涨点明显!港中文等提出SplitNet:结合Co-Training提升CNN性能
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达


本文除了讨论了众所周知的深度/宽度/分辨率之外,还提出网络的"数目"应该是有效模型缩放的新维度。也因此提出了SplitNet;据作者称,这是首次提出此类讨论的工作,可引入现有CNN网络中(如EfficientNet、SE-ResNet等),涨点明显!
作者单位:港中文, AIRS, 浙江大学
1、简介
神经网络的宽度很重要,因为增加宽度必然会增加模型的容量。但是,网络的性能不会随着宽度的增加而线性提高,并且很快就会饱和。
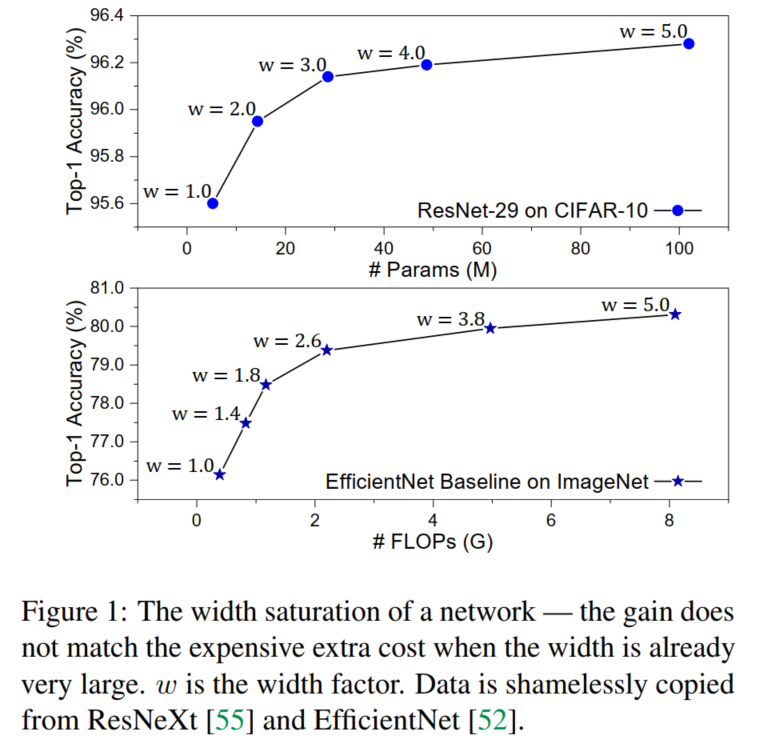
为了解决这个问题,作者提出增加网络的数量,而不是单纯地扩大宽度。为了证明这一点,将一个大型网络划分为几个小型网络,每个小型网络都具有原始参数的一小部分。然后将这些小型网络一起训练,并使它们看到相同数据的各种视图,以学习不同的补充知识。在此共同训练过程中,网络也可以互相学习。
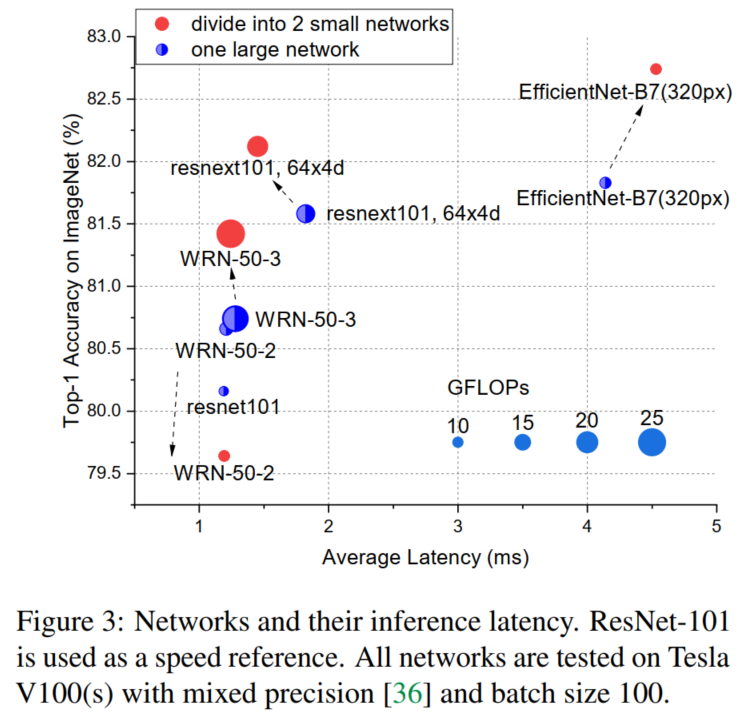
实验结果表明,与没有或没有额外参数或FLOP的大型网络相比,小型网络可以获得更好的整体性能。这表明,除了深度/宽度/分辨率之外,网络的数量是有效模型缩放的新维度。通过在不同设备上同时运行,小型网络也可以比大型网络实现更快的推理速度。
2、相关工作
2.1 神经网络结构设计
