
【导读】文本分类是自然语言处理汇总的基础性任务,伴随机器学习尤其是深度学习模型的发展,文本分类算法也在革新换代。最近,来自Snapchat、Google、NTU、Tabriz、微软等学者发表了关于《深度学习文本分类》的综述论文,42页pdf215篇参考文献,详细回顾了近年来发展起来的150多个基于深度学习的文本分类模型,并讨论了它们的技术贡献、相似性和优点。我们还提供了40多个广泛用于文本分类的流行数据集的摘要。

基于深度学习的模型已经在各种文本分类任务中超越了传统的基于机器学习的方法,包括情感分析、新闻分类、问题回答和自然语言推理。在这项工作中,我们详细回顾了近年来发展起来的150多个基于深度学习的文本分类模型,并讨论了它们的技术贡献、相似性和优点。我们还提供了40多个广泛用于文本分类的流行数据集的摘要。最后,我们对不同深度学习模型在流行基准上的表现进行了定量分析,并讨论了未来的研究方向。
https://www.arxiv-vanity.com/papers/2004.03705/
1. 概述
文本分类又称文本归档,是自然语言处理(NLP)中的一个经典问题,其目的是将标签或标记分配给文本单元,如句子、查询、段落和文档。它的应用范围很广,包括问题回答、垃圾邮件检测、情绪分析、新闻分类、用户意图分类、内容审核等等。文本数据可以来自不同的来源,例如web数据、电子邮件、聊天、社交媒体、机票、保险索赔、用户评论、客户服务的问题和答案等等。文本是极其丰富的信息来源,但由于其非结构化的性质,从文本中提取见解可能是具有挑战性和耗时的。
文本分类可以通过人工标注或自动标注来实现。随着文本数据在工业应用中的规模越来越大,文本自动分类变得越来越重要。自动文本分类的方法可以分为三类:
- 基于规则的方法
- 基于机器学习(数据驱动)的方法
- 混合的方法
