您可以相信模型的不确定性吗?
文 / Jasper Snoek 研究员和 Zachary Nado 研究工程师
Google Research

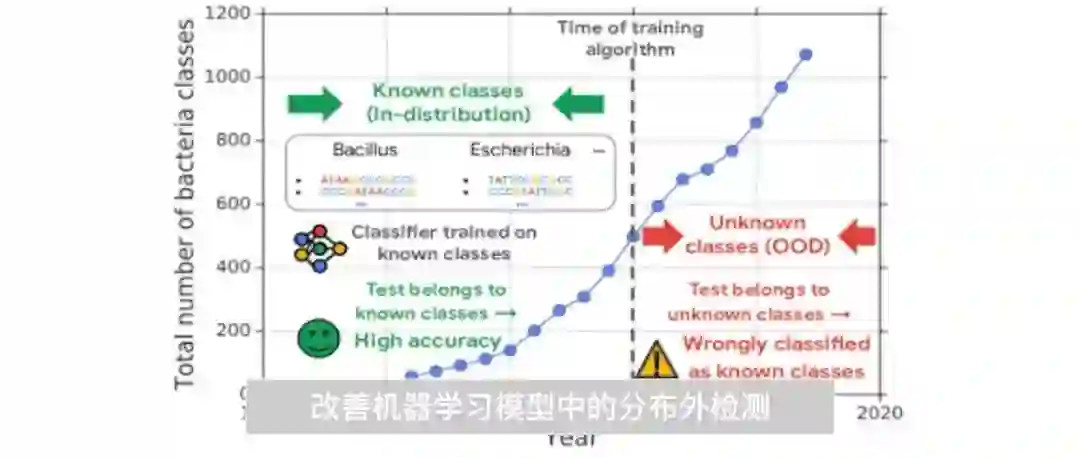
理想情况下,我们会使用深度学习等机器学习 (ML) 方法对与训练数据分布相同的数据进行预测。实际情况则有可能大不相同:相机镜头变得模糊、传感器性能下降,以及网络热点话题的变化等问题都会导致模型的训练数据分布与应用数据分布之间存在差异,进而导致所谓的 协变量偏移 (Covariate Shift)。例如,最近我们观察到,为胸部 X 光检测肺炎而训练的深度学习模型,在使用以前未曾见过的医院数据进行评估时,得到的精度水平大不相同。当然,部分原因是图像获取和处理方面存在细微差别。
《您可以相信模型的不确定性吗?评估数据集偏移下的预测不确定性》(Can you trust your model’s uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift)一文 发表于 NeurIPS 2019,文中我们对几个最先进 (SOTA) 的深度学习模型的不确定性进行了基准测试,这些模型面临着 分布偏移 (Shifting Distributions) 数据与 分布外 (Out-Of-Distribution) 数据 。
在这项研究中,我们考虑了包括图像、文本和在线广告数据在内的多种输入形式,让这些深度学习模型暴露在显著偏移的的测试数据中,同时我们也仔细分析其预测概率的行为。我们还比较了用于改善模型不确定性的各种不同方法,以了解哪些策略在分布偏移下表现最优。
什么是分布外数据?
深度学习模型为每个预测提供概率,此概率表示模型的置信度或 不确定性。这样一来,它们就可以表达自己不知道的内容,当数据超出原始训练数据集的范围时,避免进行预测。
如果存在协变量偏移,理想情况下,不确定性会随着精度降低而成比例增加。更极端的情况是,数据没有在训练集中,即是数据在 分布外 (OOD)。例如,思考一下当猫狗图像分类器中出现飞机的图像时会发生什么。模型会直接预测错误还是会为每一个类别显示低概率?在近期发布的一篇相关文章中,我们介绍了自己开发的用于识别此类 OOD 示例的方法。在这项研究中,我们分析了在 OOD 以及发生偏移的示例下模型的预测不确定性,以查看模型概率是否反映了其对此类数据进行预测的能力。
量化不确定性的质量
一个模型比另一个模型更能反映自身的不确定性意味着什么?虽然这是一个通常由下游任务定义的细微问题,但仍有一些方法可以定量评估概率预测的总体质量。例如,气象界已经仔细考虑过这一问题,并制定了一套合适的评分规则。基于概率的天气预报比较函数遵循了这些规则,在保证精度的同时可以进行校准。我们应用了评分规则中的一些(例如布莱尔评分 (Brier Score)和负对数似然 (Negative Log Likelihood, NLL)),以及更直观的启发式方法(例如 预期校准误差 (Expected Calibration Error, ECE)),以了解不同的 ML 模型如何处理数据集偏移情况下的不确定性。
实验
我们分析了数据集偏移对各种数据模式(包括图像、文本、在线广告数据和基因组学)不确定性的影响。举例而言,我们阐释了数据集偏移对 ImageNet 数据集(一项很受欢迎的图像理解基准)的影响。ImageNet 将一百多万张图像分成 1000 个不同的类别。现在,有些人认为这一挑战已基本解决,并且开发出了更难的挑战,例如根据 16 种不同的实际损坏(每种损坏有 5 个不同的强度)增强数据的 Corrupted Imagenet(或 Imagenet-C)。

我们探索了模型不确定性在数据分布发生变化时的行为方式,例如在 Corrupted Imagenet 中使用的图像扰动强度增加。此处展示的是强度级别 3(共 5 个级别)中每种类型的图像损坏示例