自从AlexNet的得到非常好的效果以后,深度学习方法便成为计算机视觉领域的主导,神经网络设计也成为一个核心话题。AlexNet之后出现了许多优秀的架构,如NIN、VGGNet、Inception、ResNet、Xception等。很多研究者设计了高效的模型,如1*1卷积核、用小核堆叠卷积层、不同卷积与池化操作的组合、残差连接、深度可分离卷积等。
近年来,神经网络结构搜索(NAS)越来越受欢迎。人们希望通过机器学习方法自动学习或搜索某些任务的最佳神经结构。在这里只列举几个,基于强化学习的NAS方法、渐进式神经架构搜索(PNASNet)、可微分架构搜索(DARTS),等等。
2.2 协同学习
协同学习最初是教育中的一个总称,指的是学生或教师共同努力学习的教育方法。它被正式引入深度学习中,用来描述同一网络中多个分类器同时训练的情况。
然而,按照其最初的定义,涉及两种或两种以上模型共同学习的作品,也可以称为协作学习,如深度相互学习(deep mutual learning, DML)、联合训练、互意教学、合作学习、知识蒸馏等。虽然有不同的名字,但核心思想是相似的,即通过一些同伴或老师的训练来提高一个或所有的模型的性能。
3、本文方法
这里先简单回顾了常用的深度图像分类框架。给定一个神经网络模型M和N个训练样本有C类,训练M模型最常用的损失函数是交叉熵损失函数:
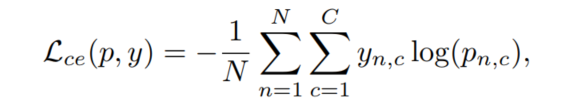
其中y为ground truth label;p为估计概率,通常由M的最后softmax层给出。
3.1 分割模型
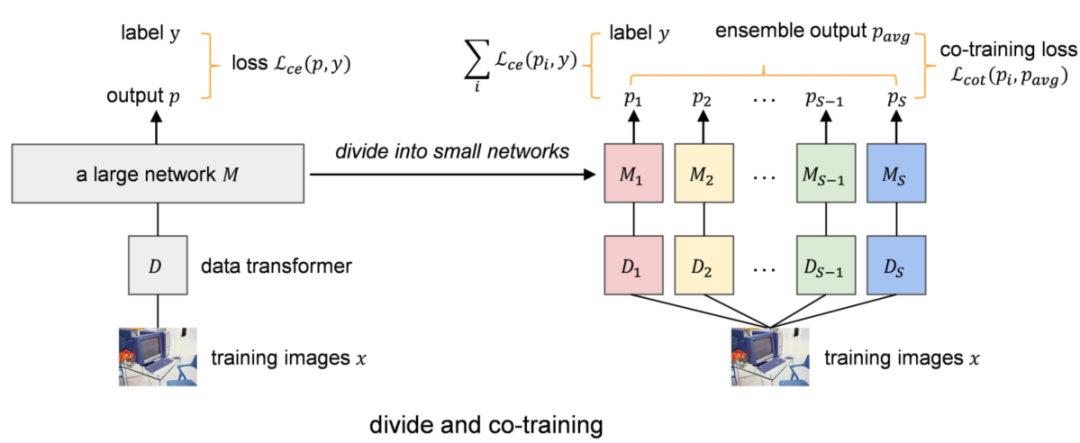
上图中根据网络的宽度将一个大网络M划分为S个小网络 。当按宽度划分时,实际上指的是按参数量或FLOPs划分。
3.1.1、如何计算参数量和FLOPs?
