【导读】国际万维网大会(The Web Conference,简称WWW会议)是由国际万维网会议委员会发起主办的国际顶级学术会议,创办于1994年,每年举办一届,是CCF-A类会议。WWW 2020将于2020年4月20日至4月24日在中国台湾台北举行。本届会议共收到了1129篇长文投稿,录用217篇长文,录用率为19.2%。这周会议已经召开,会议论文集已经公开,大家可以自己查看感兴趣的论文,专知小编继续整理WWW 2020 系列论文,这期小编为大家奉上的是WWW 2020五篇知识图谱+图神经网络(KG+GNN)相关论文,供大家参考!——多关系实体对齐、问答推理、动态图实体链接、序列实体链接、知识图谱补全。
WWW 2020 会议论文集: https://dl.acm.org/doi/proceedings/10.1145/3366423
WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN、ICML2019GNN
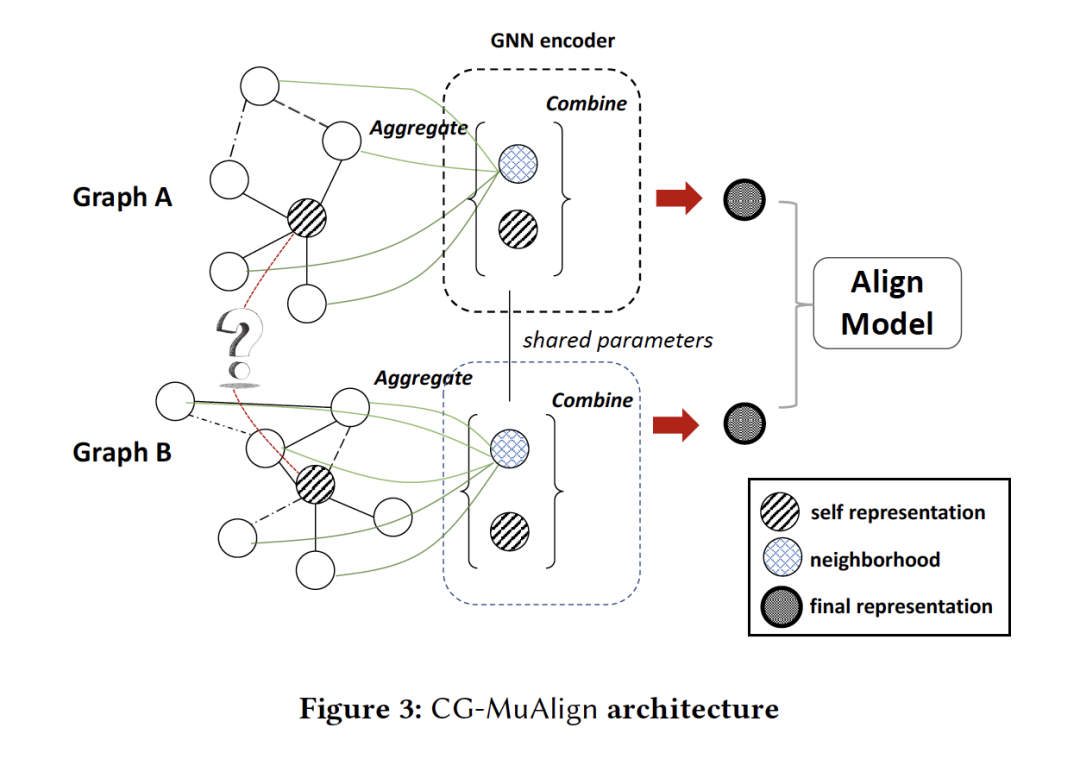
- Collective Multi-type Entity Alignment Between Knowledge Graphs
作者:Qi Zhu, Hao Wei, Bunyamin Sisman, Da Zheng, Christos Faloutsos, Xin Luna Dong and Jiawei Han
摘要:知识图(如Freebase、Yago)是表示各类实体之间丰富真实信息的多关系图。实体对齐是实现多源知识图集成的关键步骤。它旨在识别涉及同一真实世界实体的不同知识图中的实体。然而,现有的实体对齐系统忽略了不同知识图的稀疏性,不能通过单一模型对多类型实体进行对齐。在本文中,我们提出了一种用于多类型实体对齐的联合图神经网络(Collective Graph neural network),称为CG-MuAlign。与以前的工作不同,CG-MuAlign联合对齐多种类型的实体,共同利用邻域信息并将其推广到未标记的实体类型。具体地说,我们提出了一种新的集中聚集函数1)通过交叉图和自注意力来缓解知识图的不完全性,2)通过小批量训练范例和有效的邻域抽样策略,有效地提高了可伸缩性。我们在具有数百万个实体的真实知识图上进行了实验,观察到了比现有方法更优越的性能。此外,我们的方法的运行时间比目前最先进的深度学习方法要少得多。
