(CVPR2021)基于结构保持的弱监督目标定位
计算创意与艺术
我们来自中科院自动化所模式识别国家重点实验室多媒体计算团队,将持续给大家带来人工智能与创意、艺术、美学等相结合的学术与应用知识,请持续关注哦!
作者&论文:潘兴甲 编辑:林诗登
导言
基于CAM的弱监督定位方法主要通过多样的空间正则提高目标响应区域,忽略了模型中隐含的目标结构信息。我们提出了基于高阶相似性的目标定位方法 (SPA),充分挖掘了模型隐含的目标结构信息,显著提高了弱监督目标定位准确度。
目前代码已开源:
https://github.com/Panxjia/SPA_CVPR2021
研究背景
弱监督目标检测近年来逐渐受到国内外研究机构以及工业界关注。基于全监督的目标检测方法需要耗费大量的人力、物力获取大量准确的标注信息,对于任务更新以及迁移极其不友好。近年来,全世界范围内的研究者试图从弱监督学习方面突破标注数据的限制,为目标检测寻找一种更加高效、低廉的解决框架。
弱监督定位研究如何仅利用图像的类别标签对图像中目标进行定位。
2014年MIT提出的类别响应图CAM,得到目标的响应掩模,之后通过最小包围框得到目标的定位结果。CAM得到的类别响应掩模只能覆盖目标最具判别性的局部区域,如图1第二行所示。后续的研究工作多通过空间正则技术,如通过擦除、多分支补充等方法试图扩大类别响应区域。虽然在响应区域上有一定的改善,但是现有的工作均忽略了保持目标结构特性的重要性,无法刻画目标的边缘、形状等特性。另外,现有方法的分类网络均采用Global Average Pooling(GAP)结构对特征进行聚合,这在一定程度上损失了目标的结构信息。

图1 CAM(第二行)与我们方法(第三行)的定位结果
研究内容
本文提出了一种两阶段的弱监督目标定位方法(SPA),从模型结构与类别响应图两个方面优化定位结果,提高响应掩模的准确度。整体方法框架如图2所示。
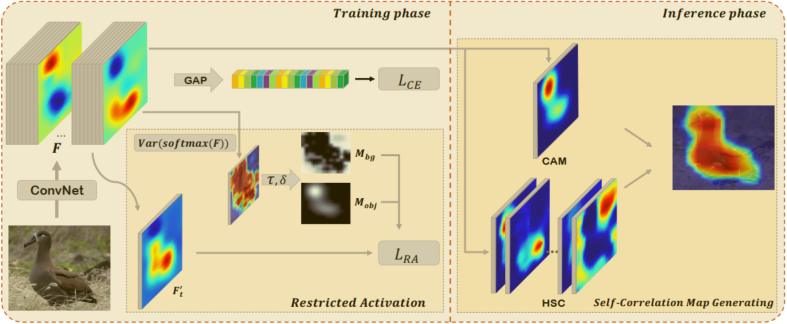
图2 SPA方法整体框架图
具体地,从模型结构方面,我们提出了受限激活模块。
现有方法中往往采用Global Average Pooling (GAP)+Softmax的分类结构,这种结构导致模型丢失目标结构信息,主要原因包括:
一,GAP结构将前景目标与背景区域混为一谈,限制了模型定位前景目标的能力;
二,无限制的类别响应特征图往往出现局部极高响应误导模型分类的现象,不利于模型准确定位到目标的位置。
因此,我们设计了一个简单有效的受限激活模块,主要包括两个部分:
一,我们首先通过计算每个特征位置在类别响应图上的方差分布得到粗略的伪mask, 用以区分前背景;
二,我们利用Sigmoid操作对类别响应特征图进行归一化,之后利用提出的受限激活损失函数引导模型关注目标前景区域。