基于规则的方法使用一组预定义的规则将文本分类为不同的类别。例如,任何带有“足球”、“篮球”或“棒球”字样的文档都被指定为“体育”标签。这些方法需要对领域有深入的了解,并且系统很难维护。另一方面,基于机器学习的方法学习根据过去对数据的观察进行分类。使用预先标记的示例作为训练数据,机器学习算法可以了解文本片段与其标记之间的内在关联。因此,基于机器学习的方法可以检测数据中的隐藏模式,具有更好的可扩展性,可以应用于各种任务。这与基于规则的方法形成了对比,后者针对不同的任务需要不同的规则集。混合方法,顾名思义,使用基于规则和机器学习方法的组合来进行预测。
近年来,机器学习模型受到了广泛的关注。大多数经典的基于机器学习的模型遵循流行的两步过程,在第一步中,从文档(或任何其他文本单元)中提取一些手工制作的特征,在第二步中,将这些特征提供给分类器进行预测。一些流行的手工制作功能包括单词包(BoW)及其扩展。常用的分类算法有朴素贝叶斯、支持向量机、隐马尔可夫模型、梯度增强树和随机森林。这两步方法有几个局限性。例如,依赖手工制作的特征需要繁琐的特征工程和分析才能获得良好的性能。另外,特征设计对领域知识的依赖性强,使得该方法难以推广到新的任务中。最后,这些模型不能充分利用大量的训练数据,因为特征(或特征模板)是预先定义的。
在2012年,一种基于深度学习的模型AlexNet (AlexNet,)在ImageNet竞赛中获得了巨大的优势。从那时起,深度学习模型被应用到计算机视觉和NLP的广泛任务中,提高了技术水平(vaswani2017attention; he2016deep, devlin2018bert ;yang2019xlnet, )。这些模型尝试以端到端方式学习特征表示并执行分类(或回归)。它们不仅能够发现数据中隐藏的模式,而且更容易从一个应用程序转移到另一个应用程序。毫不奇怪,这些模型正在成为近年来各种文本分类任务的主流框架。