网址:
https://dl.acm.org/doi/abs/10.1145/3366423.3380289
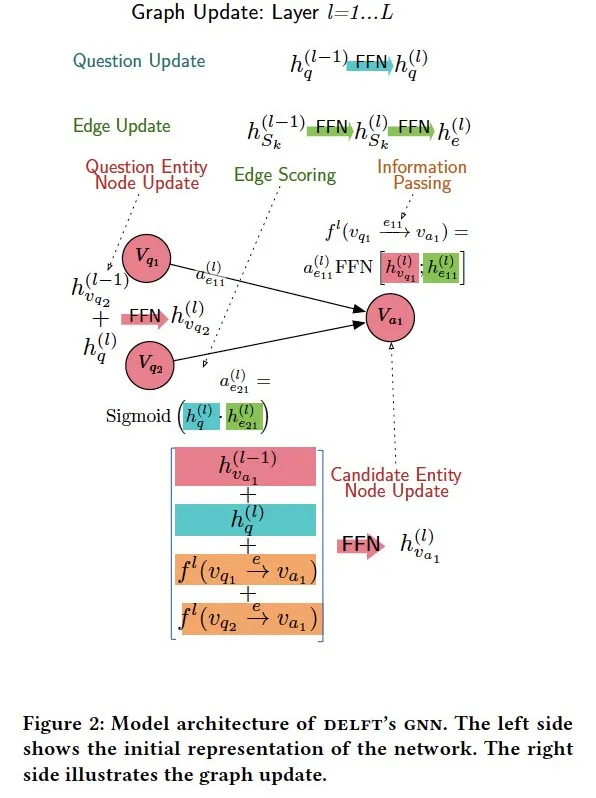
- Complex Factoid Question Answering with a Free-Text Knowledge Graph
作者:Chen Zhao, Chenyan Xiong, Xin Qian and Jordan Boyd-Graber
摘要:我们介绍了Delft,一个事实问答系统,它将知识图问答方法的细微和深度与更广泛的free-文本结合在一起。Delft从Wikipedia构建了一个自由文本知识图,以实体为节点和句子,其中实体同时出现做为边。对于每个问题,Delft使用文本句子作为边,找到将问题实体节点链接到候选对象的子图,创建了密集且覆盖率高的语义图。一种新颖的图神经网络在free-文本图上进行推理-通过沿边句子的信息组合节点上的证据-以选择最终答案。在三个问答数据集上的实验表明,Delft能够比基于机器阅读的模型、基于BERT的答案排序和记忆网络更好地回答实体丰富的问题。Delft的优势既来自于其free-文本知识图谱的高覆盖率--是DBpedia关系的两倍多--也来自于新颖的图神经网络,它基于丰富而嘈杂的free-文本证据进行推理。
网址:
https://dl.acm.org/doi/abs/10.1145/3366423.3380197
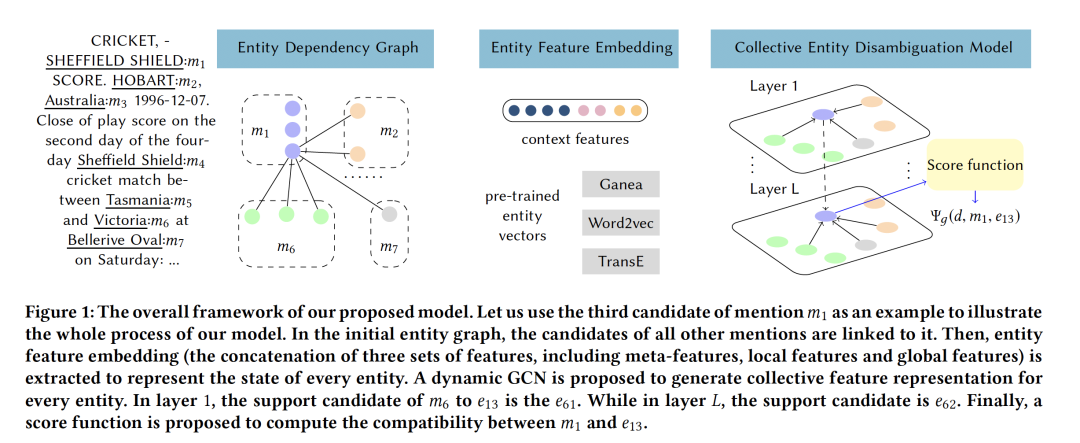
- Dynamic Graph Convolutional Networks for Entity Linking
作者:Junshuang Wu, Richong Zhang, Yongyi Mao, Hongyu Guo, Masoumeh Soflaei and Jinpeng Huai
