论文共读 | Attention is All You Need

本文授权转载自学术平台PaperWeekly,微信号:PaperWeekly。这是一个推荐、解读、讨论和报道人工智能前沿论文成功的学术平台,致力于让国内外优秀科研工作得到更为广泛的传播和认可。
Attention Is All You Need
通常来说,主流序列传导模型大多基于 RNN 或 CNN。Google 此次推出的翻译框架—Transformer 则完全舍弃了 RNN/CNN 结构,从自然语言本身的特性出发,实现了完全基于注意力机制的 Transformer 机器翻译网络架构。
论文链接:https://arxiv.org/pdf/1706.03762.pdf
开源实现
#Chainer#
https://github.com/soskek/attention_is_all_you_need
#PyTorch#
https://github.com/jadore801120/attention-is-all-you-need-pytorch
#TensorFlow#
https://github.com/Kyubyong/transformer
阅读笔记精选

Robin_CityU
该 paper 可以算作是 Google 针对 Facebook 之前的 CNN seq2seq: 1705.03122 的回应。工程性较强,主要目的是在减少计算量和提高并行效率的同时不损害最终的实验结果。
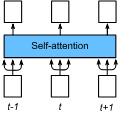
模型的框架如下:
Encoder 部分 -- 6 个 block,每个 block 中有两层,他们分别是 Multi-head self attention 和 Position-wise feed forward。
1. Multi-head self attention - 多组self attention的连接。首先 encoder 的初始输入为sentence embedding + position embedding,其中position embedding的三角函数表示挺有意思。
Attention(Q,K,V)=softmax(QK^T/sqrt(d_k))V,其中 Q 与 K 均为输入,(V 为 learned value?此处存疑)。输入 size 为[sequence_length, d_model],输出 size 不变。然后是 residual connection,即 LayerNorm(x+Sublayer(x)),输出 size 不变。
2. Position-wise feed forward network,其实就是一个 MLP 网络,1 的输出中,每个 d_model 维向量 x 在此先由 xW1+b1 变为 d_ff 维的 x',再经过 max(0, x')W2+b2 回归 d_model 维。之后再是一个 residual connection。输出 size 仍是 [sequence_length, d_model]。
Decoder 部分 -- 6 个 block,每个 block 中有 3 层,他们分别是 Multi-head self attention (with mask),Multi-head attention (with encoder),Position-wise feed forward。
1. Multi-head self attention (with mask) 与 encoder 部分相同,只是采用 0-1mask 消除右侧单词对当前单词 attention 的影响。
2. Multi-head attention(with encoder) 引入 encoder 部分的输出在此处作为 multi-head 的其中几个 head。
3. Position-wise feed forward network 与encoder部分相同。
some tricks during training process:(1) residual dropout; (2) attention dropout; (3) label smoothing
几点思考:
该模型没有使用 RNN 与 CNN,但做法其实像 CNN 的简化版,包括 normalization,dropout 的使用,以及 future work 提出的 local,restricted attention。
文章的第四部分其实并没有清楚地解释为什么使用所谓 self-attention,但是可否由此引出大家对 RNN 系列模型更深入的思考?毕竟 long dependency 与 hard to parallel 等问题一直存在。
在 seq2seq 任务中,一般 RNN 模型,encoder 与 decoder 自身受语言模型的约束较大,因此往往 decode 时常常出现重复、缺失等语言模型常出现的问题,如果真的切断由 RNN 建立的单词与单词之间的联系(其实 CNN 已经这么做了),也值得一试。而 position embedding 的引入,是否可以补充顺序信息?