图3 自相关图,第二行为一阶自相关图,第三行为二阶自相关图
在测试过程中,我们提出了高阶自相关图生成模块。
主流方法采用各种各样的空间约束提高目标响应区域,但是忽略了保持目标结构特征的重要性。我们首先提出了高阶相似性的定义,用以提取目标大范围的结构信息。图3展示了分别采用一阶和二阶相似性提取的目标相似区域,二阶相似性可以提取到更加完整的目标区域。基于提出的高阶相似性,我们提出了自相关图生成模块(如图4所示),将CAM的定位结果当做种子节点,分别提取前景与背景的相似性图,通过聚合前背景相似性图得到最终的定位结果。
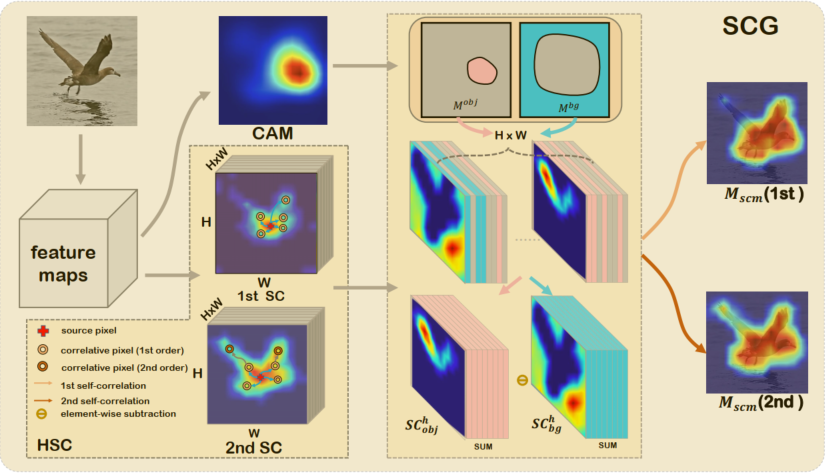
图4 高阶自相关图生成模块
算法流程见图5.

图5 高阶自相关图算法伪代码
实验结果
为了验证方法的有效性,我们在两个主流的Benchmark ILSVRC与CUB-200-2011上采用目标框与目标mask两种评测方式做了大量实验。基于目标框的评估指标为Loc Err(越低越好),基于目标mask的评估指标包括Peak-IoU, Peak-T与GT-Known, 值越高越好。
在ILSVRC数据集的结果:我们的方法基于CAM,在VGG16的躯干网络上,我们的方法达到了50.44% 的top-1 Loc.Err,达到了最优的结果,远远高于基线方法CAM,同时显著高于其他方法;基于Inception V3躯干网络,我们的方法同样远远优于基线方法,达到了最优一档。

表1 在ILSVRC数据集上与各种方法的比较结果。
在ILSVRC 按照Mask的评测结果:为了与SEM方法公平比较,我们只将SCG模块引入到各类方法。结果表示我们的方法全部带来了明显的提升。

表2 在ILSVRC按照Mask的比较结果。
在CUB-200-2011数据集的结果:同样采用CAM为基线方法,在VGG16与Inception V3的躯干网络上,远远超过基线方法结果,同时显著优于其他各类方法,达到了最优。具体地,在两个躯干网络上,相较于CAM,我们的方法分别取得了约12.5%和16.1%的绝对提高。

表3 在CUB-200-2011上与各种方法的比较结果。
更多实验结果请查阅我们的论文。
该项工作由中科院自动化所模式识别国家重点实验室与腾讯优图实验室和吉林大学人工智能学院合作完成,并获得了中科院自动化所-亮亮视野“第一视角计算”联合实验室的支持。
Xingjia Pan#, Yingguo Gao#, Zhiwen Lin#, Fan Tang*, Weiming Dong, Haolei Yuan, Feiyue Huang, Changsheng Xu.
"Unveiling the Potential of Structure-preserving for Weakly Supervised Object Localization".
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
论文地址:https://arxiv.org/abs/2103.04523
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CAMSPA” 就可以获取《(CVPR2021)基于结构保持的弱监督目标定位》专知下载链接