摘要:实体链接将文档中提及的命名实体映射到给定知识图中的合适的实体,已被证明能够从基于图卷积网络(GCN)对实体相关性建模中获得显著好处。然而,现有的GCN实体链接模型没有考虑到,一组实体的结构化图不仅依赖于给定文档的上下文信息,而且在GCN的不同聚合层上自适应地变化,导致在捕捉实体之间的结构信息方面存在不足。在本文中,我们提出了一种动态的GCN体系结构来有效地应对这一挑战。模型中的图结构是在训练过程中动态计算和修改的。通过聚合动态链接节点的知识,我们的GCN模型可以集中识别文档和知识图之间的实体映射,并有效地捕捉整个文档中各个实体提及( mentions)之间的主题一致性。在基准实体连接数据集上的实证研究证实了我们提出的策略的优越性能和动态图结构的好处。
https://dl.acm.org/doi/abs/10.1145/3366423.3380192
- High Quality Candidate Generation and Sequential Graph Attention Network for Entity Linking
作者:Yichao Zhou, Shaunak Mishra, Manisha Verma, Narayan Bhamidipati and Wei Wang
摘要:实体链接(EL)是将文本中提及的内容映射到知识库(KB)中相应实体的任务。这项任务通常包括候选生成(CG)和实体消歧(ED)两个阶段。目前基于神经网络模型的EL系统取得了较好的性能,但仍然面临着两个挑战:(1)以往的研究在评估模型时没有考虑候选实体之间的差异。事实上,候选集的质量(特别是黄金召回)对EL结果有影响。因此,如何提候选的素质需要引起更多的关注。(Ii)为了利用提及实体之间的主题一致性,提出了许多聚集ED的图和序列模型。然而,基于图的模型对所有候选实体一视同仁,这可能会引入大量的噪声信息。相反,序列模型只能观察先前引用的实体,而忽略了当前提及的实体与其后续实体之间的相关性。针对第一个问题,我们提出了一种基于多策略的CG方法来生成高召回率的候选集。