深度学习模型剪枝:Slimmable Networks三部曲
加入极市专业CV交流群,与10000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:Kylin
https://zhuanlan.zhihu.com/p/105064255
本文已由作者授权转载,未经允许,不得二次转载。
0.背景介绍
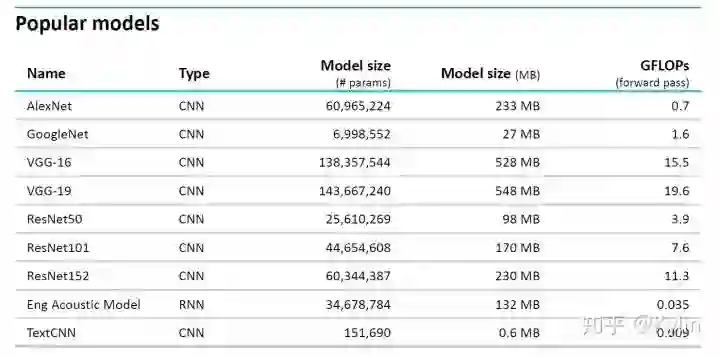
 0.3GFLOPs),同时占用全部算力资源,也只能勉强达到(12~16)/0.3 = 40~53FPS。这是非常理想的条件下才能实现的,所以常规的深度学习模型更难以部署到嵌入式设备上。
0.3GFLOPs),同时占用全部算力资源,也只能勉强达到(12~16)/0.3 = 40~53FPS。这是非常理想的条件下才能实现的,所以常规的深度学习模型更难以部署到嵌入式设备上。
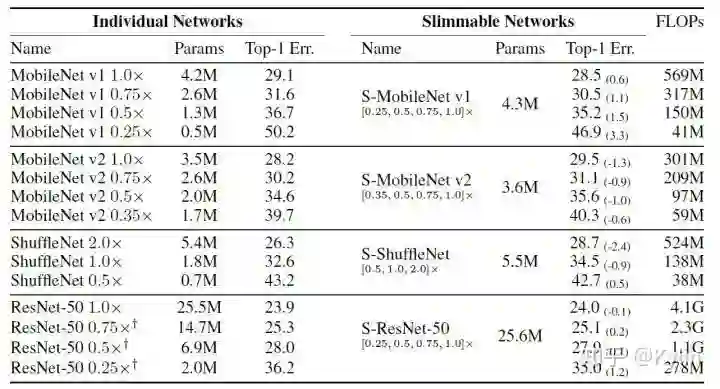
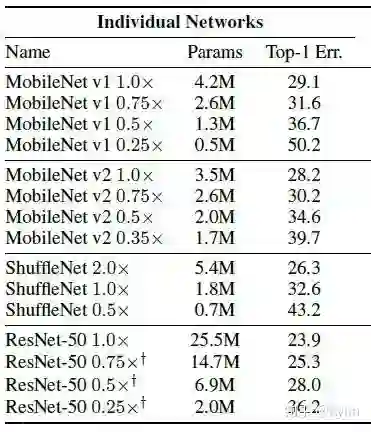
1. SLIMMABLE NEURAL NETWORKS
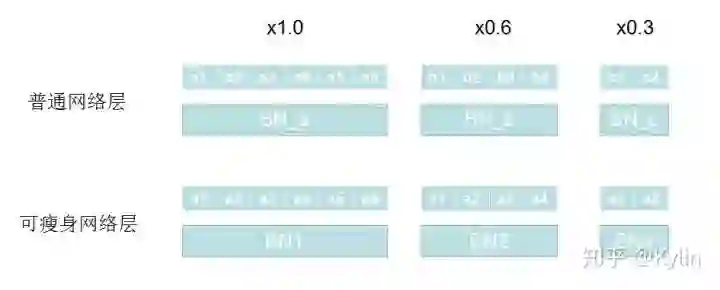
 。而可瘦身网络层对于不同宽度乘子,都共享一组参数进行训练。例如当乘子为1.0的时候,网络层参数为
。而可瘦身网络层对于不同宽度乘子,都共享一组参数进行训练。例如当乘子为1.0的时候,网络层参数为
 ;当乘子为0.6和0.3时,网络层参数分别为
;当乘子为0.6和0.3时,网络层参数分别为
