【伯克利胡戎航博士论文】视觉与语言推理的结构化模型,124页pdf,
Ronghang Hu (胡戎航)

胡戎航(Ronghang Hu)是Facebook人工智能研究(FAIR)的研究科学家。他的研究兴趣包括视觉和语言推理和视觉感知。他于2020年在Trevor Darrell教授和Kate Saenko教授的指导下获得UC Berkeley的计算机科学博士学位。2019年夏天和2017年夏天,他在FAIR做研究实习生,分别与Marcus Rohrbach博士和Ross Girshick博士一起工作。2015年获得清华大学学士学位。2014年,他在中国科学院计算技术研究所进行研究实习,得到了山时光教授和王瑞平教授的指导。
https://ronghanghu.com/
视觉与语言推理的结构化模型

视觉和语言任务(例如回答一个关于图像的问题,为参考表达做基础,或遵循自然语言指令在视觉环境中导航)需要对图像和文本的两种模式共同建模和推理。我们已经见证了视觉和语言推理的显著进展,通常是通过在更大的数据集和更多计算资源的帮助下训练的神经方法。然而,解决这些视觉和语言的任务就像用更多的参数建立模型,并在更多的数据上训练它们一样简单吗?如果不能,我们怎样才能建立数据效率高、易于推广的更好的推理模型呢?
这篇论文用视觉和语言推理的结构化模型为上述问题提供了答案——这些模型的架构考虑了人类语言、视觉场景和代理技能中的模式和规律。我们从表达式的基础开始,我们在第二章中展示了通过考虑这些表达式中的组合结构,我们提出的组合模块网络(CMNs)可以实现更好的准确性和泛化。在第三章中,我们使用基于与问题推理步骤一致的动态组合模块的端到端模块网络(N2NMNs)进一步解决了可视化的问题回答任务。在第四章中,我们扩展了模块化推理的研究,提出了基于可解释推理步骤的堆栈神经模块网络(SNMNs)。模块化推理之外,我们也提出构建环境敏感的视觉表征与Language-Conditioned场景图网络(LCGNs)。第五章对于关系推理和解决问题的阅读文本图像的问答迭代pointer-augmented多通道变形金刚。在第六章,我们说明了嵌入任务也需要结构化模型,并在第7章中提出了说话者-跟随者模型,其中说话者模型和跟随者模型互为补充。在所有这些场景中,我们表明,通过考虑任务中的结构和输入模式,我们的模型的执行和泛化明显优于非结构化对应模型。
目录内容