对于第二个问题,我们设计了一个序列图注意力网络(SeqGat),它结合了图和序列方法的优点。在我们的模型中,提及( mentions)是按顺序处理的。在当前提到的情况下,SeqGAT对其先前引用的实体和后续实体进行动态编码,并为这些实体分配不同的重要性。这样既充分利用了主题的一致性,又减少了噪声干扰。我们在不同类型的数据集上进行了实验,并在开放的评测平台上与以前的EL系统进行了比较。比较结果表明,与现有的方法相比,我们的模型有了很大的改进。
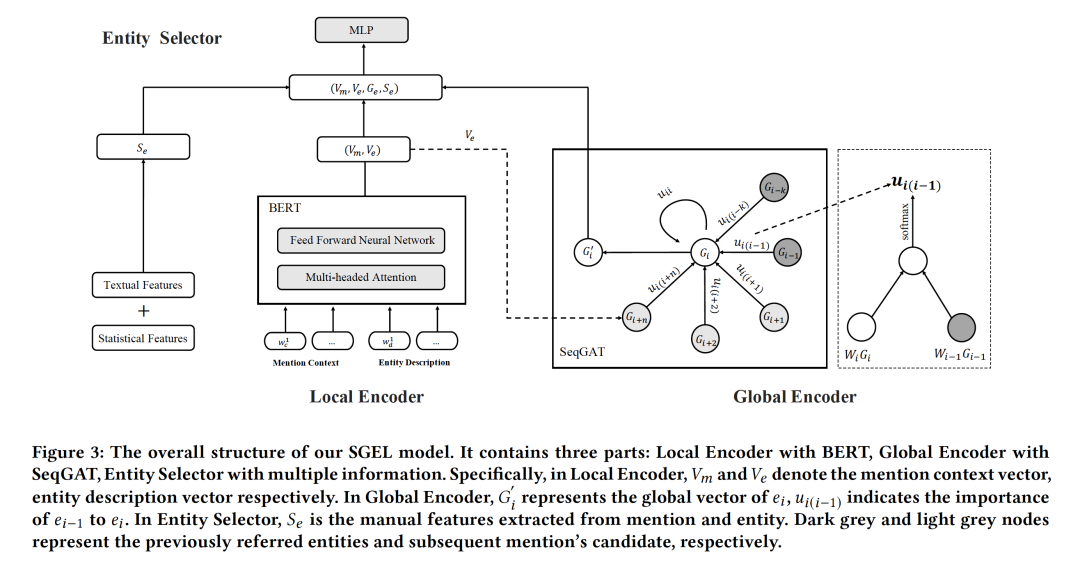
https://dl.acm.org/doi/abs/10.1145/3366423.3380146
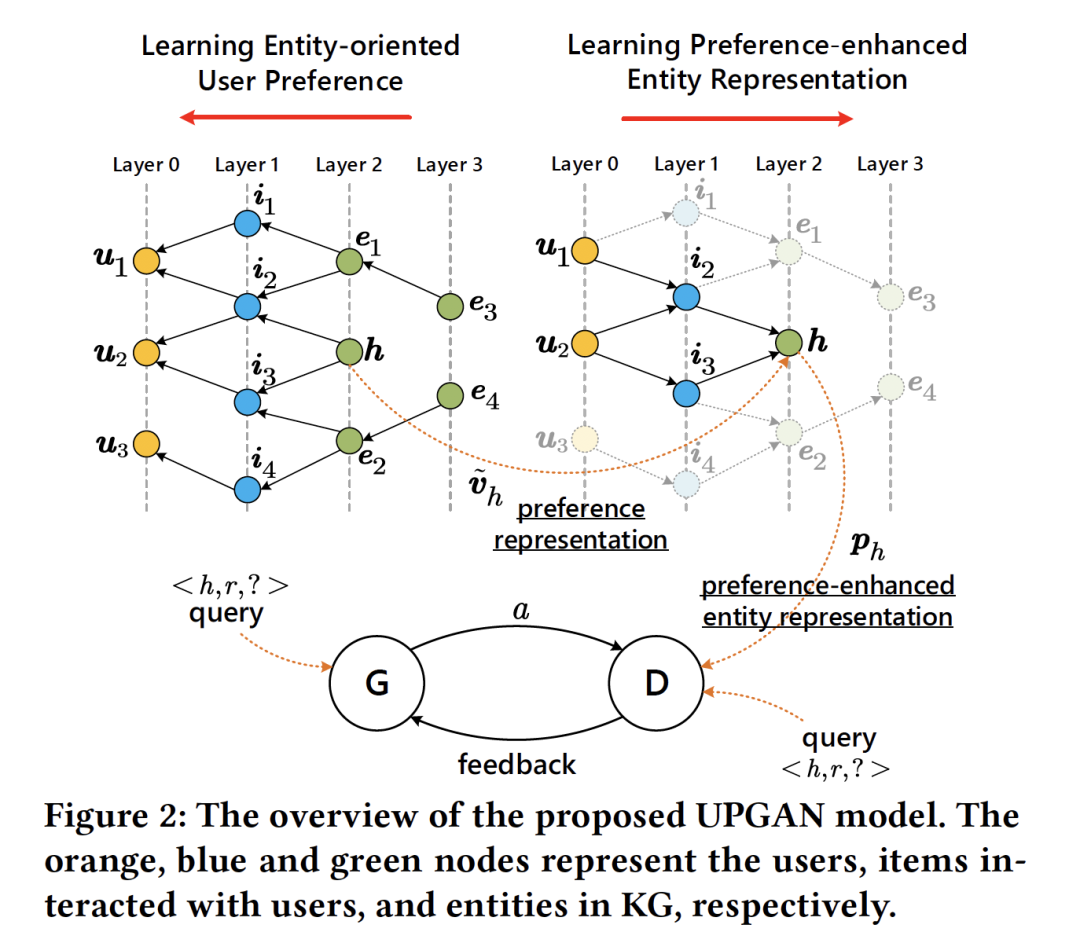
- Mining Implicit Entity Preference from User-Item Interaction Data for Knowledge Graph Completion via Adversarial Learning
作者:Gaole He, Junyi Li, Wayne Xin Zhao, Peiju Liu and Ji-Rong Wen
摘要:知识图补全(KGC)任务旨在自动推断知识图(KG)中缺失的事实信息。在本文中,我们采取了一个新的视角,旨在利用丰富的用户-项目交互数据(简称用户交互数据)来改进KGC任务。我们的工作灵感来自于观察到许多KG实体对应于应用系统中的在线项目。然而,这两种数据源的固有特性有很大的不同,使用简单的融合策略很可能会损害原有的性能。为了应对这一挑战,我们提出了一种新的对抗性学习方法,通过利用用户交互数据来执行KGC任务。我们的生成器是从用户交互数据中分离出来的,用来提高鉴别器的性能。鉴别器将从用户交互数据中学习到的有用信息作为输入,并逐步增强评估能力,以识别生成器生成的假样本。为了发现用户的隐含实体偏好,设计了一种基于图神经网络的协同学习算法,并与鉴别器进行联合优化。这种方法有效地缓解了KGC任务的数据异构性和语义复杂性问题。在三个真实世界数据集上的广泛实验已经证明了我们在KGC任务上的方法的有效性。