深度强化学习在NLP怎么用?看清华黄民烈老师这一份120页《自然语言处理和搜索中的深度强化学习应用》讲义
【导读】深度强化学习(Deep Reinforcement Learning - DRL)是机器学习领域发展迅速的一类算法,广泛应用在决策类任务中,如AlphaGo、Dota等。近几年DRL在计算机视觉和自然语言处理上得到广泛的探索应用。清华大学黄民烈老师在第七届全国社会媒体处理大会上做了《深度强化学习及其在自然语言处理中的应用》的讲习报告,详细介绍了强化学习自然语言处理的常见应用场景,非常前沿细致,值得做这一方向工作的同学好好研读。

黄民烈,清华大学计算机系副教授,博士生导师,计算机系人工智能研究所副所长。研究兴趣主要集中在人工智能、深度学习、强化学习,自然语言处理如自动问答、人机对话系统、情感与情绪智能等。已超过60篇CCF A/B类论文发表在ACL、IJCAI、AAAI、EMNLP、KDD、ICDM、ACM TOIS、Bioinformatics、JAMIA等国际顶级和主流会议及期刊上。曾担任多个国际顶级会议的领域主席或高级程序委员,如AAAI 2019、IJCAI 2018、IJCAI 2017、ACL 2016、EMNLP 2014/2011,IJCNLP 2017等,担任ACM TOIS、TKDE、TPAMI、CL等顶级期刊的审稿人。作为负责人或学术骨干,负责或参与多项国家973、863子课题、多项国家自然科学基金,并与国内外知名企业如谷歌、微软、三星、惠普、美孚石油、斯伦贝谢、阿里巴巴、腾讯、百度、搜狗、美团等建立了广泛的合作。获得专利授权近10项,其中2项专利技术授权给企业应用。
个人主页:
http://coai.cs.tsinghua.edu.cn/hml/
《自然语言处理和搜索中的深度强化学习应用》简介

深度强化学习在以Alpha GO/Zero为代表的许多应用中取得了前所未有的成功,其广泛地应用在游戏控制、机器人、自动驾驶、语言交互等场景中。强化学习的序列决策、尝试试错、延迟奖励等特点,使得其处理非直接信号的弱监督学习问题具有较强的优势。本讲座将首先介绍强化学习的基本理论,并介绍Q-Learning、策略梯度、Actor-Critic三大主要的方法;其次,将介绍强化学习在自然语言处理中的常见应用场景,包括其信息抽取、关系预测、样本去噪、标记纠正、结构探索、搜索策略优化等。这些工作具有的共性是:在无直接监督信息、弱信号场景中,利用强化学习的试错和概率探索能力,通过编码先验或领域知识,达到学习目标。
请上黄老师主页获取讲义PPT或者
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“RL4NLP” 就可以获取《自然语言处理和搜索中的深度强化学习应用》PPT下载链接~
《自然语言处理和搜索中的深度强化学习应用》导读
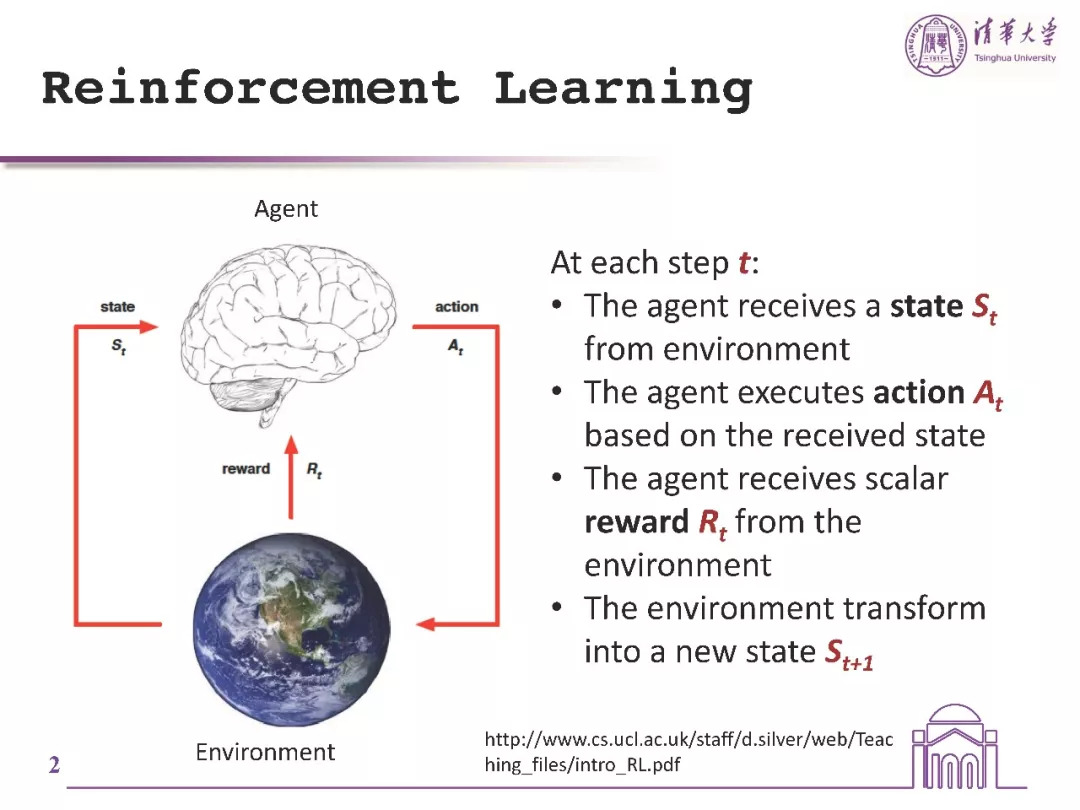
强化学习的基本概念
状态,是agent从环境中得到的动作;agent,是基于它得到的当前状态后做出相应的动作。reward ,是环境给agent 的一个反馈,收到这个reward就知道做的这个动作是好还是不好。agent 的目标就是选动作,将全部reward最大化。
agent会和环境做很多的交互,环境每次做的动作可能会有一个长期的影响,而不仅仅是影响当前的reward。reward 也有可能延迟。在这里简单介绍一下policy的概念。policy是决定一个agent的动作的一个函数。

