多模态图神经网络解决短视频推荐难题
对于短视频推荐等多模态推荐感兴趣的大佬,欢迎来带飞一波~
今天分享一篇发表在顶会ACM Multimedia 2019 [1]上,面向短视频推荐的多模态图卷积神经网络文章,相应的代码也开源在github[2]。作者在抖音数据集tiktok,快手数据集Kwai上都做了广泛的实验,实验结果表明MMGCN的性能能够显著超越目前主流的多模态推荐方法。

注:公众号经营几个月以来,得到了很多同学的关注和支持,在此表示感谢!不过今年以来,因为手头的一些工作而耽误了创作,在此表示抱歉。后续我会恢复创作!
另外,公众号后续偶尔会推一些广告文,但是我保证会带一篇原创文或高质量转载文。再次感谢大家的支持!你们的支持是我创作的最大动力来源!
Motivation
为了给短视频内容分享平台提供高质量的推荐结果,我们不仅要考虑用户和内容的交互行为,还要考虑内容本身多模态的特征 (如视觉、语音、文本)。目前的多模态推荐方法主要是利用物品本身的多模态内容来丰富「item侧」的表示;但是很少会利用到user和item之间的交互交互来提升「user侧」的表示,进而捕获用户对不同模态特征的「细粒度偏好」。
在这篇文章中,作者主要是想利用用户和短视频的交互行为来指导每种模态下的表征学习,主要是利用了GNN的信息传递思想,来学习模态特定的用户表征和短视频表征。具体而言,作者将用户-短视频的交互行为二分图依据短视频的多模态特征 (图像,文本,语音) 切分为三个模态子图,每种子图的拓扑结构一样,只有图的结点属性是不一样的。汇聚的时候不仅考虑了邻域的拓扑结构,还考虑了邻域结点的模态属性特征,让模型自适应地学习究竟是拓扑结构还是物品结点的模态特征决定了用户的交互行为。
对多模态特征的「进行区分」对于深入理解用户的偏好有帮助:
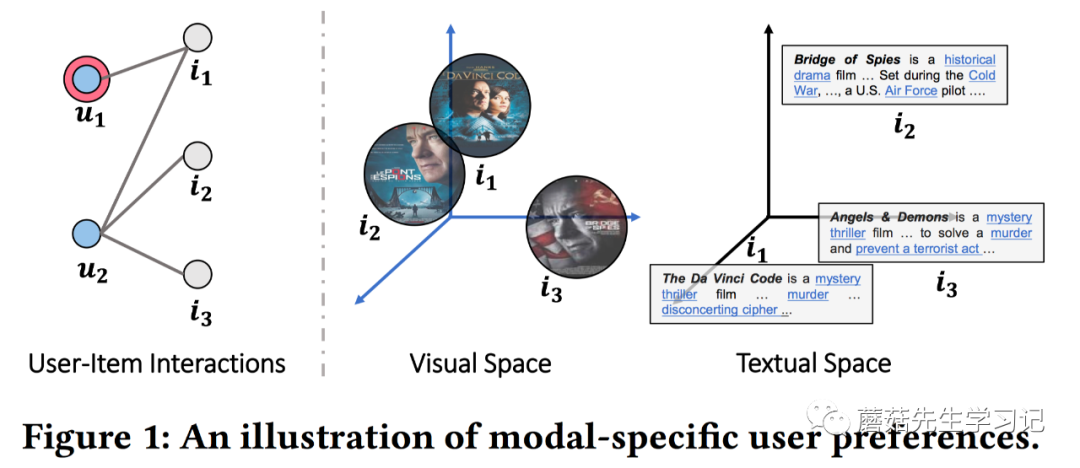
-
「不同模态的特征之间存在语义差异」。如图1,尽管 和 在视觉模态空间很相似,但是在文本模态空间却并不相似,一个是恐怖片、一个是战争片,主题并不一样。如果忽视了这样的模态差异,例如只使用视觉特征的话,会误导视频的表征。 -
「同一个用户对不同模态可能有不同的品味」。例如,一个用户可能对视频某些帧的画面感兴趣,但是却对糟糕的视频的背景音乐很失望。 -
「不同的模态可以作为不同的角度、途径来发掘用户的兴趣」。如图1,如果用户 更关注视频帧,则 更适合推荐给他,因为 和 在视觉模态更近似;如果 更关注文字描述,则, 更适合推荐给他,因为 和 在文字模态更近似。
遗憾的是,目前的工作都主要把不同的模态特征作为整体来统一对待,缺乏对特定模态的用户偏好的建模。
作者希望能够通过关注user-item在不同模态空间下的信息交互,借鉴GNN的信息传播机制来编码用户和视频在不同模态下的高阶关系,进而捕获特定模态内容下用户的偏好。
Solution
为此,作者提出了多模态图卷积神经网络 (Multi-modal Graph Convolution Network, MMGCN),在不同模态下构造用户-物品二分交互图 (Modality-aware Bipartite user-item Graph)。
-
一方面,从用户角度,用户本身的历史交互行为item能够反映user的个性化兴趣,即从item中聚合特征到用户表征是合理的; -
