
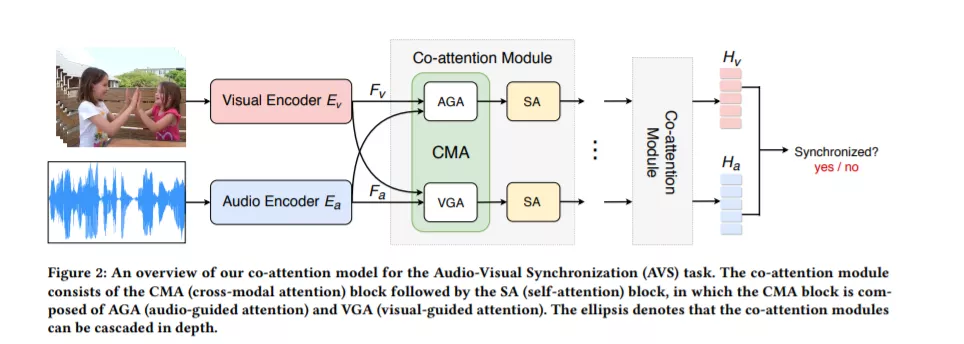
在观看视频时,视觉事件的发生往往伴随着声音事件,如唇动的声音,乐器演奏的音乐。视听事件之间存在着一种潜在的相关性,通过解决视听同步的代理任务,可以将其作为自监督信息来训练神经网络。在本文中,我们提出了一种新的带有共同注意力机制的自监督框架来学习无标记视频中的通用跨模态表示,并进一步使下游任务受益。具体而言,我们探讨了三个不同的共注意模块,以关注与声音相关的区分视觉区域,并介绍它们之间的相互作用。实验表明,与现有方法相比,我们的模型在参数较少的情况下,取得了较好的效果。为了进一步评估我们方法的可推广性和可迁移性,我们将预训练的模型应用于两个下游任务,即声源定位和动作识别。大量的实验表明,我们的模型可以提供与其他自监督方法竞争的结果,也表明我们的方法可以处理具有挑战性的场景包含多个声源。
https://arxiv.org/abs/2008.05789
成为VIP会员查看完整内容
相关内容

Arxiv
4+阅读 · 2017年11月27日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2017年11月27日