例如,如果要把M分成两个网络 , 或 的参数数量应该大约是 的一半。这里给出计算神经网络的参数和FLOPs的方法。
通常是卷积层的累加,因此在这里只讨论如何计算一个卷积层的参数量和FLOPs。在PyTorch的conv-layer的定义中,其卷积核大小是 ,输入和输出通道的特征图为 和 , d为累加卷积的数量,这意味着每 个输入通道将与 的卷积核进行卷积。在这种情况下,这个conv-layer的参数量(Params)和FLOPs:
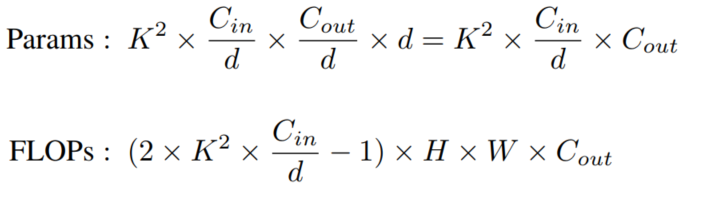
其中 是输出特征图的大小,-1是因为 次加法只需要 次操作。为了简洁起见,省略了偏差。对于Depthwise卷积来说 。
3.1.2、如何切分网络?
通常 ,其中 为常数。因此,如果想通过除以因子S来分割卷积层,只需要用 除以 :
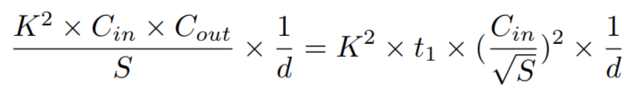
1)切分ResNet
举例如下:如果我们想分割一个ResNet的Bottleneck Block:
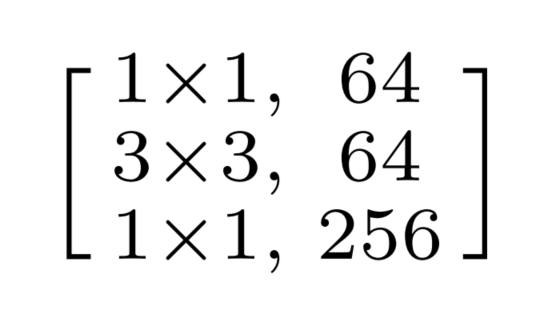
通过除以2可以得到如下的4个小的Blocks:
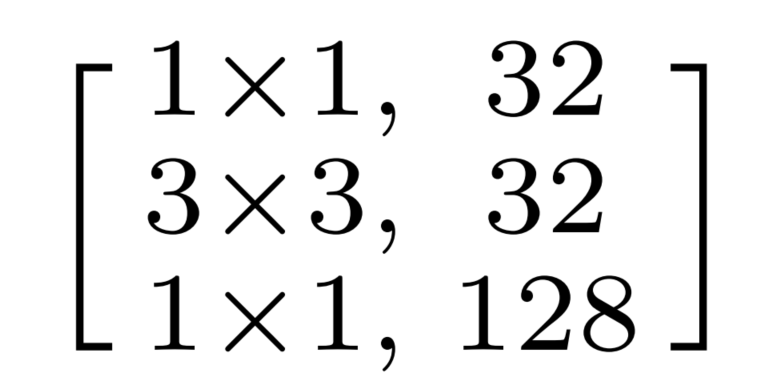
这里每个Block只有原来Block的四分之一的参数量和FLOPs。
在实际应用中,网络中特征映射的输出通道数具有最大公约数(GCD)。大多数ResNet变体的GCD是第一卷积层的 。对于其他网络,比如EfficienctNet,他们的GCD是8或者其倍数。一般来说,当想一个网络切分为S块时,只需要找到它的GCD,然后用 就可以了。
# The below is the same as max(widen_factor / (split_factor ** 0.5) + 0.4, 1.0)
if arch == 'wide_resnet50_2' and split_factor == 2:
self.inplanes = 64
width_per_group = 64
print('INFO:PyTorch: Dividing wide_resnet50_2, change base_width from {} '
'to {}.'.format(64 * 2, 64))
if arch == 'wide_resnet50_3' and split_factor == 2:
