先过滤后解析:斯坦福开源数据解析引擎Sparser,解析提速22倍

我们将在本文中介绍 Sparser(http://www.vldb.org/pvldb/vol11/p1576-palkar.pdf) (请点击这里查看代码 https://github.com/stanford-futuredata/sparser) ,它来自斯坦福 DAWN 团队最近的一个研究项目,该项目解决了这个性能瓶颈。Sparser 的关键见解是,利用 SIMD 加速过滤函数在解析之前过滤数据。在 JSON、Avro 和 Parquet 数据上,Sparser 的速度比最先进的解析器最多快 22 倍,并且能将 Apache Spark 中的端对端的查询运行时间最多提高 9 倍。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
在数据库社区中,原始数据流的解析很慢不是一个新问题。在 2017 年的 VLDB 大会上,微软的研究人员展示了 Mison(https://www.microsoft.com/en-us/research/publication/mison-fast-json-parser-data-analytics/) ,这是一种新的 JSON 解析器,它利用 SIMD 命令在每个 JSON 记录上构建结构化的索引,从而在不完全反序列化记录的情况下实现高效的字段投影。尽管 Misaon 比之前最先进的解析器(如 RapidJSON http://rapidjson.org/index.html) 的速度有显著的提高,但是它仍然有很大的改进余地。当我们在 JSON 数据样本上测量 Mison 的解析吞吐量时,发现它平均每个字节仍然执行多个 CPU 周期。与简单的逐字节 SIMD 数据扫描相比(解析的理论上限),Mison 的速度慢了几个数量级。
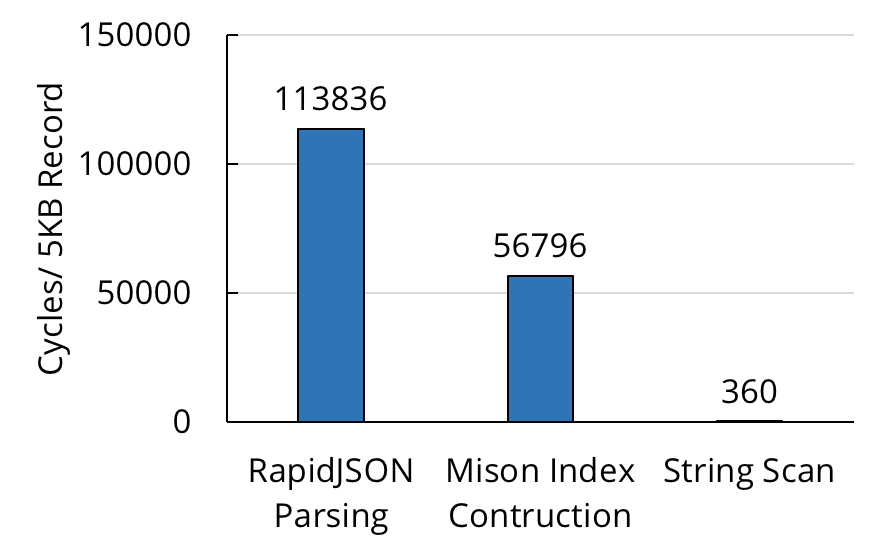
使用最先进的解析器在 L1 缓存中解析单个 5KB 大小的 JSON 记录所花费的 CPU 周期, 与在同一缓冲区中使用 SIMD 指令搜索单字节值的扫描比较。性能差异超过 100 倍。
Mison 基于以前的解析器上的改进来自一个简单的想法:先投影再解析。也即,获取大多数用户指定的,在 JSON 数据查询中找到的投影,并且先投影再解析,从而只解析用户需要的必要字段。
受到 Mison 的启发,Sparser 采用了一种类似的想法:假如我们把过滤器也下推到解析器,会怎样?这对于数据分析中的探索性查询来说,尤其有帮助,因为这些查询通常都具有高度选择性。比如,在读取 JSON 或 CSV 数据的 Databrick 的云设备上,当我们查看跟 Spark SQL 查询有关的分析元数据时,发现 40% 的查询选择了不到 20% 的记录。在研究人员对来自 Censys(用于互联网端口扫描的搜索引擎)的 JSON 数据的查询上,我们进行了类似的分析,发现对这些查询甚至有更高的选择性。这个观察结果带来了优化解析的一个直观的想法:如果 JSON 记录不会出现在呈现给用户的最终结果中,那么我们就根本不该解析它!