这个综述,我们回顾了在过去六年中为不同的文本分类任务开发的150多个深度学习模型,包括情感分析、新闻分类、主题分类、问答(QA)和自然语言推理(NLI)。我们根据这些作品的神经网络架构将它们分为几个类别,例如基于递归神经网络(RNNs)、卷积神经网络(CNNs)、注意力、Transformers、胶囊网等的模型。本文的贡献总结如下:
- 我们提出了150多个用于文本分类的深度学习模型的详细概述。
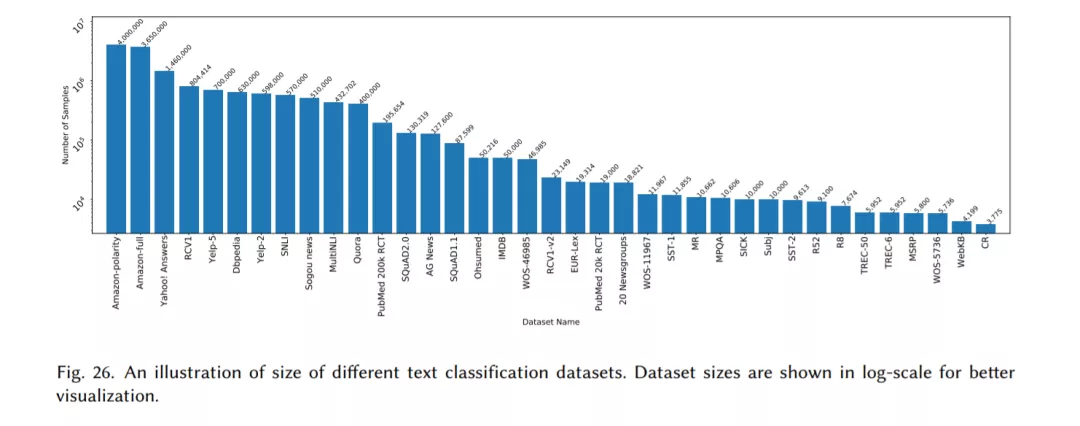
- 我们回顾了40多个流行的文本分类数据集。
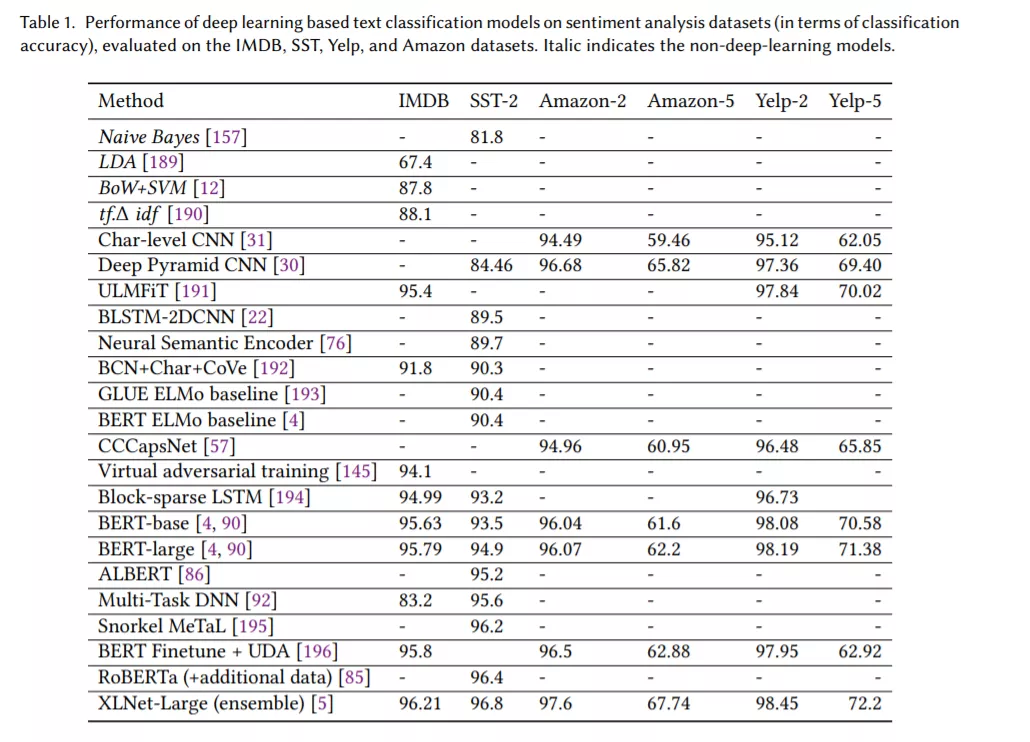
- 我们提供了一个定量分析的表现,选定的一套深度学习模型在16个流行的基准。
- 我们将讨论尚存的挑战和未来的方向。
- 深度学习模型文本分类