self.inplanes = 64
width_per_group = 64 * 2
print('INFO:PyTorch: Dividing wide_resnet50_3, change base_width from {} '
'to {}.'.format(64 * 3, 64 * 2))
2)切分ResNeXt
对于ResNeXt网络,当 固定时,即 ,其中 为常数,则式上一个等式需要变化为:
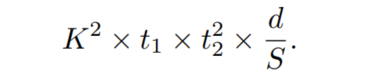
这意味着只需要通过channel数量除以 便可以得到d组小的Block。
self.dropout = None
if 'cifar' in dataset:
if arch in ['resnext29_16x64d', 'resnext29_8x64d', 'wide_resnet16_8', 'wide_resnet40_10']:
if dropout_p is not None:
dropout_p = dropout_p / split_factor
# You can also use the below code.
# dropout_p = dropout_p / (split_factor ** 0.5)
print('INFO:PyTorch: Using dropout with ratio {}'.format(dropout_p))
self.dropout = nn.Dropout(dropout_p)
elif 'imagenet' in dataset:
if dropout_p is not None:
dropout_p = dropout_p / split_factor
# You can also use the below code.
# dropout_p = dropout_p / (split_factor ** 0.5)
print('INFO:PyTorch: Using dropout with ratio {}'.format(dropout_p))
self.dropout = nn.Dropout(dropout_p)
3.1.3、权重衰减
对于权重衰减问题,由于其内在机理尚不清楚,所以有一点复杂。本工作中使用了2种划分策略:无划分和指数划分:
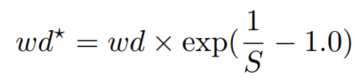