 和
和
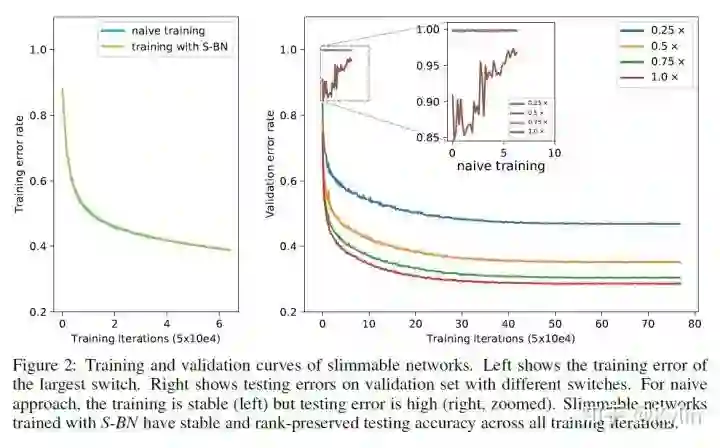
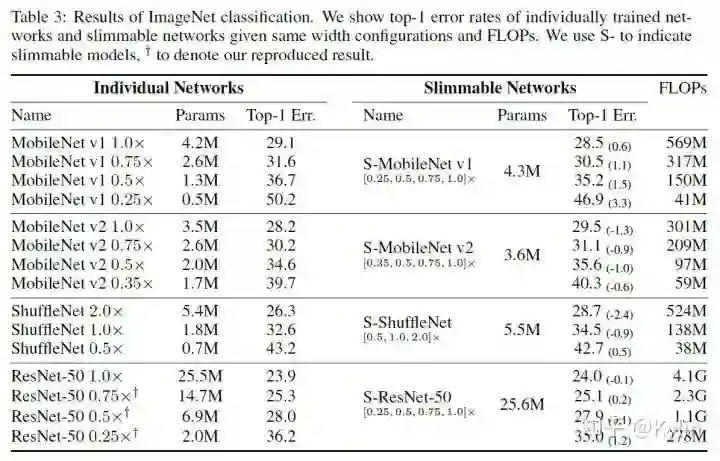
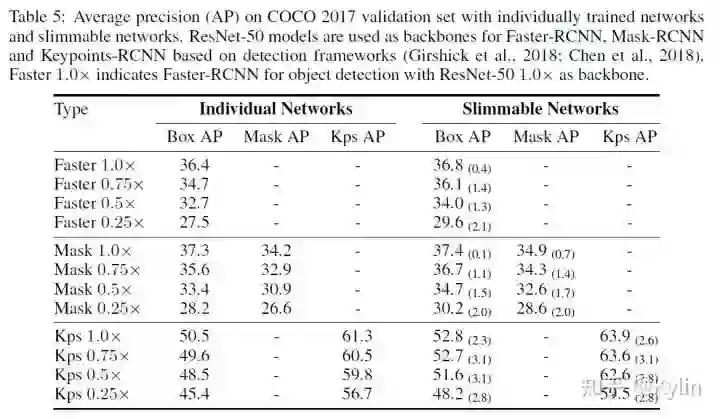
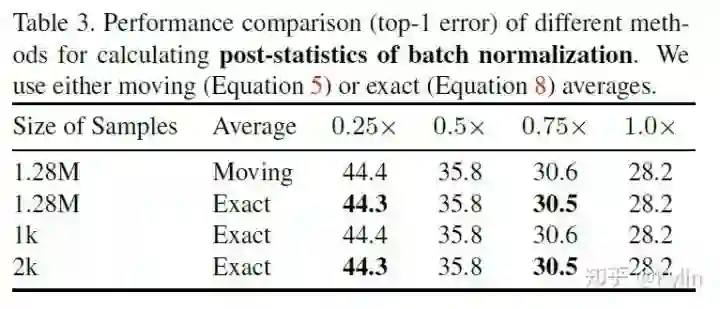
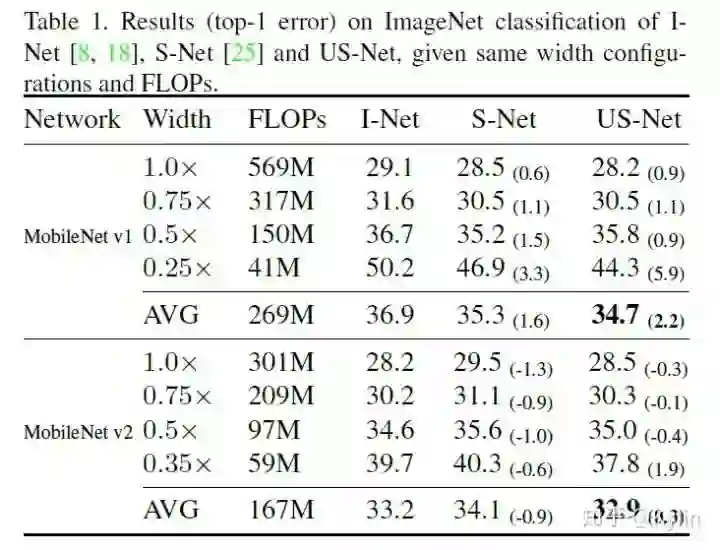
 。细心一点可以发现,这里使用共享参数的时候,索引越靠前的参数被共享的次数越多。所以瘦身网络层内置地对网络层的通道做了一个重要性排序,个人觉得这种排序机制还有很多细节可以探究的。还有一个重要的点:虽然可瘦身网络共享了参数,但是BN层针对不同的乘子设置是单独计算的。因为不同乘子设置条件下,输出的feature map分布有明显差异,通过公共的BN层统计出来的means和variances在模型推理的时候会导致严重偏差。这个问题至关重要,论文里面也做了详细的探究,结果如下图:
。细心一点可以发现,这里使用共享参数的时候,索引越靠前的参数被共享的次数越多。所以瘦身网络层内置地对网络层的通道做了一个重要性排序,个人觉得这种排序机制还有很多细节可以探究的。还有一个重要的点:虽然可瘦身网络共享了参数,但是BN层针对不同的乘子设置是单独计算的。因为不同乘子设置条件下,输出的feature map分布有明显差异,通过公共的BN层统计出来的means和variances在模型推理的时候会导致严重偏差。这个问题至关重要,论文里面也做了详细的探究,结果如下图:

