【论文推荐】最新五篇命名实体识别(NER)相关论文—对抗学习、语料库、深度多任务学习、先验知识、跨语言语义
【导读】专知内容组整理了最近五篇命名实体识别(Named Entity Recognition)相关文章,为大家进行介绍,欢迎查看!
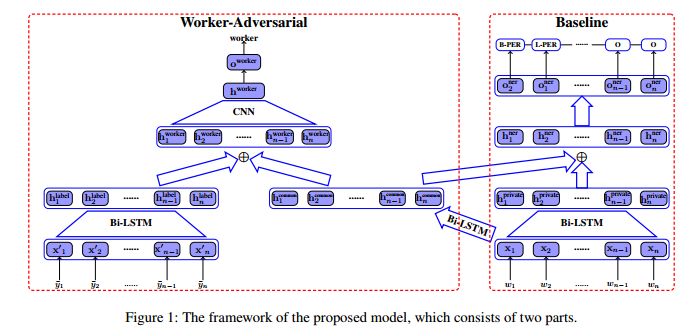
1. Adversarial Learning for Chinese NER from Crowd Annotations(中文命名实体识别:基于众包机制的对抗学习方法)
作者:YaoSheng Yang,Meishan Zhang,Wenliang Chen,Wei Zhang,Haofen Wang,Min Zhang
摘要:To quickly obtain new labeled data, we can choose crowdsourcing as an alternative way at lower cost in a short time. But as an exchange, crowd annotations from non-experts may be of lower quality than those from experts. In this paper, we propose an approach to performing crowd annotation learning for Chinese Named Entity Recognition (NER) to make full use of the noisy sequence labels from multiple annotators. Inspired by adversarial learning, our approach uses a common Bi-LSTM and a private Bi-LSTM for representing annotator-generic and -specific information. The annotator-generic information is the common knowledge for entities easily mastered by the crowd. Finally, we build our Chinese NE tagger based on the LSTM-CRF model. In our experiments, we create two data sets for Chinese NER tasks from two domains. The experimental results show that our system achieves better scores than strong baseline systems.
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/03ad7c4b7ace464f54bdc0003e5fb9b3
2. PEYMA: A Tagged Corpus for Persian Named Entities(PEYMA: 波斯人命名实体标记语料库)
作者:Mahsa Sadat Shahshahani,Mahdi Mohseni,Azadeh Shakery,Heshaam Faili
摘要:The goal in the NER task is to classify proper nouns of a text into classes such as person, location, and organization. This is an important preprocessing step in many NLP tasks such as question-answering and summarization. Although many research studies have been conducted in this area in English and the state-of-the-art NER systems have reached performances of higher than 90 percent in terms of F1 measure, there are very few research studies for this task in Persian. One of the main important causes of this may be the lack of a standard Persian NER dataset to train and test NER systems. In this research we create a standard, big-enough tagged Persian NER dataset which will be distributed for free for research purposes. In order to construct such a standard dataset, we studied standard NER datasets which are constructed for English researches and found out that almost all of these datasets are constructed using news texts. So we collected documents from ten news websites. Later, in order to provide annotators with some guidelines to tag these documents, after studying guidelines used for constructing CoNLL and MUC standard English datasets, we set our own guidelines considering the Persian linguistic rules.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/bba0fca5d40fadba66825ad4b7b97c76
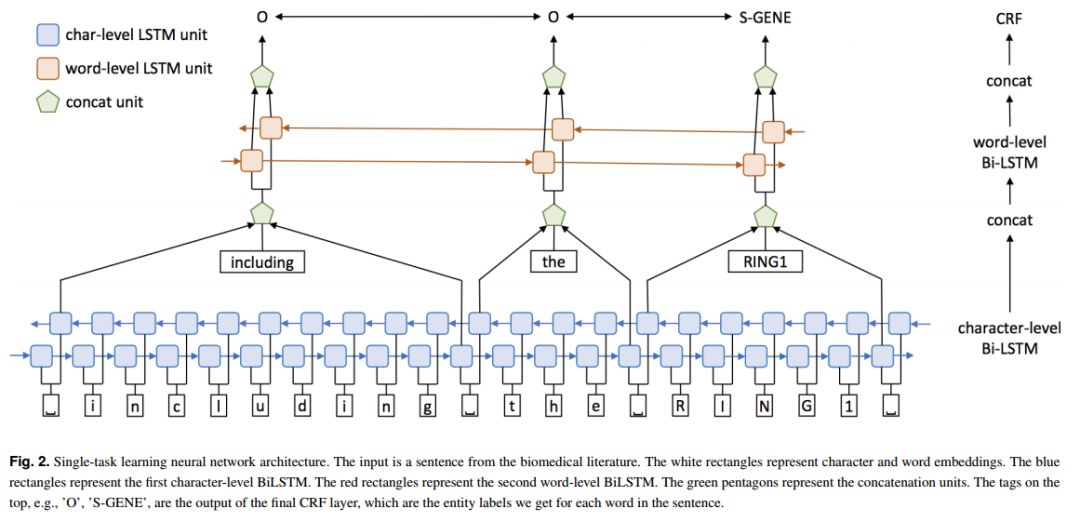
3. Cross-type Biomedical Named Entity Recognition with Deep Multi-Task Learning(基于深度多任务学习的跨类型生物医学命名实体识别)
作者:Xuan Wang,Yu Zhang,Xiang Ren,Yuhao Zhang,Marinka Zitnik,Jingbo Shang,Curtis Langlotz,Jiawei Han
摘要:Motivation: Biomedical named entity recognition (BioNER) is the most fundamental task in biomedical text mining. State-of-the-art BioNER systems often require handcrafted features specifically designed for each type of biomedical entities. This feature generation process requires intensive labors from biomedical and linguistic experts, and makes it difficult to adapt these systems to new biomedical entity types. Although recent studies explored using neural network models for BioNER to free experts from manual feature generation, these models still require substantial human efforts to annotate massive training data. Results: We propose a multi-task learning framework for BioNER that is based on neural network models to save human efforts. We build a global model by collectively training multiple models