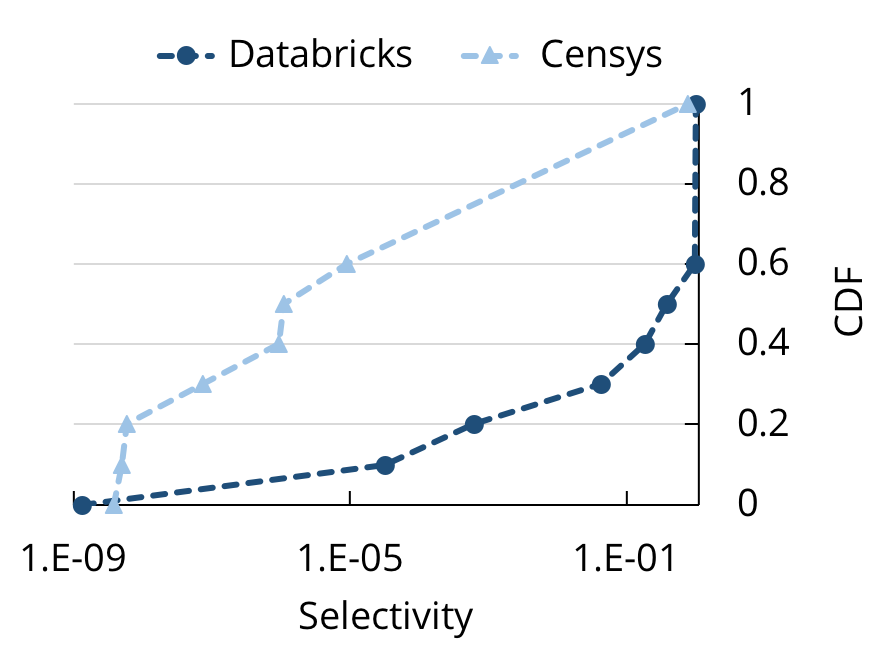
在读取 JSON 和 CSV 数据的 Databricks 上,来自 Spark SQL 的有选择性的 CDF,和在 Censys 搜索引擎上,研究人员对 JSON 数据的查询。这两组查询都具有高度选择性。
基于这个见解,Sparser 把 JSON 和用户指定的 SQL 查询作为输入,通过以下步骤评估解析之后 JSON 文件上的查询:
Sparser 从查询中提取谓词,并把每个谓词编译成一个或多个原始过滤器(Raw Filter,简称 RF)。RF 是 SIMD 高效的过滤函数,可以遍历原始数据和丢弃记录;RF 可以允许假阳性,但不允许假阴性。
Sparser 在所有候选 RF 上运行一个基于成本的优化器,并生成一个 RF 级联,也即一系列 RF,这些 RF 可以最大化给定查询和原始数据的解析吞吐量。Sparser 在原始数据上应用所选择的 RF 级联,并丢弃那些没有通过级联的记录。最后,其余的行传递给下游的解析器,如 RapidJSON 或 Mison。

左边:传统解析器。右边:Sparser, 利用快速的基于 SIMD 原始过滤器先过滤再解析,具有假阳性,但不具有假阴性。
因为 Sparser 的优化与先前的解析工作是正交的, 所以 Sparser 实际上是对其他解析器的补充,其中包括最先进的那些解析器,如 Mison。此外,Sparser 还推广到其他更结构化的数据形式,如 Avro 和 Parquet。这些数据形式不依赖显式字符(如 JSON 中的‘{’和‘}’)来划分记录;因此,Mison 的结构化索引技术(扫描这些字符)无法应用。
为了衡量 Sparser 的有效性,首先,我们在一台机器上对它进行基准测试,与 RapidJSON 和 Mison 比较。我们从 Censys 下载了一个 16GB 大小的 JSON 记录,评估了 9 个不同选择度的查询,测量了它们使用每个解析器在用 Sparser 和不用 Sparser 情况下的运行时间。
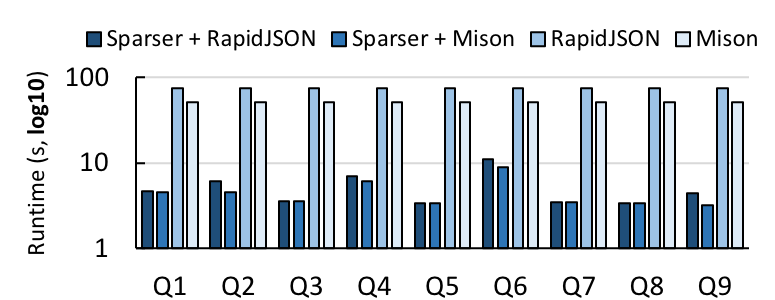
在 Censys 数据集上,Sparser 与 RapidJSON 和 Mison 的对比。在所有我们进行基准测试的 9 个查询上,Sparser 最多把解析时间提高了 22 倍。
当与 RapidJSON 或 Mison 组合使用时,Sparser 平均减少了大约 1 个数量级的解析时间,最多缩短了 22 倍。因为这些查询具有较低选择性,Sparser 的原始过滤器可以有效地过滤那些不需要解析的记录,即使与 Mison 结合使用时也是如此。因此,原始过滤对于 Mison 的投影优化是个补充。