另一方面,从物品角度,交互过某个item的user group能够间接追踪物品之间的相似性,因此从user中聚合特征到物品表征也是合理的。
先从总体上概括MMGCN结构上的亮点。
-
首先是「汇聚层」,「各自地」在不同的「模态二分图」下,从交互过的items中聚合相应的模态特征到用户表征,同理,可以利用user groups来汇聚得到物品表征。也就是说不同模态的汇聚操作是每个模态二分图分开「单独进行」的。
-
接着是「融合层」,每个子图下,都会有个融合操作来融合邻域结构信息,自身模态属性信息以及跨模态联系信息,也就是说「融合后的表征」会间接地融合所有模态的特征,又会作为该子图的下一个GNN汇聚层的输入。
汇聚和融合操作迭代执行多次,就能捕获user和item之间多跳的邻居信息以及跨模态之间的协同信息。最终,预测的时候可以分别拼接user和item在所有子图下的表征向量,并计算拼接后的user和item的表征之间相似性,从而预测user对item的感兴趣程度。
Formulation
作者不是把所有模态的信息作为整体来统一对待,而是每种模态进行区分对待。首先基于user-item交互数据来构造二分图, ,每条边 对应一条user-item观测数据。除此之外,对于每个item ,都有多种模态特征,即:视觉 (visual) 、声觉 (acoustic)、文本 (textual)。具体的,使用 作为模态的指示函数, 分别表示视觉、声觉、文本。为了正确捕获特定模态下的用户偏好,作者将 切分为三个子图 。相比于原图,子图只改变了每个item结点的属性特征,只保留其「相对应的模态的特征」,而整体的拓扑结构和原图 是一致的。例如 下,只有对应的「视觉」模态特征可以在该子图下使用。
整体的模型结构如下所示,不同模态域的汇聚和融合分别进行,最后相加不同模态域得到的表示作为最终的表示,并通过点乘进行预测。
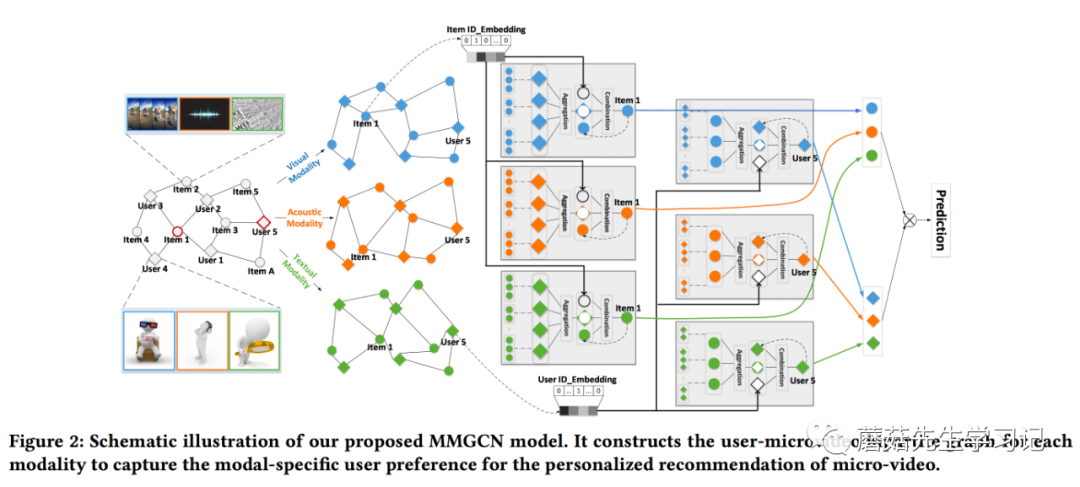
Network Architecture
1. Aggregation Layer
对于用户来说,用户历史交互过的物品能够反映用户的兴趣,故可以对物品进行汇聚操作来丰富用户的表征;对于物品来说,交互过物品的「user group」可以作为物品除自身模态特征之外的补充信息,故可以对用户进行汇聚来提升物品的表征。
基于信息传递机制,对「模态子图」 中,任意一个user或item结点,我们采用一个汇聚函数 来量化「从邻域结点传播来的」信息的影响。以user为例,汇聚得到的模态特定的表征如下:
表示子图 user结点 的邻域item结点。 捕获了「拓扑结构」特征。
作者采用了两种形式。
-
「Mean Aggregation:」 采用平均池化操作来汇聚模态特定的特征,再加一个非线性变换。
是模态 下item 的表示。 是线性变换矩阵 (下标1只是编号,代表本文中使用的第一个参数矩阵)。平均池化操作假设了所有邻域结点的影响是等价的。
注意,初始状态下, 使用预先提取的模态 的特征向量来表示。
-
「Max Aggregation」: 使用最大池化操作来进行特征选择,
这样的好处是不同的邻域结点的影响力不同。
item结点的汇聚操作同理。不同的是,对于user结点的初始模态表征 ,作者使用的是随机初始化向量的方法(每种模态对应1种随机向量)。
2. Combination Layer