在本节中,我们将回顾150多个针对各种文本分类问题提出的深度学习框架。为了便于遵循,我们根据这些模型的主要架构贡献,将它们分为以下几类:
基于前馈网络的模型,该模型将文本视为一个单词包(第2.1节)。
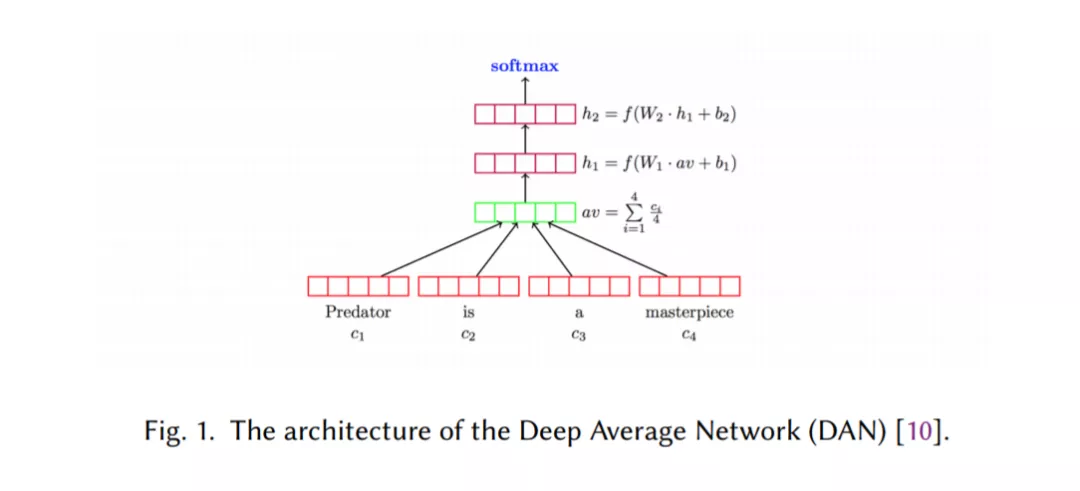
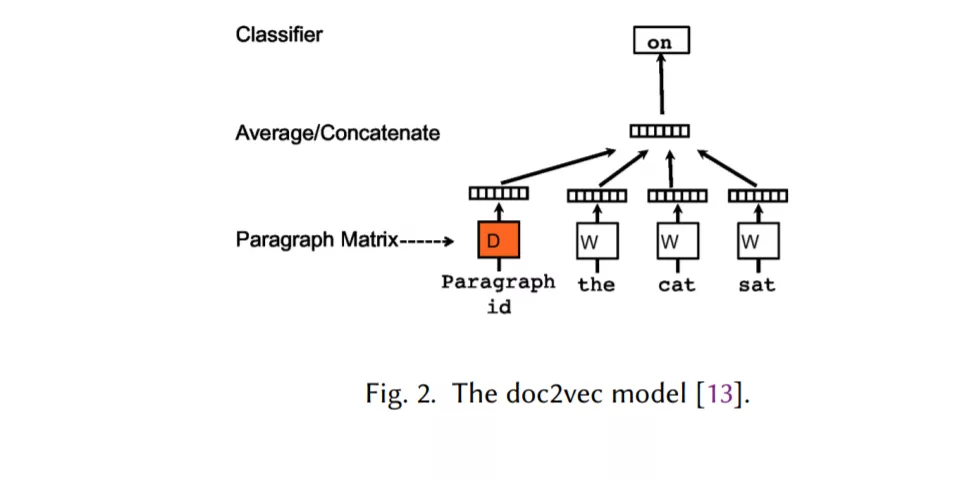
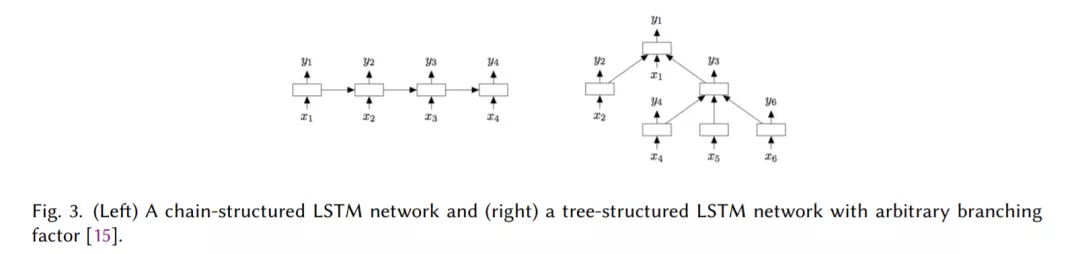
基于RNNs的模型,该模型将文本视为单词序列,旨在捕获单词依赖关系和文本结构(第2.2节)。
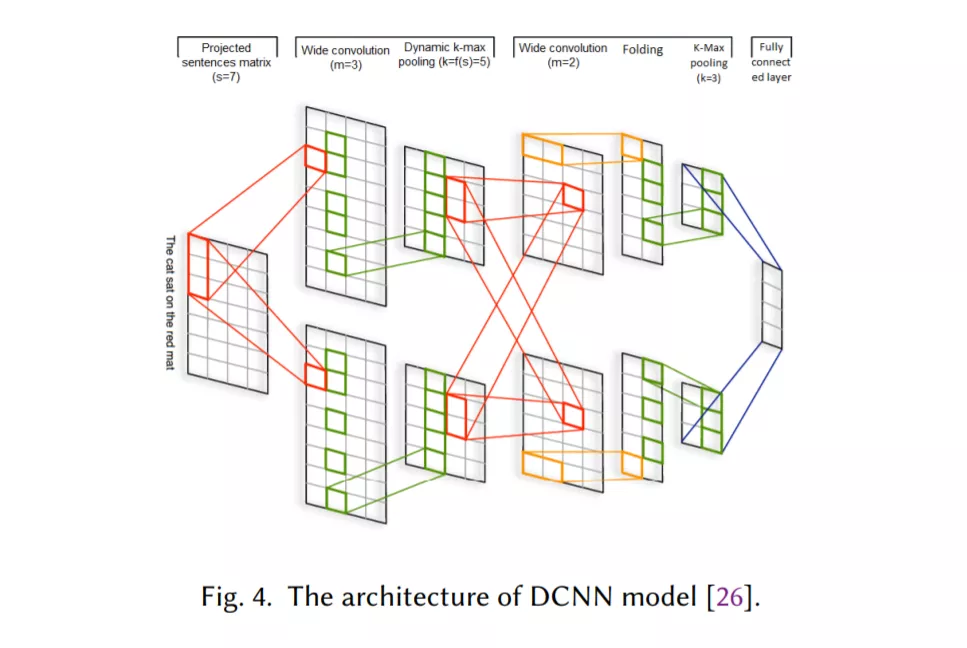
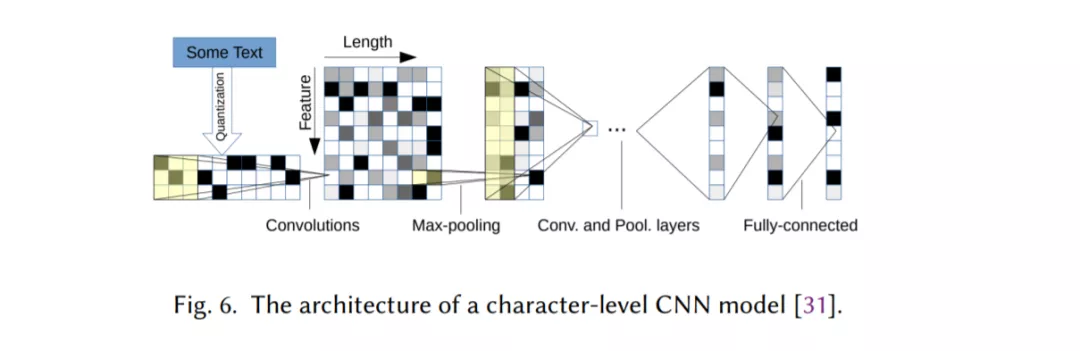
基于CNN的模型,它被训练来识别文本中的模式,例如关键短语,用于分类(第2.3节)。
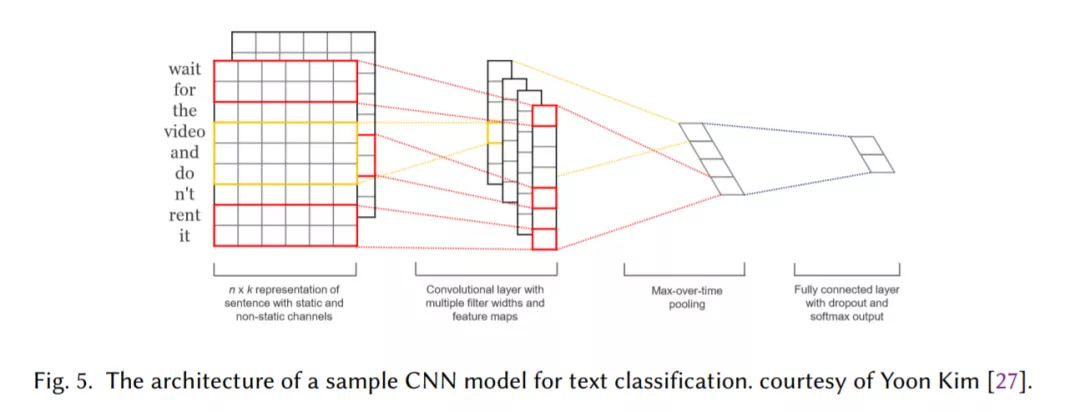