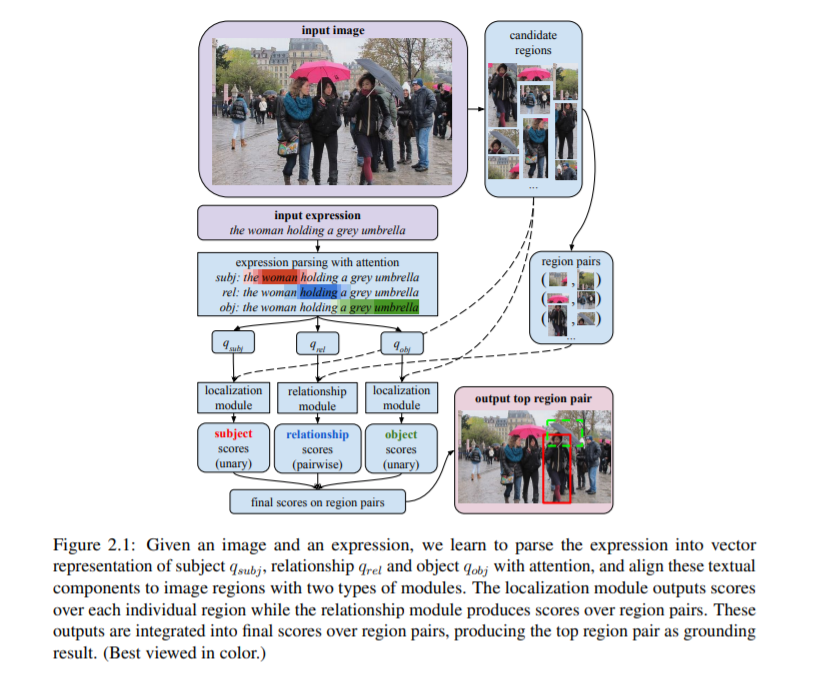
用于组合VQA的端到端模块网络
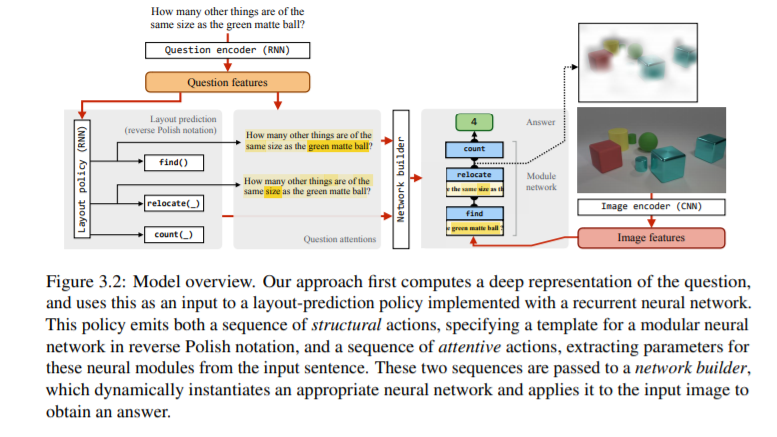
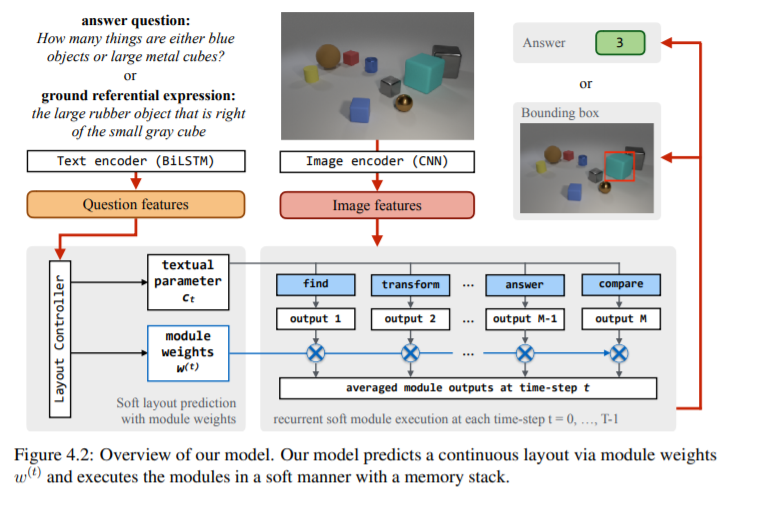
通过堆栈神经模块网络的可解释的神经计算
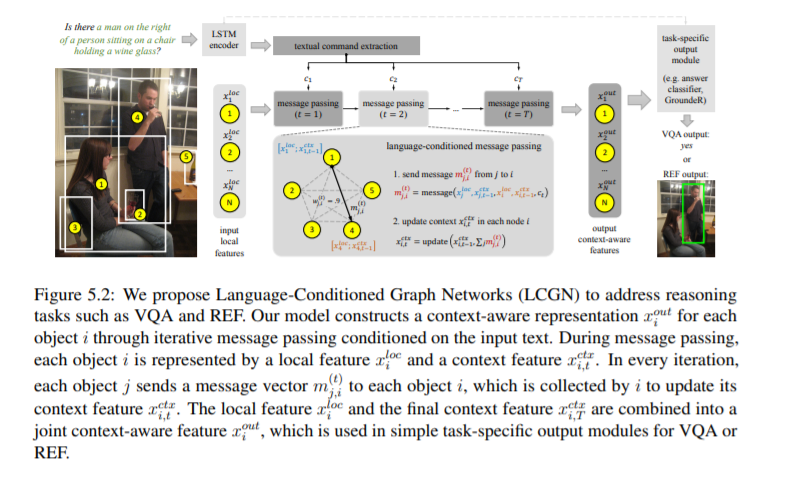
语言条件图网络
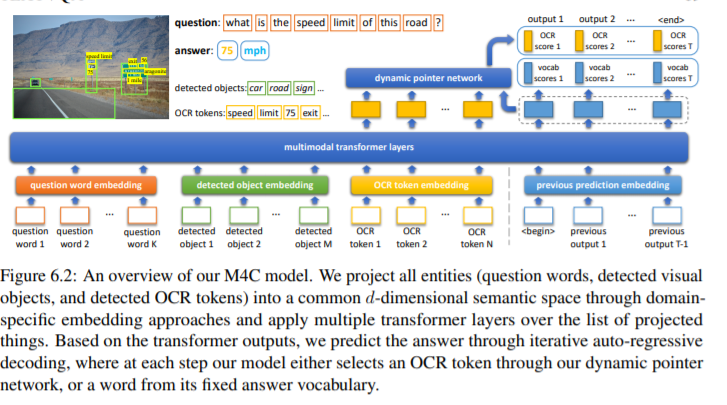
迭代指针增强的TextVQA多模态转换器
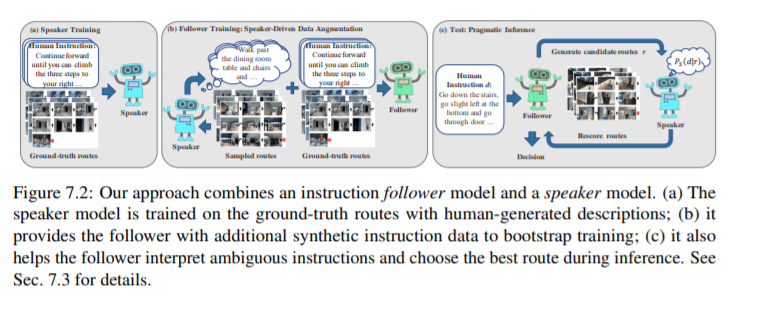
说话者-跟随者模式用于指导跟随
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SMVLR” 可以获取《【伯克利胡戎航博士论文】视觉与语言推理的结构化模型,124页pdf》专知下载链接索引