接下来,我们把 Sparser 与 Apache Spark 集成,并将它和 Spark 常用的 Jackson JSON 解析库结合起来。我们选择了更多的记录,这次有来自 Censys 的 652GB 大小的 JSON 记录,还有来自推特的 68GB 大小的推文。然后,对于每个数据集,我们对 1)从磁盘下载数据所耗费的时间,2)在 Spark SQL 中端到端的查询运行时间,其中包括从磁盘加载数据的时间、解析数据的时间和评估查询的时间,3)查询评估运行时间本身进行基准测试。
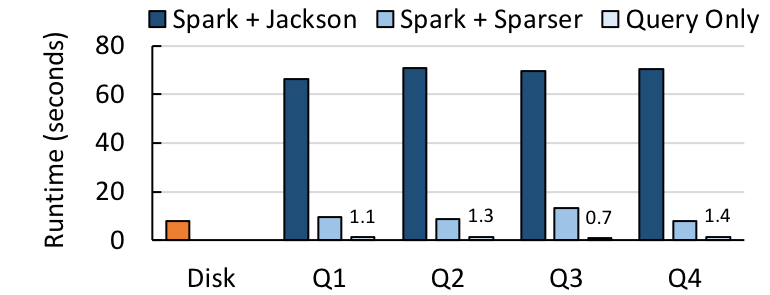
在推文查询(左侧)和 Censys 查询(右侧)上,Spark + Sparser 与 Spark + Jackson 的对比情况。Sparser 将查询时间最多提高了 9 倍。实验是在 10 个节点 GCE 集群上的 Spark 2.2 中进行的。
对于 4 个推文查询,Sparser 把端到端运行时间最多提高了 9 倍,而对于 9 个 Censys 查询,速度则最多提高了 4 倍。对于这两种情况而言,回复查询的时间仅仅比从磁盘加载文件所需时间多了一点。
最后,为了在 Avro 和 Parquet 上对 Sparser 进行基准测试,我们把一个小一些的推文数据集(32GB 大小)转换成这两种格式,并对同样的 4 个推文查询进行基准测试。我们发现,即使对这些优化过的数据格式,Sparser 还是可以加速查询速度,最多可以提高 5 倍。
在 Avro 格式(左侧)和 Parquet 格式(右侧)上对推文查询使用 Sparser 的比较。Sparser 分别将查询时间最多提高了 5 倍和 4.3 倍。
简单回顾一下,Sparser 是新的解析引擎,用于非结构化和半结构化的数据格式,例如 JSON、Avro 和 Parquet。
Sparser:
用原始过滤器过滤后再解析,丢弃那些不需要用假阳性率解析的记录
用高效的优化器选择级联的原始过滤器
提供超过现有解析器 22 倍的加速度
Sparser 是开源软件,并且还在开发中;您可以看看我们在 GitHub 上发布的 alpha 版本代码(https://github.com/stanford-futuredata/sparser)。 最近,我们在旧金山召开的 Spark+AI 峰会上演示了 Sparser(相关录像 https://vimeo.com/274496506)。 我们将于 8 月 30 日(周四)在里约热内卢的 2018 年 VLDB 大会上再次演示 Sparser。请查看我们准备印制的论文(http://www.vldb.org/pvldb/vol11/p1576-palkar.pdf) 以获得更多信息;有其他问题的话,欢迎写邮件联络我们,电邮地址是 shoumik@cs.standford.edu 和 fabuzaid@cs.standford.edu。
阅读英文原文:
https://dawn.cs.stanford.edu/2018/08/07/sparser/

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!