17篇必看[知识图谱Knowledge Graphs] 论文@AAAI2020
【导读】2020 年 2 月 7 日-2 月 12 日,AAAI 2020 在美国纽约举办。Michael Galkin撰写了AAAI2020知识图谱论文相关研究趋势包括:KG-Augmented语言模型,异构KGs中的实体匹配,KG完成和链路预测,基于kg的会话人工智能和问题回答,包括论文,值得查看!

知识图谱增强的语言模型
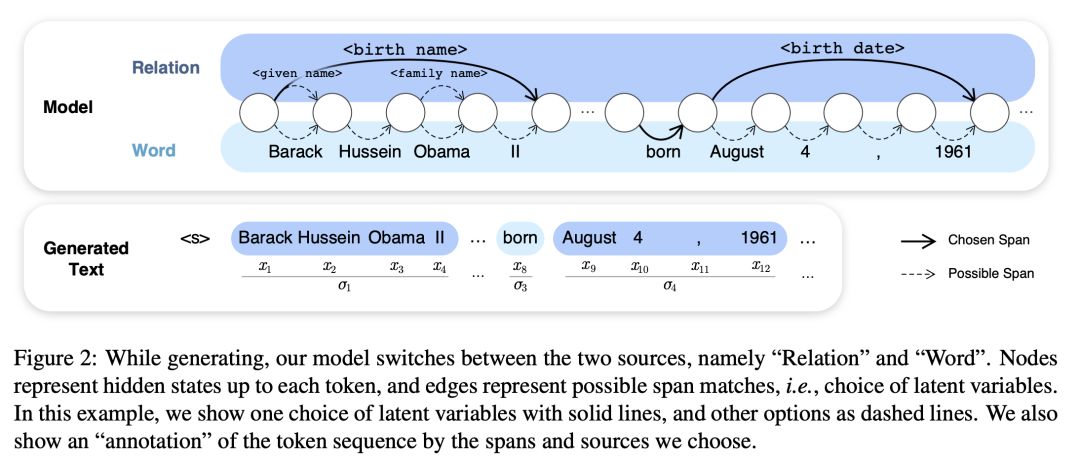
Hiroaki Hayashi, Zecong Hu, Chenyan Xiong, Graham Neubig:
Latent Relation Language Models. AAAI 2020潜在关系语言模型
本文提出了一种潜在关系语言模型(LRLMs),这是一类通过知识图谱关系对文档中词语的联合分布及其所包含的实体进行参数化的语言模型。该模型具有许多吸引人的特性:它不仅提高了语言建模性能,而且能够通过关系标注给定文本的实体跨度的后验概率。实验证明了基于单词的基线语言模型和先前合并知识图谱信息的方法的经验改进。定性分析进一步证明了该模型的学习能力,以预测适当的关系在上下文中。
K-BERT: Enabling Language Representation with Knowledge Graph
K-BERT:使用知识图谱实现语言表示
异构KGs中的实体匹配
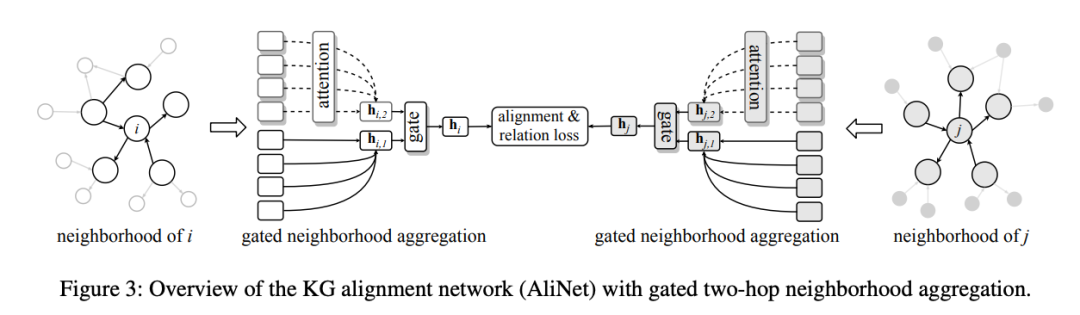
Knowledge Graph Alignment Network with Gated Multi-hop Neighborhood AggregationZequn Sun (Nanjing University)*; Chengming Wang (Nanjing University); Wei Hu (Nanjing University); Muhao Chen (UPenn); Jian Dai (Alibaba Group); Wei Zhang (Alibaba Group); Yuzhong Qu (Nanjing University)
知识图谱补全与链接预测
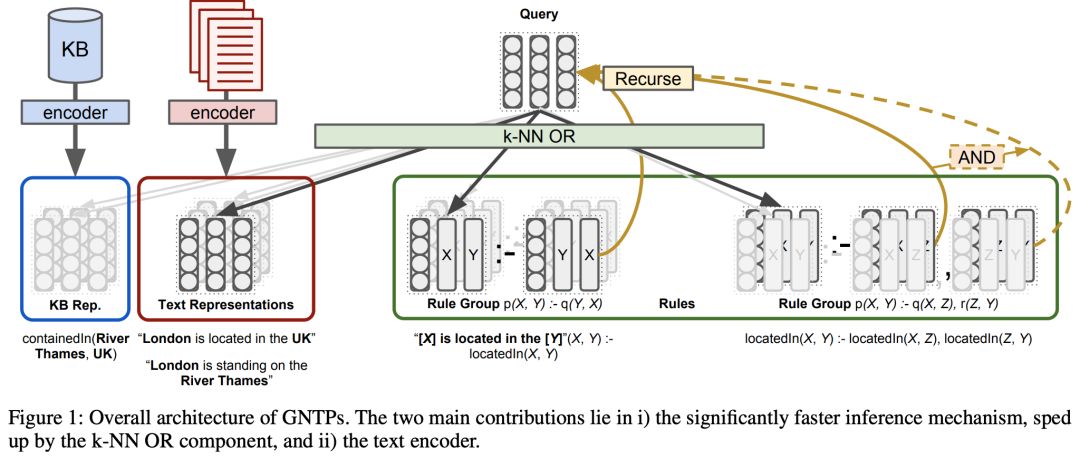
