强化学习如何提升泛化性?UCL& UC Berkeley最新《深度强化学习泛化性》综述
【导读】强化学习的泛化性一直是个被人诟病的问题。最近来自UCL& UC Berkeley的研究人员对《深度强化学习》做综述,阐述了当前深度学习强化学习的泛化性工作,进行了分类和讨论。

摘要
深度强化学习 (RL) 中的泛化研究旨在产生 RL 算法,其策略可以很好地泛化到部署时新的未知情况,避免过度拟合其训练环境。如果要在现实世界的场景中部署强化学习算法,解决这个问题至关重要,在现实世界中,环境将是多样的、动态的和不可预测的。本综述是对这一新兴领域的概述,在已有研究的基础上,通过提供了一个统一的格式和术语来讨论不同的泛化问题。继续对现有的泛化基准以及解决泛化问题的方法进行分类。最后,对该领域的现状进行了批判性讨论,包括对未来研究的建议。本文认为对基准设计采用纯程序性内容生成方法不利于泛化,其提出快速在线适应和解决RL特定问题,并在未充分探索的问题环境中建立基准,如离线RL泛化和奖励函数变化。
https://www.zhuanzhi.ai/paper/57c8bfb50bc6da5e1be92f03224ba54a
引言
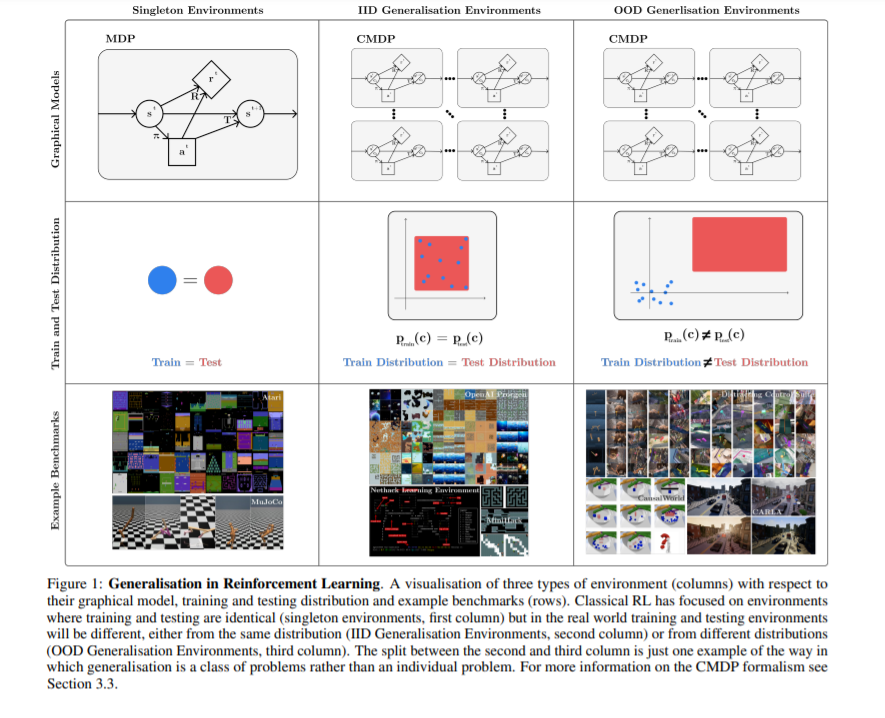
我们将泛化概念作为一个单一的问题来解决。我们提出了一种理解这类问题的形式化(建立在以前的工作[12,13,14,15,16]),以及在指定一个泛化问题时有哪些选择。这是基于特定基准所做出的选择,以及为验证特定方法而做出的假设,我们将在下面讨论这些。最后,我们在泛化中提出了一些尚未被探索的设置,但对于RL的各种现实应用仍然至关重要,以及未来在解决不同泛化问题的方法上的许多途径。我们的目标是使该领域的研究人员和实践者在该领域内外更容易理解,并使讨论新的研究方向更容易。这种新的清晰性可以改善该领域,并使更通用的RL方法取得稳健的进展。
综述结构。综述的结构如下。我们首先在第2节中简要描述相关工作,如其他概述。在第3节中,我们介绍了RL中泛化的形式化和术语,包括相关的背景。然后,在第4节中,我们继续使用这种形式化来描述用于RL泛化的当前基准,讨论环境(第4.1节)和评估协议(第4.2节)。我们将在第5节中对处理泛化的工作产生方法进行分类和描述。最后,我们将在第6节中对当前领域进行批判性的讨论,包括在方法和基准方面对未来工作的建议,并在第7节中总结综述的关键结论。
我们提出了关于泛化的一种形式主义和术语,这是建立在以往多部工作[12,13,14,15,16]中提出的形式主义和术语基础上的。我们在这里的贡献是将这些先前的工作统一为RL中被称为泛化的一类问题的清晰的正式描述。
我们提出了一个现有基准的分类,可以用来进行泛化测试,将讨论分为分类环境和评估协议。我们的形式主义让我们能够清楚地描述纯粹的PCG方法在泛化基准和环境设计方面的弱点:拥有一个完全的PCG环境限制了在该环境下进行研究的精确度。我们建议未来的环境应结合PCG和可控变异因素。
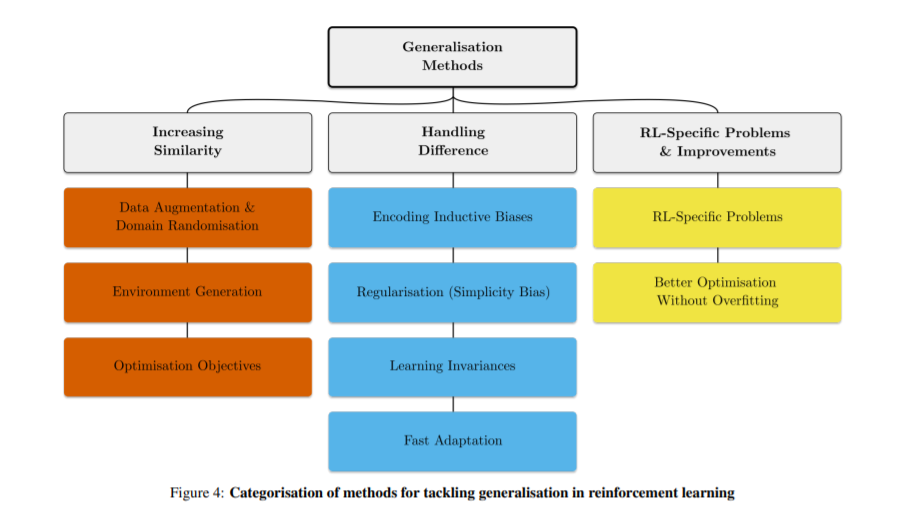
我们提出现有的分类方法来解决各种泛化问题,出于希望使它容易对从业人员选择的方法给出一个具体的问题。我们指出了许多有待进一步研究的途径,包括快速在线适应、解决RL特定的一般化问题、新颖的架构、基于模型的RL和环境生成。
我们批判性地讨论了RL研究的泛化现状,并提出了未来的研究方向。特别地,我们指出,构建基准将使离线的RL一般化和奖励功能变化取得进展,这两者都是重要的设置。此外,我们指出了几个值得探索的不同设置和评估指标:调查上下文效率和在连续的RL设置中工作都是未来工作的必要领域。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GDRL” 就可以获取《强化学习如何泛化?UCL& UC Berkeley最新《深度强化学习泛化性》综述》专知下载链接