强化学习是进行序列决策,当前决策会影响未来决策。通过尝试试错的方式来完成,最大化未来收益为目标。

在自然语言处理中应用强化学习的挑战:离散符号、稀疏收益、高维度动作空间、在训练的高方差。为此,强化学习的优势包括无需显性标注的弱监督,尝试试错机制、累积奖赏。

为什么RL能应用到NLP上?学习搜索和推理,直接优化最终的评价指标,使得离散才做 BP可行。

应用任务:搜索和推理,实例选取,策略优化

在搜索和推理方面包括以上代表性论文。NAACL’16的最佳论文[NAACL’16_compose]用RL来构建QA系统,他们定义了求解QA任务的各种操作模块,学出不同模块的组装方式;[ICLR’17_architecture]用REINFORCE算法学习自动设计神经网络架构,将所构造的NN模型在任务上的精度作为reward;[arXiv’17_walk]将RL用于搜索推理路径。[AAAI’18_structured]利用强化学习来识别文本中有用的结构,将action定为对每个词的删除或保留决策。其模型结构为:对给定文本输入,利用Policy Network判断其每个词的去留,将action序列作为表示模型的输入生成对句子的表示向量,再将该向量作为分类网络的输入产生文本分类结果,分类器在文本分类任务上的评价效果即可作为reward反馈给Policy Network。

在实例选取上有以上代表性论文。[EMNLP’17_active]学习对未标记数据做筛选,选出对特定任务模型训练有用的句子,采用deep Q-learning用于RL优化; [NAACL’18_co-training]在cotraining中用RL来判断由一个分类器产生的标记数据是否适用于作为另一分类器的训练数据; [2017_what]考虑到随机梯度下降过程中data batch的顺序非常重要,于是用强化学习REINFORCE算法训练模型来选择data batch;[AAAI’18_noisy]用RL来识别noisy的标记数据,对训练数据做降噪处理,将在清理过的数据上训练出的分类器的效果作为reward;[IJCAI’18_goal-oriented]在对话序列的topic标记场景中同样存在的noisy标记问题,该工作从noisy labeled data中学出policy用于纠正错误标注的label,并借助更新后的数据优化policy。

在策略优化方面,[arXiv’15_turing]用RL训练能够解决简单算法任务的神经网络;[EMNLP’17_simplification]将RL用于语言生成任务;[EMNLP’16_dialogue]考虑对话系统中的文本生成问题,一系列对话交互构成的序列可以用MDP建模,用RL来完成语言生成任务,其中action为生成的对话句子文本,由于可以生成任意长度的句子,动作空间可以看作是无限大的;[EMNLP’17_compose]利用层次化的RL来建模多个子任务间的切换方式;


总结-RL在NLP成功应用的关键点:形式化任务为一个自然决策的问题,记得尝试试错机制,在奖赏机制中融入领域知识,应用在很多弱监督中。

一些重要经验:warm-start非常重要,由于存在大量局部最优以及reward的稀疏性,在使用RL时有必要做pre-training;在完全可监督的场景,以及action space非常巨大的任务中,RL能带来的提升有限,因此选择合适的任务以及合理建模很重要;此外,模型训练过程中要会使用一些training tricks。

未来研究方向:层次化的深度强化学习、逆强化学习,以及采样有效性,是RL未来的发展方向。
参考链接:
http://ws.nju.edu.cn/blog/2018/08/
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知