其中 为原权重衰减值, 为除法后的新权重值。不除意味着权重衰减值保持不变。如上所述,权重衰减的潜在机制尚不清楚,因此很难找到最佳的、普遍的解决方案。以上两种划分策略只是经验标准。在实践中,现在最好的方法是尝试。
3.1.4、小型网络的并发运行
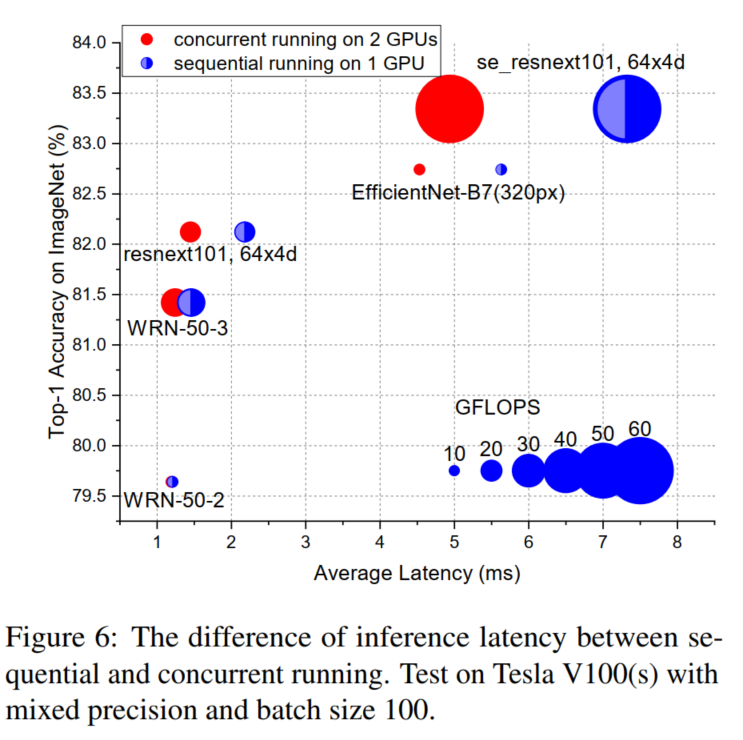
尽管小网络具有更好的集成性能,但在大多数情况下,小网络也可以通过在不同的设备上部署不同的小型模型,并且通过并发运行来实现比大网络更快的推理速度。如图所示。
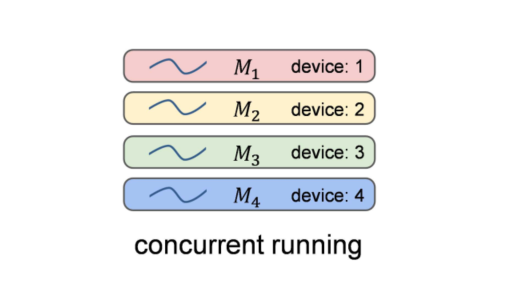
典型的设备是NVIDIA的GPU。理论上,如果一个GPU有足够的处理单元,例如流处理器、CUDA核等,小型网络也可以在一个GPU内并发运行。然而,一个小的网络已经能够占用大部分的计算资源,不同的网络只能按顺序运行。因此,本文只讨论多设备的方式。
小网络并发推理的成功也表明了训练并发性的可能性。目前,小网络在训练过程中是按顺序运行的,导致训练时间比大网络长。
然而,设计一个灵活的、可伸缩的框架是相当困难的,它能够支持在多个设备上对多个模型进行异步训练,并且在前向推理和反向传播的过程中也需要进行通信。
3.2 联合训练
一个大网络M分割后变成S个小网络。现在的问题是如何让这些小网络从数据中学习不同的互补知识。在引入联合训练部分之前,强调划分和联合训练的设计只是为了说明增加网络数量是有效模型缩放的一个新维度的核心思想。
而联合训练部分是由deep mutual learning(DML)、co-training和mutual mean-teaching(MMT)所启发的。
不同的初始化方式和数据views
一个基本的理解是学习一些相同的网络是没有意义的。相比之下,小型网络则需要学习有关数据的互补的知识,以获得一个全面的数据理解。
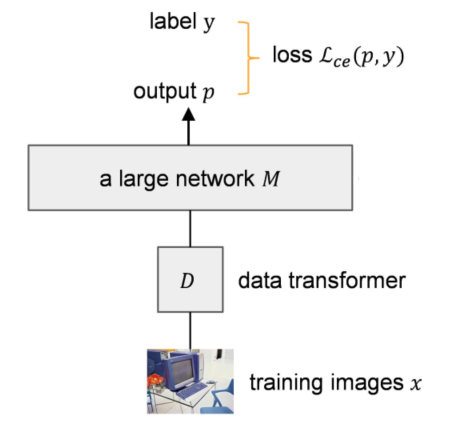
为此,首先,对小网络进行不同权值的初始化。然后,在输入训练数据时,对不同网络 的相同数据使用不同的数据转换器 ,如上图所示。这样,小模型 便可以在不同的变换域下 进行学习和训练。
在实际应用中,不同的数据域是由数据增广随机性产生的。除了常用的随机调整/剪切/翻转策略外,作者还进一步介绍了随机擦除和AutoAugment 策略。AutoAugment 有14个图像变换操作,如剪切,平移,旋转,自动对比度等。该算法针对不同的数据集搜索了几十种由两种转换操作组成的策略,并在数据扩充过程中随机选择一种策略。