2. Universally Slimmable Networks and Improved Training Techniques
 ,其中
,其中
 为输出,
为输出,
 和
和
 分别为上一层卷积核权重和输入特征图,
分别为上一层卷积核权重和输入特征图,
 为输入的通道数量。
满足如下性质:
为输入的通道数量。
满足如下性质:
 ,其中
,其中
 为前k个通道的加权和输出,即
为前k个通道的加权和输出,即
 。其中
。其中
 是人为指定的一个常量超参数,例如
是人为指定的一个常量超参数,例如
 。(*这里应该是向上取整符号,但是我没有找到知乎的编辑方法*)
。(*这里应该是向上取整符号,但是我没有找到知乎的编辑方法*)

 是ground truth。不等式(2)的第一部分
是ground truth。不等式(2)的第一部分
 表明了一个跟
相关的下界的存在。同时,考虑到ground truth的存在,通俗的来讲,当给定
的时候,
处在一个已经被界定的范围内。不等式(2)的第二部分
表明了一个跟
相关的下界的存在。同时,考虑到ground truth的存在,通俗的来讲,当给定
的时候,
处在一个已经被界定的范围内。不等式(2)的第二部分
 其实是一个关于
其实是一个关于
 的递推不等式。我认为这个关系是支持算法成立最核心的地方。这个地推不等式表明,使用更多的卷积通道,能获得更接近ground truth的性能。最后概括起来描述,给定了
之后,可瘦身网络层的输出结果处在一个已界定的范围内,并且可以通过增删通道数量来直接调控网络层的性能和资源消耗之间的关系。上面的论证是针对于单个网络层来考虑的,实际上,这个结论也适用于整个网络模型。
的递推不等式。我认为这个关系是支持算法成立最核心的地方。这个地推不等式表明,使用更多的卷积通道,能获得更接近ground truth的性能。最后概括起来描述,给定了
之后,可瘦身网络层的输出结果处在一个已界定的范围内,并且可以通过增删通道数量来直接调控网络层的性能和资源消耗之间的关系。上面的论证是针对于单个网络层来考虑的,实际上,这个结论也适用于整个网络模型。
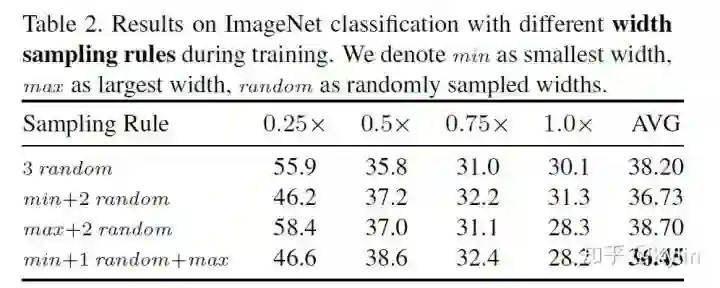