WarBean
尝试用自己的理解对比一下卷积、recurrent 和 self attention:
卷积:只能看到领域,适合图像,因为在图像上抽象更高层信息仅仅需要下一层特征的局部区域。
recurrent:理论上能看到所有历史,适合文本,但是存在梯度消失问题。
self attention:相比 recurrent 不存在梯度消失问题,这点显然。对比 CNN 更加适合文本,因为能够看到更远距离的信息,这点展开说明——因为文本语义的抽象不同于图像语义的抽象,后者看下一层的局部就行,前者经常需要看很远的地方。比如现在“苹果”这个词我要对它做一个抽象,按“苹果公司”抽象还是按“水果”抽象呢?这个选择可能依赖于几十个 step 之外的词。诚然,CNN 叠高了之后可以看到很远的地方,但是 CNN 本来需要等到很高层的时候才能完成的抽象,self attention 在很底层的时候就可以做到,这无疑是非常巨大的优势。
Q&A 精选
Hinse
We suspect this to be caused by the dot products growing too large in magnitude to result in useful gradients after applying the softmax function.
解释了引入 scale 是为了避免:当 dk 比较大时点乘结果太大导致有效梯度太大(或被 clipped)。
WarBean: 但是为什么是除以根号 d_k 而不是 d_k 呢,有没有人能解释一下为什么这么选?
soloice: 不是很懂为什么内积变大会导致梯度变小。如果内积变大,应该是每一个 k 和 q 的内积都变大,做 softmax 的话反正最后要归一化,应该不受影响啊。
有一种可能的解释是,点积只是绝对值变大,但是数值有正有负,比如 [0.1, -0.1] 变成 [10, -10],softmax 算出来结果就很糟糕。而且即使是这样的话,也可以期待一半的梯度有效回传吧 = = 另外这个 scale 其实就是 softmax 里的 temperature 吧,但是为什么用根号 d_k 就不清楚了。
dalegebit: 回复一下楼上的,其实注释里写得很清楚,假设两个 d_k 维向量每个分量都是一个相互独立的服从标准正态分布的随机变量,那么他们的点乘的方差就是 d_k,每一个分量除以 sqrt(d_k) 可以让点乘的方差变成 1。
gujiuxiang
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence
存疑,输入应该包含 previous word,怎么就不无 recurrence。他们的 claim 和之前 facebook cnn 那篇类似,idea 卖得都很炫。不过,我认为都包含recurrence。
wxuan: 编码器端的 recurrence,都通过这个 Positional Encoding 消除了。
rqyang: 确实是编码器不存在 recurrence,解码器存在广义上的 recurrence。这里论文的出发点应该是对输入的序列不存在 recurrence,输出序列的时候是把上一时刻的词当作“query”来看了。
Hinse: 感觉 dec 也不存在 recurrence。 因为 recurrence 是指不同 step 之间要顺序执行从影响速度的 recurrence。而这个 decoder 每一层对不同位置的计算是并行的。当前位置的计算不依赖前面位置的计算结果。 当然这也是因为他使用的是 ground truth 做输入。 为了并行, 模型的灵活性受到了限制。
WarBean: 同意楼上说 decode(在训练阶段)也不存在 recurrence。之前的 rnn decoder 在训练的时候即便给 ground truth(即 Teacher Forcing 训练法),由于 hidden state 之间存在的连接,所以仍然必须一个个 position 滚过去。本文则不需要,因为已经砍掉相邻两步之间 hidden state 这条连接了。不过,在测试阶段 decode下一个词依赖于上一个输出,所以仍然是 recurrence 的。
jordan: 整个都不存在依赖上一词的信息的, 只是依赖上一层,但词与词之间是可以并行的。

wxuan
In this work, we use sine and cosine functions of different frequencies.
不是很理解这里的出发点,对最终效果有多大影响?
Hinse: 文章里面提到了这样做,是因为 sin(a+b) = sin(a)cos(b) + cos(b)sin(a),其中 b 是一个固定的 offset 也就是常数了,所以 pos+k 的编码就可以通过 pos 的编码来线性表示了。但我感觉还有一个原因就是不容易重复:不同的维度使用不同的频率 (i=0,1,2... dim_size)。不同位置就是同一个频率的不同相位。感觉就像信号处理里面不同的频率承载不同的信息叠加(位置编码后有两个 fc 和 relu)后仍然容易分离,同一个频率用不同的相位区分信息。这个其实没太想清楚还是先忽略吧。
rqyang: 如果我运算符优先级没弄错的话,指数运算优先级更高,然后在最后一维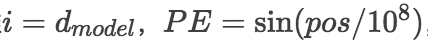
WarBean: 你公式写错了,最后一维的 PE = sin(pos / 10000)。
rqyang: 才发现这里是应该是 PE 的第二个参数是维度,ii 的最大值是维度的一半,谢谢提醒。
WarBean: 这个 position embedding 设置得很有意思,我尝试解释一下:每两个维度构成一个二维的单位向量,总共有 d_model / 2 组。每一组单位向量会随着 pos 的增大而旋转,但是旋转周期不同,按照论文里面的设置,最小的旋转周期是 2pi,最大的旋转周期是 10000 x 2pi。至于为什么说相邻 k 步的 position embedding 可以用一个线性变换对应上,是因为上述每组单位向量的旋转操作可以用表示为乘以一个 2 x 2 的旋转矩阵。
隐约感觉论文像这样把 position 表示成多组不同旋转周期的单位向量,能有助于泛化到训练时没有见过的长度,但是说不出为什么,坐等大神分析。 看上去 10000(省略 2pi)的最大周期好像拉得有点大,似乎没啥必要,不过我在自己做的一个任务上用了这个 position embedding,我那个任务的 decode step 通常是 50 多,但是最大周期设置到 10、100、1000 效果都还不错,所以这里设置成 10000 应该也没太大问题,最多就是后面一些维度的周期太长变化率太慢,没啥用,冗余而已,也没什么坏处。如果担心冗余维度挤占有用维度的份额,那就把 d_model 设大一点就好了,论文用 512 维我感觉已经足够了。
yang: 一个是 sin 一个是 cos,这种位置信息能将相对位置表示的挺不错的,将时域和频域空间做了映射,将文本位置信息做成信号。

wxuan
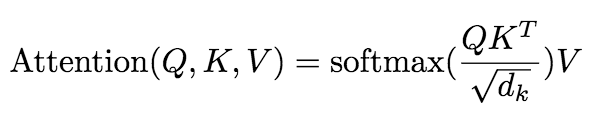
一般的机器学习论文中,向量默认都是列向量,这里的公式是根据行向量写的。
rqyang: 这里应该都是矩阵,假设 query 的长度为 ,序列长度为 ,那么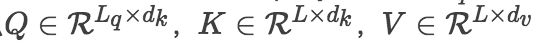
欢迎关注公众号学习交流~