这个层的目标是融合aggtegation layer得到的来自邻域结点的「结构化信息 (structural information)」 ,结点「自身内在信息 (intrinsic information)」 以及沟通不同模态的「联系信息 (modality connection information)」 。形式化为:
和上述提到的 同理,是user的初始modal-specific表示,只不过作者实际上采用的是随机初始化方式,而 是pre-extracted item modal-features。 是 维user ID的嵌入表示,是所有模态间共享的,「作为沟通不同模态信息的桥梁。」
对于 函数的设计,
-
作者首先将 和 融合起来,即将 通过非线性变换映射到 维空间,再加上 。
。这样子变换完后,不同的模态信息在同一个超平面上了,是可比的。 的好处是沟通了不同模态表示之间的差距,同时在反向传播的过程中,信息可以跨模态进行传播(the ID embedding essentially bridges the gap between modal-specific representations, and propagates information across modalities during the gradient back-propagation process)。形象的说,例如,视觉模态 下的反向传播误差能影响 , 又能进一步影响模态 下的模态特定的参数。这样就达到了不同模态之间互相联系。
-
接着将 和 融合起来,进一步分为了两种:
-
「Concatenation Combination」:
是concat操作,。
-
「Element-wise Combination」:
。
第 层的combination layer的输出,即 的输出,对于user,作者用 表示;对于item,作者用 表示。
3. Recursion Formula
叠加多层汇聚层和融合层,递推式子如下:
值得强调的是,对于user来说,初始化的表征 使用随机初始化的模态特定的 ;对于item来说,初始化的intrinsic information 使用预先提取的「模态特征」 。
构成:
-
融合了从 「item」侧汇聚到的modal m-specific 「模态信息」 。 -
自身的modal-specific信息 (第 的combination layer的输出,类似 「self-connection」操作) -
跨模态的联系信息 。
因此作者说 不仅刻画了用户对于模态 下item特征的偏好,还考虑了跨模态之间的交互信息的影响力。
进一步可以观察下作者在github[2]的代码实现,核心forward,
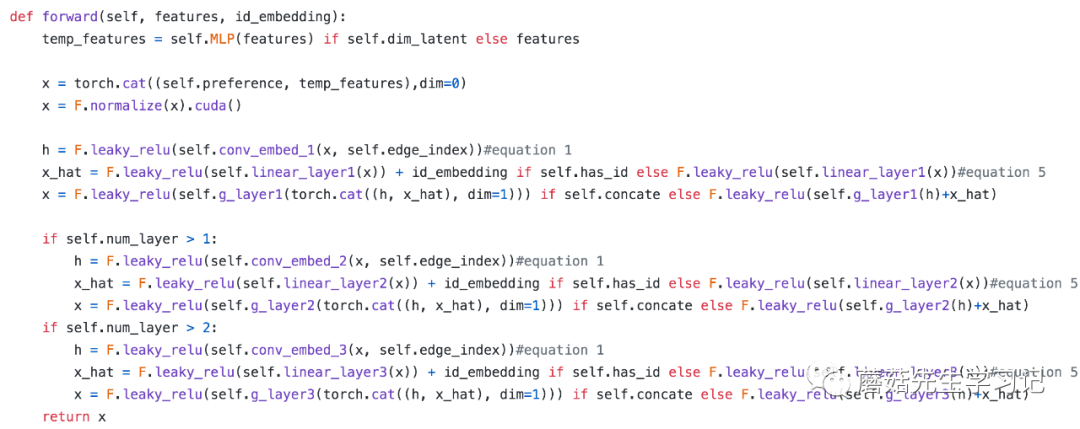
可以重点关注下 ,初始是features;第一层输出的 作为第二层的输入,以此类推。
Model Prediction
上述总共叠加了 层。最后,作者累加了所有模态下最后一个GNN层的输出,作为user或item最终的表示,
预测user-item pair的话,使用二者点乘形式进行预测, 。
最后作者使用和NGCF一样的BPR Loss进行优化。不再累赘。
Evaluation
