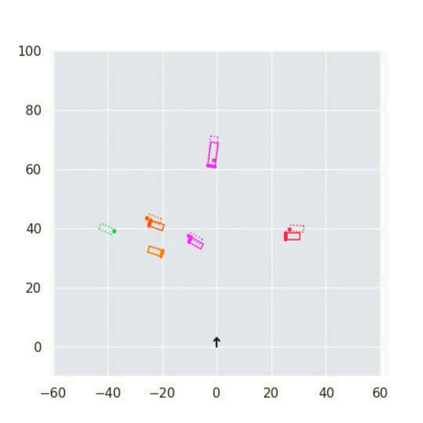
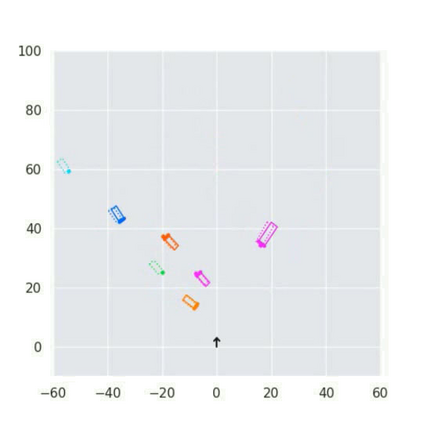
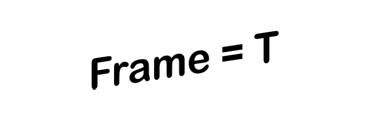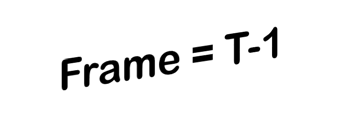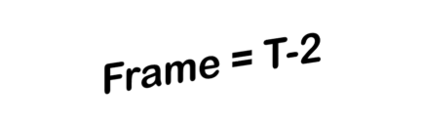3D vehicle detection and tracking from a monocular camera requires detecting and associating vehicles, and estimating their locations and extents together. It is challenging because vehicles are in constant motion and it is practically impossible to recover the 3D positions from a single image. In this paper, we propose a novel framework that jointly detects and tracks 3D vehicle bounding boxes. Our approach leverages 3D pose estimation to learn 2D patch association overtime and uses temporal information from tracking to obtain stable 3D estimation. Our method also leverages 3D box depth ordering and motion to link together the tracks of occluded objects. We train our system on realistic 3D virtual environments, collecting a new diverse, large-scale and densely annotated dataset with accurate 3D trajectory annotations. Our experiments demonstrate that our method benefits from inferring 3D for both data association and tracking robustness, leveraging our dynamic 3D tracking dataset.
翻译:3D 车辆探测和跟踪从一个单筒相机中发现和跟踪3D 车辆需要探测和联系车辆,并一起估计车辆的位置和范围。它具有挑战性,因为车辆不断运动,几乎不可能从一个图像中恢复3D位置。在本文件中,我们提出了一个新的框架,共同探测和跟踪3D 车辆捆绑箱。我们的方法利用3D 进行估算,以学习2D 补丁关系超时,并利用从跟踪中获取的时间信息以获得稳定的 3D 估计。我们的方法还利用 3D 盒深度命令和运动,将隐蔽物体的轨迹连接起来。我们用现实的 3D 虚拟环境来培训我们的系统,收集一个新的多样化的、大型的和密集的附加说明3D 轨迹的新的数据集。我们的实验表明,我们的方法从推断3D 数据组合和跟踪稳健中,利用动态 3D 跟踪数据集,从中得益。