我们将这些损坏的图像用作偏移数据示例,并检查深度学习模型在损坏强度增加的偏移数据下的预测概率。我们在下方展示了每个损坏级别(包含未损坏的测试数据)产生的精确度和 ECE 的箱线图,其中每个箱型图汇总了 ImageNet-C 中的所有损坏类型。每种颜色代表不同类型的模型:用作基线的“普通”深度神经网络、四种不确定性方法(Dropout、温度标定 (Temperature Scaling) 以及我们的 Last Layer Approach 和一种集成方法)。
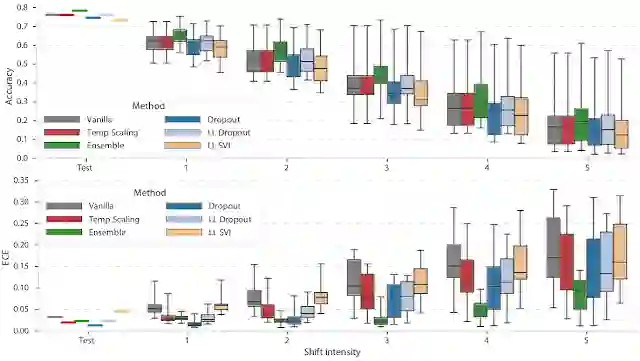
ImageNet-C 上数据集偏移强度增加的精度(上图)和预期校准误差(下图;越低越好)。我们观察到,精确度的降低并没有反映在增加模型不确定性上,这表明精确度和 ECE 都在变差
与预期相同,随着偏移强度增强,每个模型的破坏方法精确度偏差也会增加(箱会变大),而且总体精确度会下降。理想情况下,这将在模型不确定性增加上有所反映,预期校准误差 (ECE) 也会因此保持不变。然而,从下面的 ECE 箱型图来看,发现情况并非如此,而且校准通常也会受到影响。在布莱尔评分 (Brier Score)和负似然对数 (NLL)中,我们也观察到了类似的恶化趋势,这表明模型并不会随着偏移而变得越来越不确定,而是会给出错误判断。
有一种非常受欢迎的校准改进方法,名为温度标定,它是 Platt 标定的一种变体,涉及在训练后使用留出验证集上的性能来平滑预测。我们观察到,虽然此方法改进了标准测试数据的校准,但经常会使发生偏移的数据变得更糟!因此,应用该技术的从业者应警惕分布偏移。
幸运的是,有一种方法在不确定性方面的降低比其他方法平缓得多。深度集成(绿色部分)是一种简单的策略,它会对一系列模型的预测作平均化处理(每个模型的初始化不同),从而显著提高偏移的稳定性,并且其性能优于所有其他测试方法。
总结和推荐的最佳做法
-
训练模型时,必须考虑数据集偏移下的不确定性。 -
通常,在分布内测试集上提高校准和精确度不会转化为偏移数据的校准提高。 在我们考虑过的所有方法中,深度集成对数据集偏移而言最为稳定,并且较小的集成大小(例如,5)就足够了。集成的有效性为其他改进方法提供了有趣路径。
改善深度学习模型的预测不确定性仍然是 ML 研究的活跃领域。我们已经发布了此基准中的所有代码和模型预测,希望可以帮助社区推动和评估这一重要主题的未来研究。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
最近我们观察到
https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.1002683您可以相信模型的不确定性吗?评估数据集偏移下的预测不确定性
https://arxiv.org/abs/1906.02530NeurIPS 2019
https://nips.cc/Conferences/2019合适的评分规则
https://www.stat.washington.edu/raftery/Research/PDF/Gneiting2007jasa.pdf预期校准误差
https://arxiv.org/pdf/1706.04599.pdfImageNet
http://www.image-net.org/Corrupted Imagenet
https://openreview.net/pdf?id=HJz6tiCqYmDropout
https://arxiv.org/abs/1506.02142温度标定/Temperature Scaling
https://arxiv.org/abs/1706.04599Platt 标定
https://www.researchgate.net/publication/2594015_Probabilistic_Outputs_for_Support_Vector_Machines_and_Comparisons_to_Regularized_Likelihood_Methods深度集成
https://arxiv.org/abs/1612.01474代码和模型预测
https://github.com/google-research/google-research/tree/master/uq_benchmark_2019
— 推荐阅读 —