在实验部分作者使用了头条数据集tiktok,快手数据集Kwai,movie-lens进行实验。头条数据集3种模态都有,快手只有文本和图像。movie-lens作者手动爬取了youtube的预告片,并用resnet50提取关键帧的特征,使用FFmpeg抓取声音片断并用VGGish提起声音特征,使用Sentence2Vector从文本描述中提取特征。这个工作量是真大。
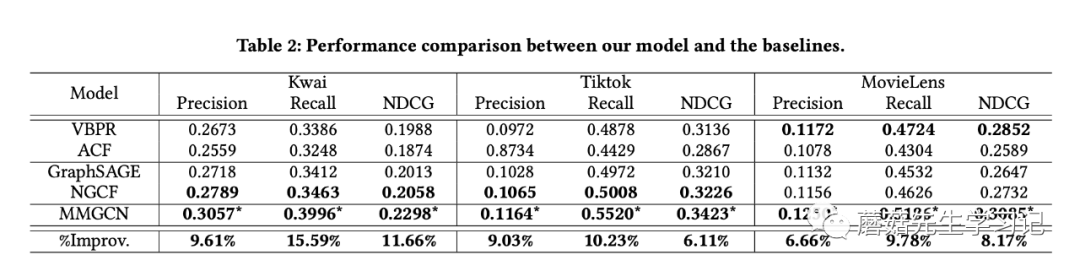
另外,作者评估的时候,对于测试集中每个正样本observed user-item pair,随机抽了1000个unobserved user-item pairs作为负样本,然后用precision@k, recall@k, ndcg@k进行评估。这个是可取的,但是这种采样评估的方法实际上受到了不少新工作(e.g., KDD20 best paper[3])的质疑。显然,所有的unobserved user-item pairs全部作为负样本,这样的评估显然更客观,也更有说服力。本文的实验结果如下:
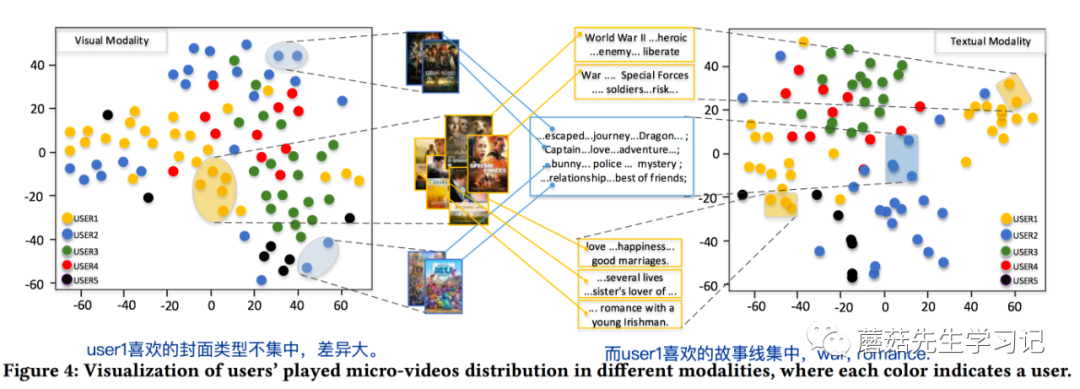
作者可视化用户对同1个item的不同模态的特征的偏好不一致性也值得学习。通过分析学习到的item的多模态降维表示,并抽取部分用户交互过的item,看交互过的item的降维表示的分布情况,例如,在视觉模态下,交互过的item比较分散,说明这些items的封面/帧/图像差异较大;而文本模态下,交互过的item表示向量点比较集中。则说明了用户对视觉模态没有太多的偏好,不是对其兴趣起决定性作用;而对文本域的模态有典型的偏好,例如喜欢看浪漫主题的电影。如下图中的user 1,左图视觉域点分布很分散;右图文本域集中在war和romance主题。相反,有的人可能很关注视觉模态,比如爱看封面美女的电影,那么其视觉模态下的表示就很集中;而可能这些电影主题差异很大,即文本模态下很分散。
Summarization
作者没有讨论参数复杂度。这里面有非常多的参数。尤其是针对每个user和item的modal-specific参数,即带 下标的参数,尤其是user侧,如 ,全局的 。我个人对此保持疑惑,因为在大规模的推荐系统中,user的数量非常多,而交互数据又非常稀疏。给每个user都分配如此多的参数,很多参数估计都得不到很好的学习,同时训练速度也很慢。可能user侧也需要引入profile信息比较好。另外,不是所有的items都有丰富的模态特征,大部分items可能缺乏模态特征,即,不同子图的拓扑结构可能会因为结点缺失相应的特征而导致不相同,这种情况下如何处理呢?这些都值得思考。
References
[1] MM2019: MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video: https://liqiangnie.github.io/paper/MMGCN.pdf
[2] Github源码: https://github.com/weiyinwei/MMGCN
[3] On Sampled Metrics for Item Recommendation (KDD '20 best paper): http://walid.krichene.net/papers/KDD-sampled-metrics.pdf