神经计算机AI模型大突破! 训练时间每秒120万帧,创最新记录

新智元报道
新智元报道
来源:venture beat
编辑:雅新
【新智元导读】本周,IBM声称,其神经计算机系统达到了每秒120万帧的训练时间,创下了最新记录。IBM在AI模型训练上实现了大突破,可与最先进的技术相匹敌。网友对此表示简直不敢相信!
 AlexNet到AlphaGo零:计算量增长了300,000倍
AlexNet到AlphaGo零:计算量增长了300,000倍



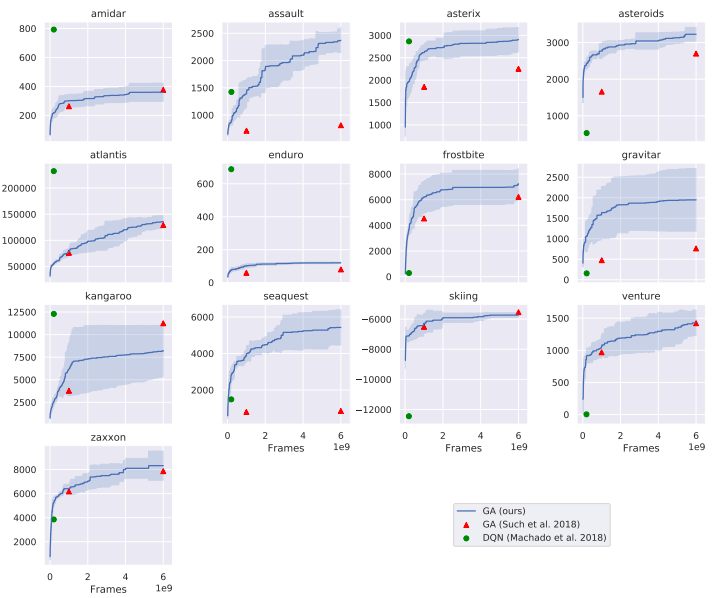
用Atari游戏测试AI



登录查看更多
相关内容

Arxiv
6+阅读 · 2019年5月3日



相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2019年5月3日