源码如下:
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
CIFAR10Policy(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)),
transforms.RandomErasing(p=erase_p,
scale=(0.125, 0.2),
ratio=(0.99, 1.0),
value=0, inplace=False),
])
3.3 联合训练损失函数
遵循半监督学习中共同训练的假设,小网络虽然对 的view不同,但对x的预测是一致的:
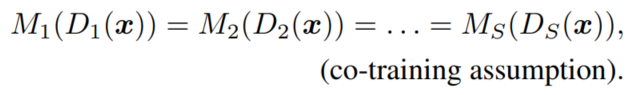
因此,在目标函数中加入预测概率分布之间的Jensen-Shannon(JS)散度,即联合训练损失函数:
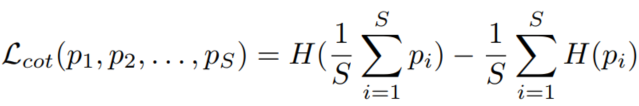
其中 是一个小网络 的估计概率, 是分布p的Shannon熵。联合训练损失也用于DML中,但具体形式不同,即DML使用的是两种预测之间的KullbacLeibler(KL)散度。通过这种联合训练的方式,一个网络还可以从它的同伴那里学到一些有价值的东西,因为预测的概率包含有关于物体的有意义的信息。
例如,一个将一个物体分类为Chihuahua的model可能也会对Japanese spaniel有很高的信心,因为它们都是狗。这是有价值的信息,定义了对象上丰富的相似结构。
总体目标函数为:
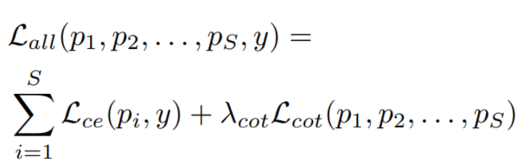
式中, 是通过交叉验证选择 权重因子。
损失函数源码如下:
def _co_training_loss(self, outputs, loss_choose, epoch=0):
"""calculate the co-training loss between outputs of different small networks
"""
weight_now = self.cot_weight
if self.is_cot_weight_warm_up and epoch < self.cot_weight_warm_up_epochs:
weight_now = max(self.cot_weight * epoch / self.cot_weight_warm_up_epochs, 0.005)