Differentiable Reasoning on Large Knowledge Bases and Natural LanguagePasquale Minervini (University College London)*; Matko Bošnjak (DeepMind / UCL); Tim Rocktäschel (Facebook AI Research & University College London); Sebastian Riedel (UCL); Edward Grefenstette (Facebook AI Research)
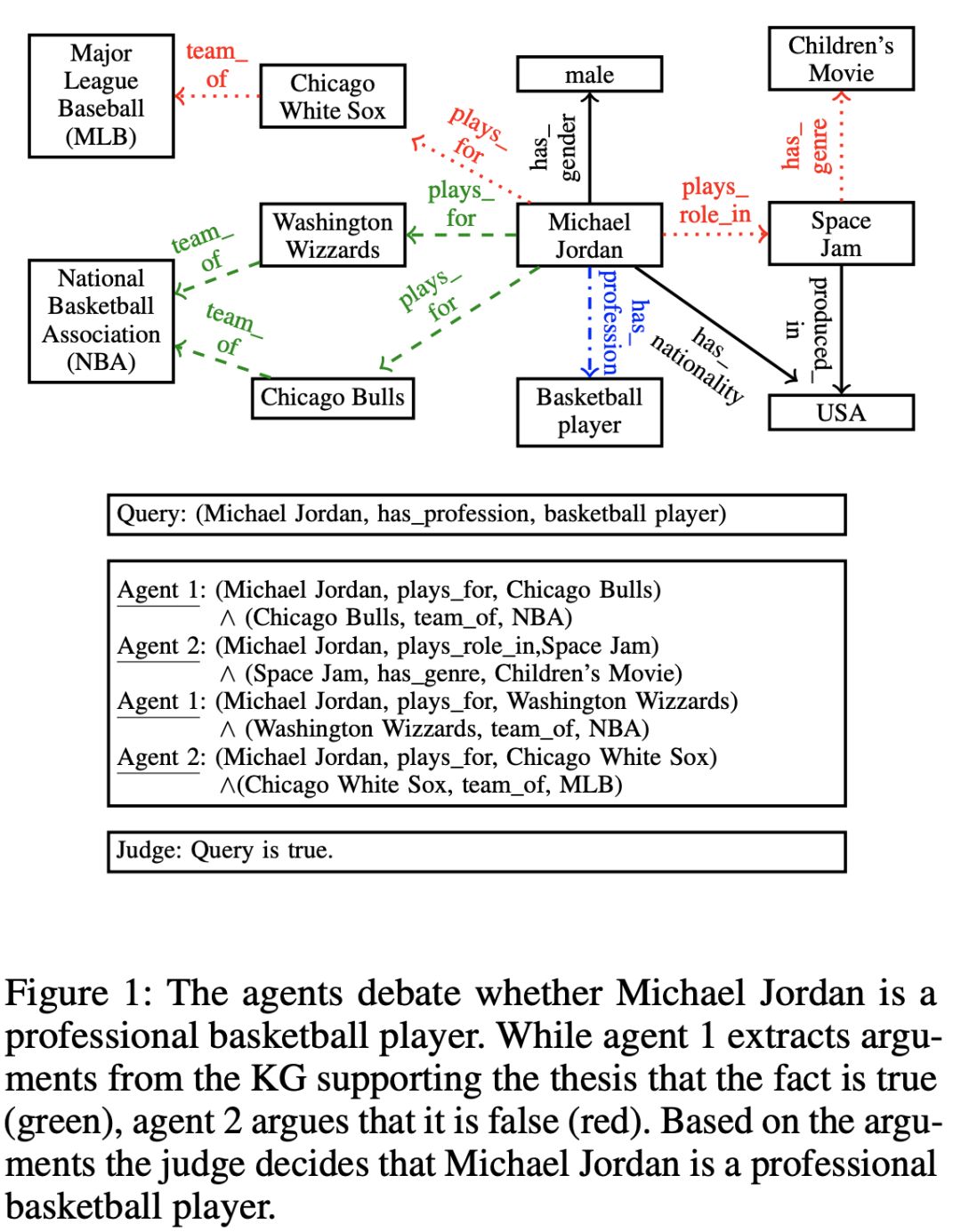
Reasoning on Knowledge Graphs with Debate DynamicsMarcel Hildebrandt (Siemens )*; Jorge Andres Quintero Serna (Siemens); Yunpu Ma (LMU); Martin Ringsquandl (Siemens); Mitchell Joblin (Siemens); Volker Tresp (Siemens AG and Ludwig Maximilian University of Munich )
知识图谱会话与问答
Towards Scalable Multi-Domain Conversational Agents:The Schema-Guided Dialogue DatasetAbhinav Rastogi (Google)*; Xiaoxue Zang (Google); Srinivas Sunkara (Google); Raghav Gupta (Google); Pranav Khaitan (Google)

参考链接:
https://medium.com/@mgalkin/knowledge-graphs-aaai-2020-c457ad5aafc0
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KG17” 就可以获取《知识图谱Knowledge Graphs17篇论文 @AAAI2020》专知下载链接