that share parameters, each model capturing the characteristics of a different biomedical entity type. In experiments on five BioNER benchmark datasets covering four major biomedical entity types, our model outperforms state-of-the-art systems and other neural network models by a large margin, even when only limited training data are available. Further analysis shows that the large performance gains come from sharing character- and word-level information between different biomedical entities. The approach creates new opportunities for text-mining approaches to help biomedical scientists better exploit knowledge in biomedical literature.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/8a50efa2397c90ac16e8efdcdae48af1
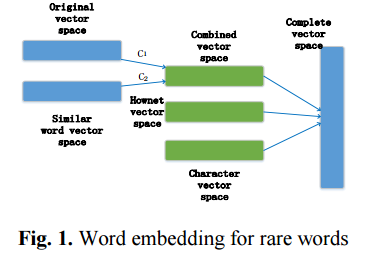
4. Improving Word Vector with Prior Knowledge in Semantic Dictionary(基于语义词典先验知识的词向量表示学习)
作者:Wei Li,Yunfang Wu,Xueqiang Lv
摘要:Using low dimensional vector space to represent words has been very effective in many NLP tasks. However, it doesn't work well when faced with the problem of rare and unseen words. In this paper, we propose to leverage the knowledge in semantic dictionary in combination with some morphological information to build an enhanced vector space. We get an improvement of 2.3% over the state-of-the-art Heidel Time system in temporal expression recognition, and obtain a large gain in other name entity recognition (NER) tasks. The semantic dictionary Hownet alone also shows promising results in computing lexical similarity.
期刊:arXiv, 2018年1月27日
网址:
http://www.zhuanzhi.ai/document/341ae96aa9ebe260d5b8152610db2df8
5. A Resource-Light Method for Cross-Lingual Semantic Textual Similarity(一种用于跨语言语义文本相似性的Resource-Light方法)
作者:Goran Glavaš,Marc Franco-Salvador,Simone Paolo Ponzetto,Paolo Rosso
摘要:Recognizing semantically similar sentences or paragraphs across languages is beneficial for many tasks, ranging from cross-lingual information retrieval and plagiarism detection to machine translation. Recently proposed methods for predicting cross-lingual semantic similarity of short texts, however, make use of tools and resources (e.g., machine translation systems, syntactic parsers or named entity recognition) that for many languages (or language pairs) do not exist. In contrast, we propose an unsupervised and a very resource-light approach for measuring semantic similarity between texts in different languages. To operate in the bilingual (or multilingual) space, we project continuous word vectors (i.e., word embeddings) from one language to the vector space of the other language via the linear translation model. We then align words according to the similarity of their vectors in the bilingual embedding space and investigate different unsupervised measures of semantic similarity exploiting bilingual embeddings and word alignments. Requiring only a limited-size set of word translation pairs between the languages, the proposed approach is applicable to virtually any pair of languages for which there exists a sufficiently large corpus, required to learn monolingual word embeddings. Experimental results on three different datasets for measuring semantic textual similarity show that our simple resource-light approach reaches performance close to that of supervised and resource intensive methods, displaying stability across different language pairs. Furthermore, we evaluate the proposed method on two extrinsic tasks, namely extraction of parallel sentences from comparable corpora and cross lingual plagiarism detection, and show that it yields performance comparable to those of complex resource-intensive state-of-the-art models for the respective tasks.
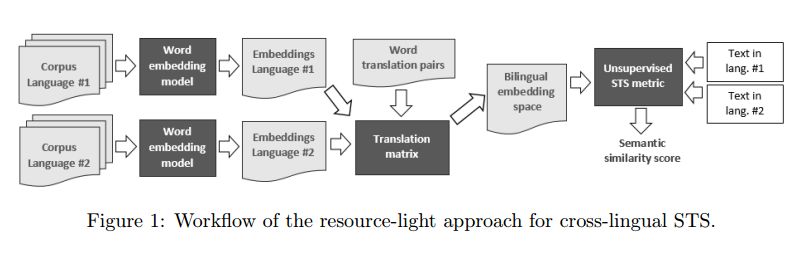
期刊:arXiv, 2018年1月19日
网址:
http://www.zhuanzhi.ai/document/4e2a2c813dc5a298d49757652eae9be4
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!