if loss_choose == 'js_divergence':
# the Jensen-Shannon divergence between p(x1), p(x2), p(x3)...
# https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence
outputs_all = torch.stack(outputs, dim=0)
p_all = F.softmax(outputs_all, dim=-1)
p_mean = torch.mean(p_all, dim=0)
H_mean = (- p_mean * torch.log(p_mean)).sum(-1).mean()
H_sep = (- p_all * F.log_softmax(outputs_all, dim=-1)).sum(-1).mean()
cot_loss = weight_now * (H_mean - H_sep)
else:
raise NotImplementedError
return cot_loss
4、实验
4.1、各个Backbone的增益
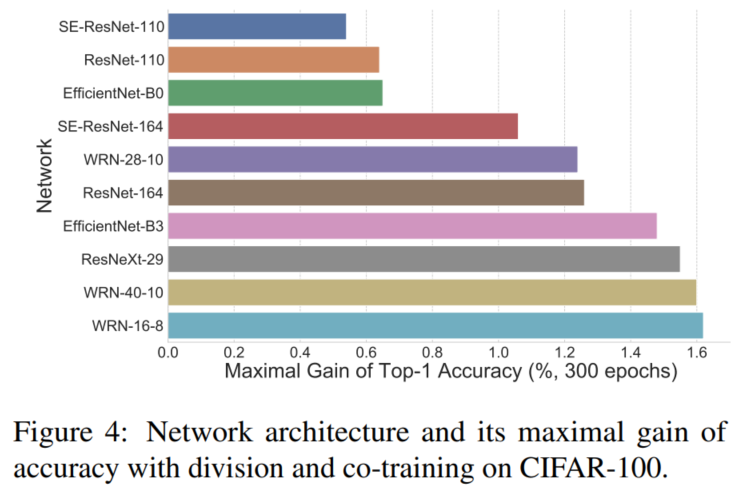
通过上图可以看出:增加网络的数量比单纯增加网络的宽度/深度更有效。
4.2、性能对比
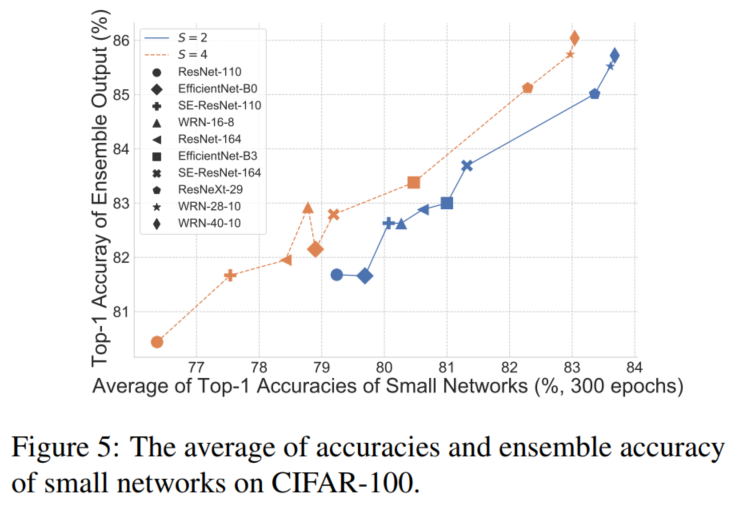
通过上图可以看出:整体性能与个体性能密切相关。
4.3、CIFAR-100实验结果
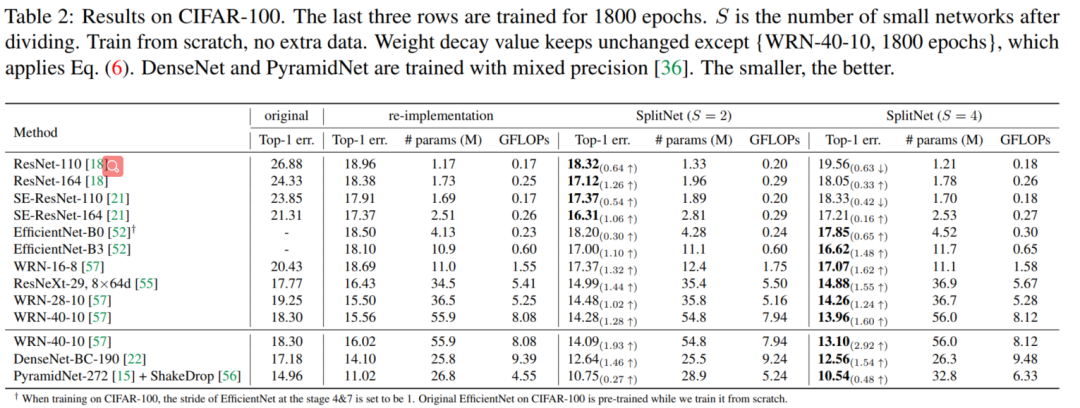
通过上表可以看出:必要的网络宽度/深度很重要。
4.4、序列和并发之间的推断延迟实验
参考:
[1].SplitNet: Divide and Co-training
[2].https://github.com/mzhaoshuai/SplitNet-Divide-and-Co-training
上述论文和代码下载
后台回复:SplitNet,即可下载上述论文PDF和项目源代码
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4000人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!

