如何用机器学习精准辨别“背景”和“目标”
很多机器学习分类器都需要对背景或其他类别的物体进行具体分类。这种分类器最大的难题就是在对背景进行分类时能否达到较高的准确率。它没有可辨别特征,并且可用的训练数据可能不会覆盖所有的输入分布。在这篇文章中,我们提出了几种解决这一问题的方法。
在这篇文章里,我们将图像样本分类问题看做“狗狗种类的区分”问题(总共有9种狗狗):

我们解决了三个难题:
如何让分类器预测目标是否为“背景”的概率
如何得到背景训练数据之外的、并不符合真实背景分布的数据
如何修复背景分类的不平衡性
使用背景类别数据
想创建这个狗狗分类器,有两种方法可用:
得到这些狗狗图像和背景的所有数据(将背景也看作是可识别的一类对象),共有10类
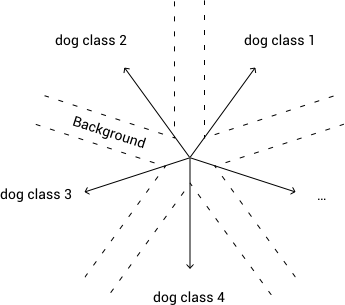
创建一个能辨别9种狗狗种类的模型,如果模型在9个种类上都没有足够高的置信度,那么就将其判定为“背景”
从我的经验来看,第二种方法表现不佳。我发现这样的模型学会了以狗狗为中心进行嵌入(logit层和softmax之前的最后一层),并且阈值通常会将各种类别的边界附近的嵌入映射到“背景”一类中:
但是事实上,狗狗们只是图片的一个子空间,也许接近一个极值(与分类器需要学习的毛发特征等其他特征不同):
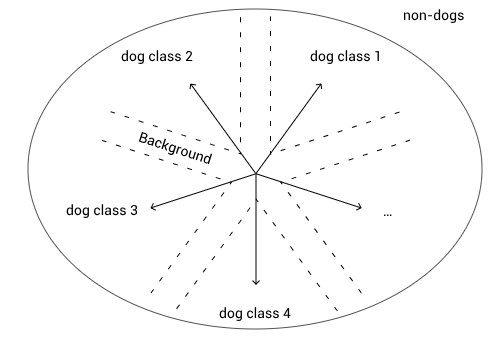
这样的分类器在没有狗狗的图像上可以任意工作。接下来,我们会介绍只能预测背景概率的分类器。
控制背景分类的学习
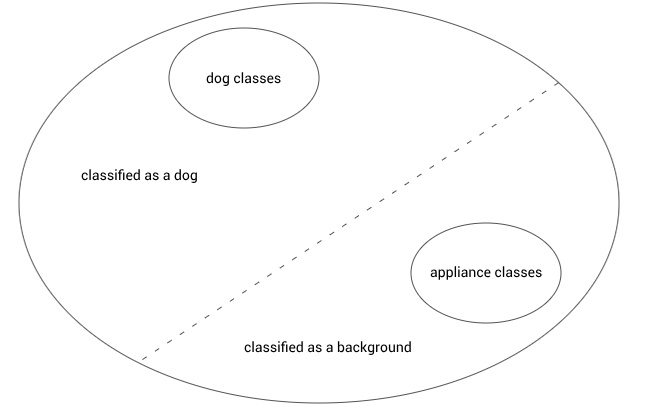
假设我们现在已经收集到了足够的有关背景分类的数据了,通常,我们的背景数据都是图片的不完全分布。下面是一些家用电器和厨房用具:

如果我们仅在这些图片上训练一个模型,让它把背景当做另外一个类别的东西,那么嵌入示意图看起来很不完美:
我有一种能显著改善这种情况的方法:不让背景类别学习特征,只让它学习一种可训练变量,即它的logit。这样一来,背景类别不会被嵌入到某个具体的区域中,给那些真正属于背景的图片更多的嵌入图空间:
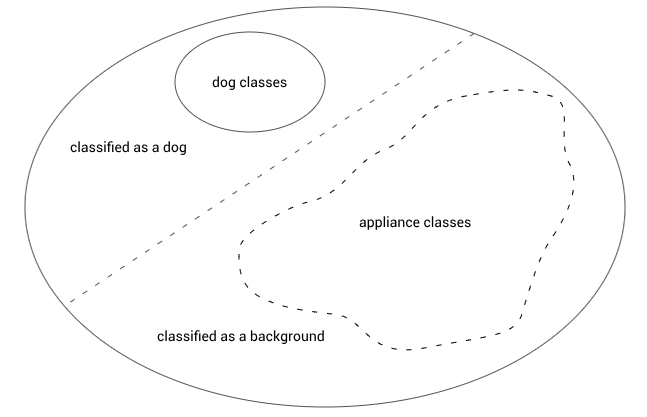
当然了,这种方法仍不完美。在某种程度上,狗狗分类可以学习在电器图片上表现较弱,但在实际中一定比这种更好。
我用上面的9种狗和6种电器的数据训练了一个模型,并完全的ImageNet验证集上对它们进行验证。我在训练和验证时加入了权重,以减轻分类的不平衡性(下一节我们会讲到如何处理真正分布的不平衡)。在下方的验证图表中,绿色的折线是模型将所有类别都相同对待的结果,蓝色折线是模型在学习时没有学习背景类型的结果:
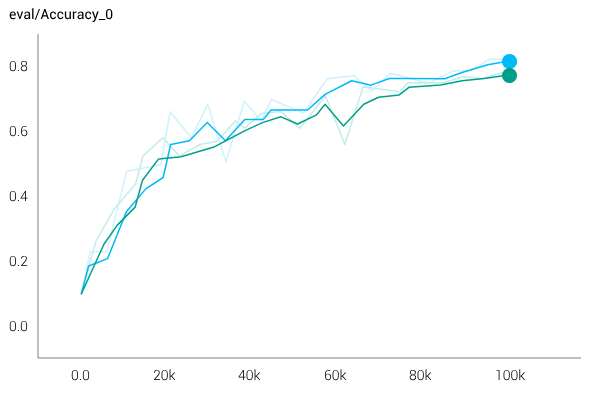
验证精度vs训练次数
没有学习背景特征的模型在大多数训练中都保持领先,在没有训练背景的情况下,精确度在15个类别的数据集上都有了提升(9种狗狗类别、6种电器类别和其中的背景类别),同时在有1000种数据集分类上也有进步(9个狗狗类别、991种电器类别和其中一个背景类别):

注意,这一结果表明这10种类别在验证时都是一样重要。
背景分类不平衡
最后,我们要考虑另一种情况,即背景类别实际上比测试时狗狗图片的数量要多。假设测试时的分布都来源于ImageNet,我们的分类器在这些情况下表现较差,因为它在训练时认为所有类别都是平均分布的。
解决这一问题最简单的方法就是在每个肯定预测中加入更高的阈值,从而当概率超过这一值并且是最高的时,我们才能判断这是某种类型的狗狗。由此,我们得到了以下的精确度与反馈曲线,如果分类器从9种狗狗中预测出了一种,那么每个样本都都被看作是“正的”,如果预测结果为“背景”,那么就是“负的”。
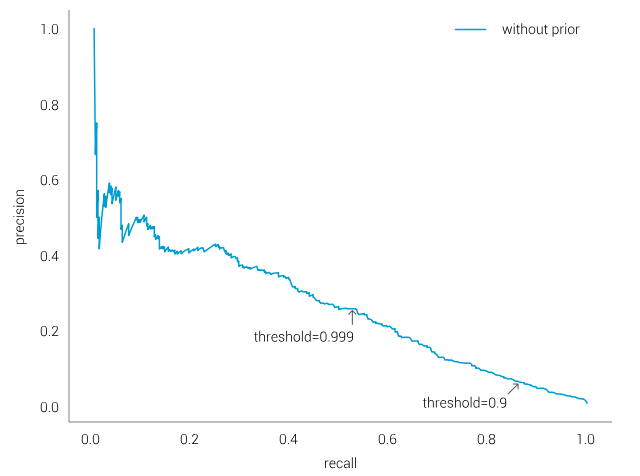
例如,如果我们需要对狗狗的预测结果达到90%的置信度,我们会对85%的图片进行正确标签,大约有7%的预测是正确的。
不过,这一结果还能提高。我们可以用先验和下面的贝叶斯公式,将概率分布从“统一”改变成“shifted”,前提是假设每个类别x都符合P(image|x,shifted) = P(image|x,uniform):
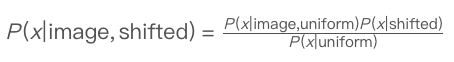
这样做的好处是,它并不需要收集更多数据,甚至重新训练模型,只需要一个简单的数据公式,就能得出更好地预测结果。
结语
总的来说,在这篇文章中我提出了三种能够在有背景的图片中提高分类器精确度的技术:
在背景类别中添加一些数据,让模型对其进行概率预测(而不是仅仅训练一个无背景的类别,对背景类别映射低概率)
避免模型使用任何特征了解背景类别的活动
使用先验调整类别不平衡问题
这些技术能改变模型对背景图片的预测,从此前的混乱预测,到可以推断出大量信息。
原文地址:thehive.ai/blog/handling-background-classes-in-machine-learning