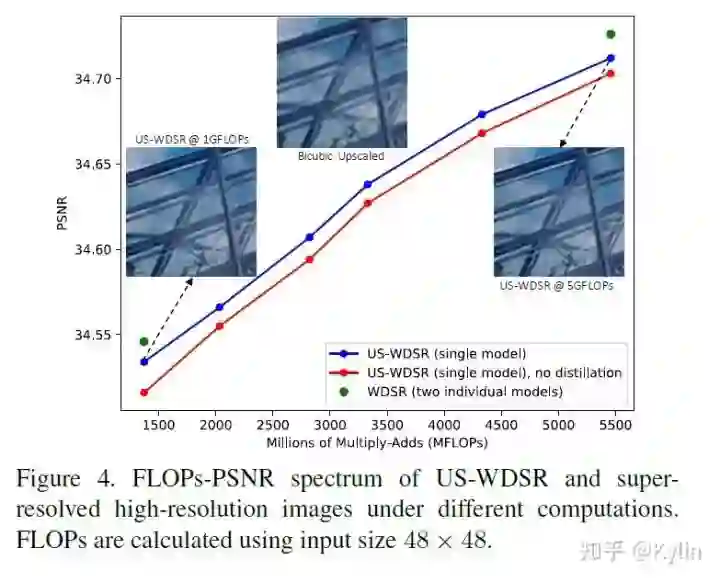
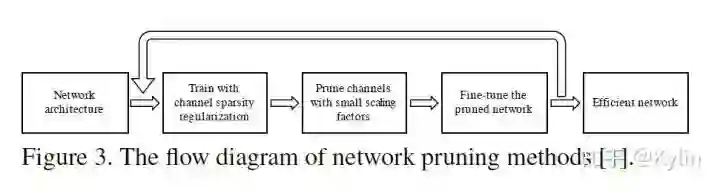
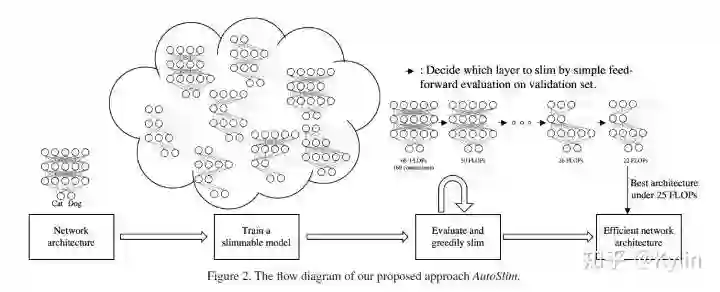
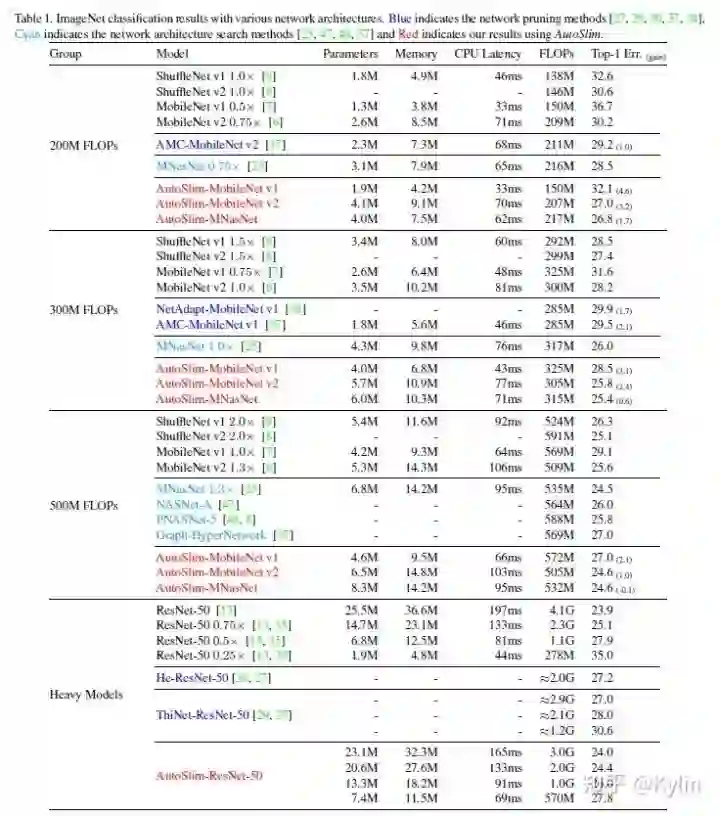
3. AutoSlim: Towards One-Shot Architecture Search for Channel Numbers
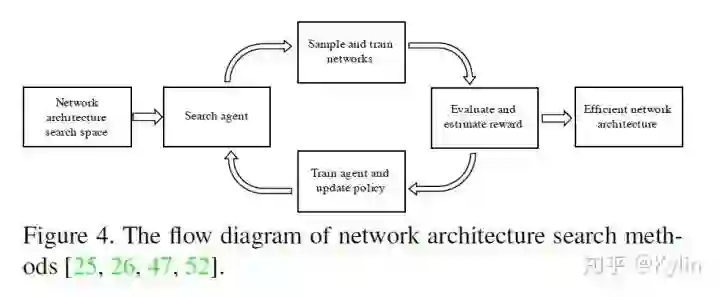
*延伸阅读


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

登录查看更多
相关内容

Explanation:网络。
Publisher:Wiley。
SIT: http://dblp.uni-trier.de/db/journals/networks/


相关VIP内容
相关资讯
相关论文