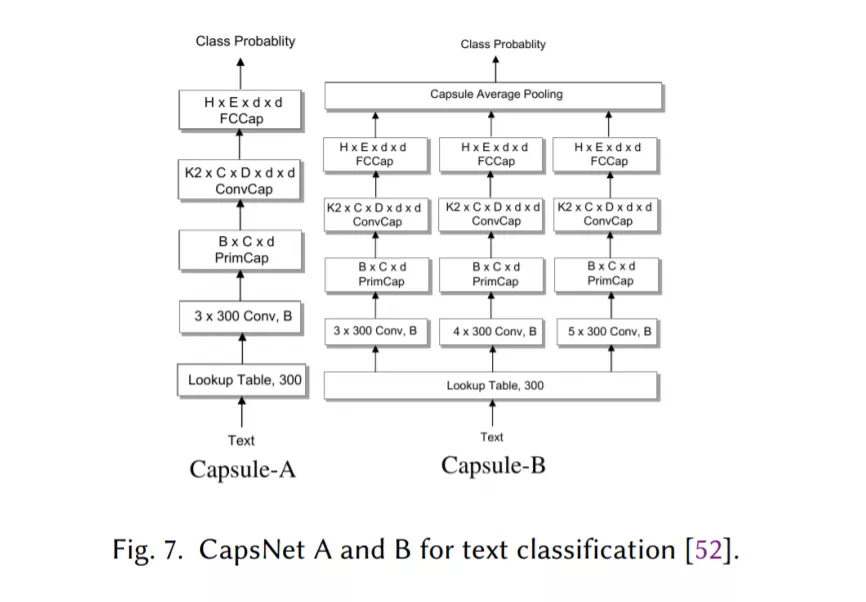
胶囊网络解决了CNNs的池化操作所带来的信息丢失问题,最近已被应用于文本分类(第2.4节)。
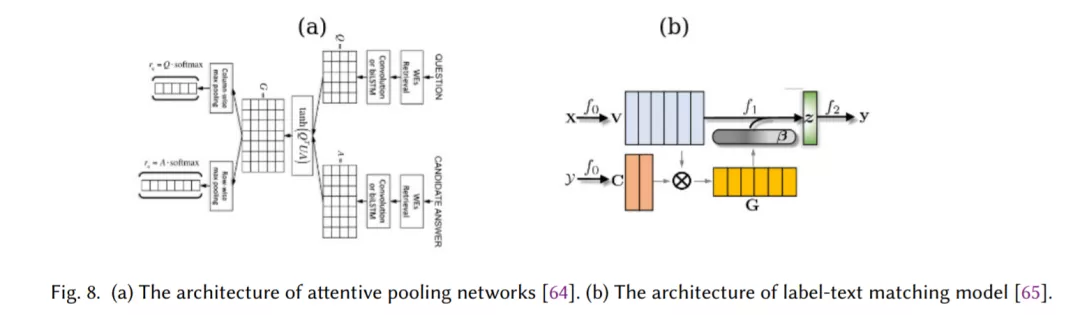
注意力机制是一种有效识别文本中相关词的机制,已成为开发深度学习模型的有用工具(第2.5节)。
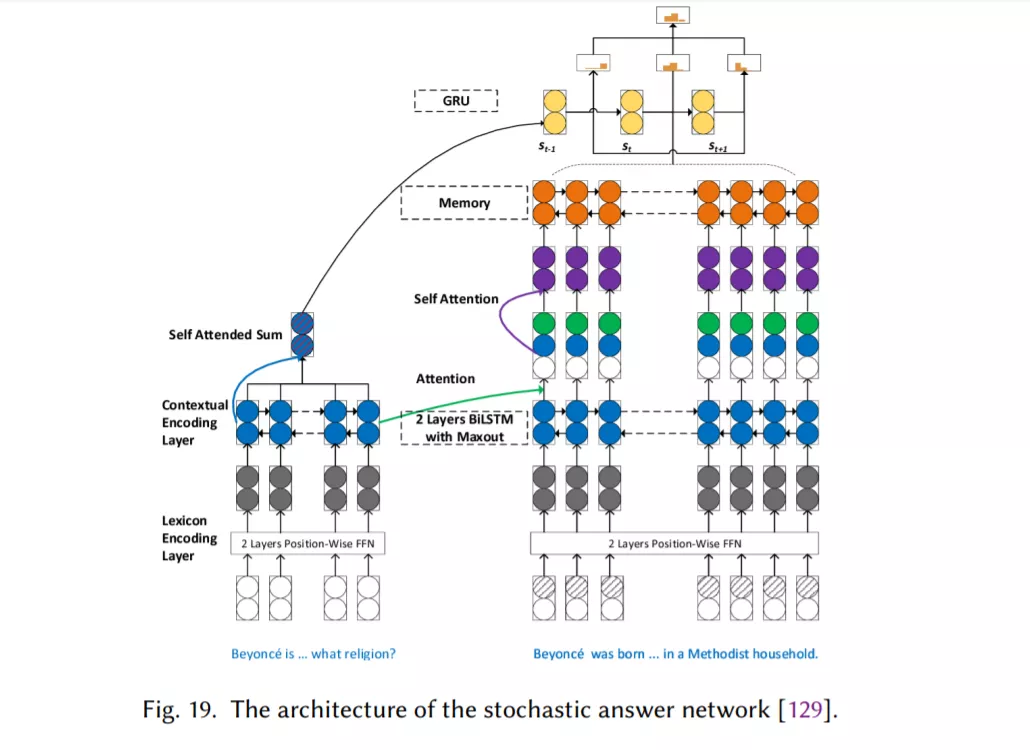
记忆增强网络,它将神经网络与某种形式的外部记忆相结合,模型可以读写外部记忆(章节2.6)。
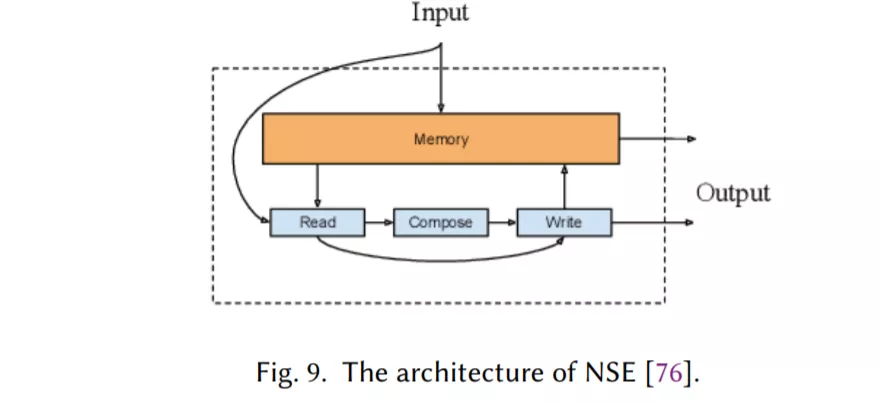
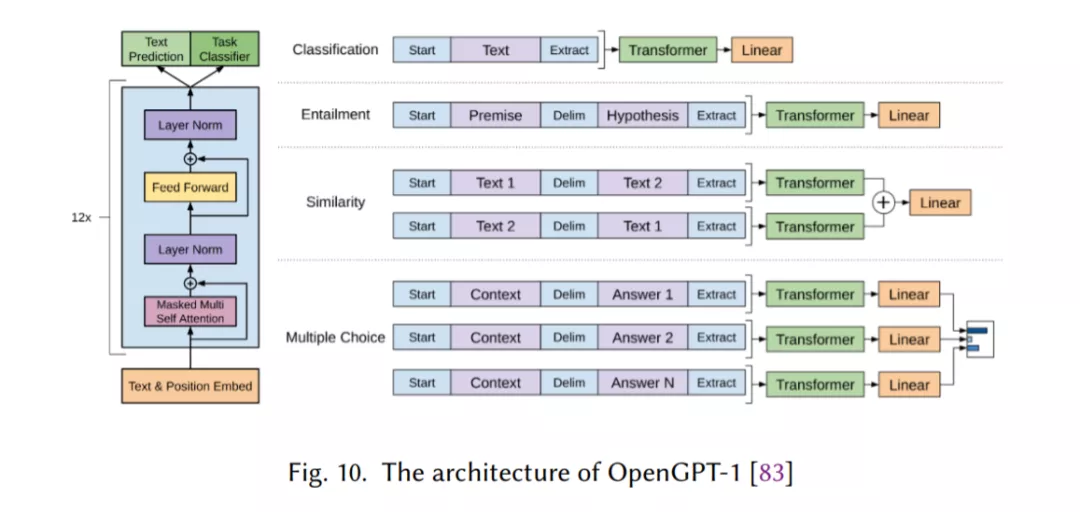
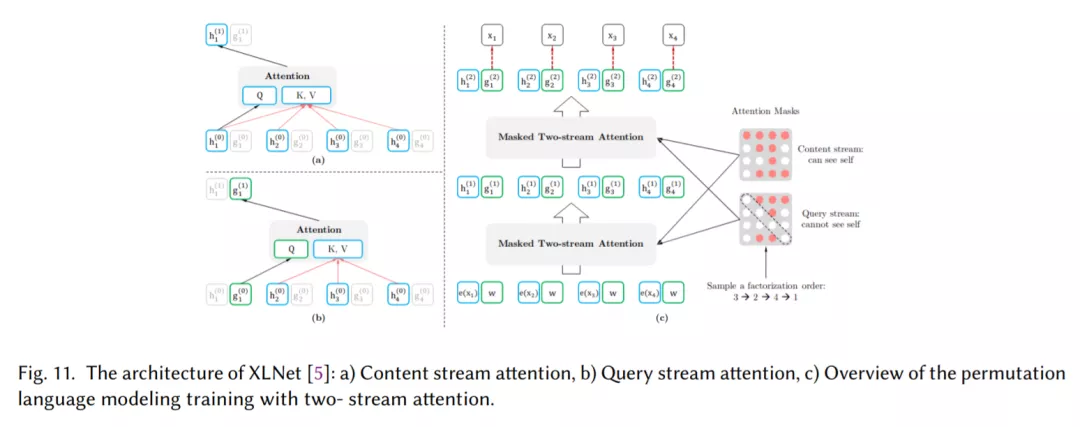
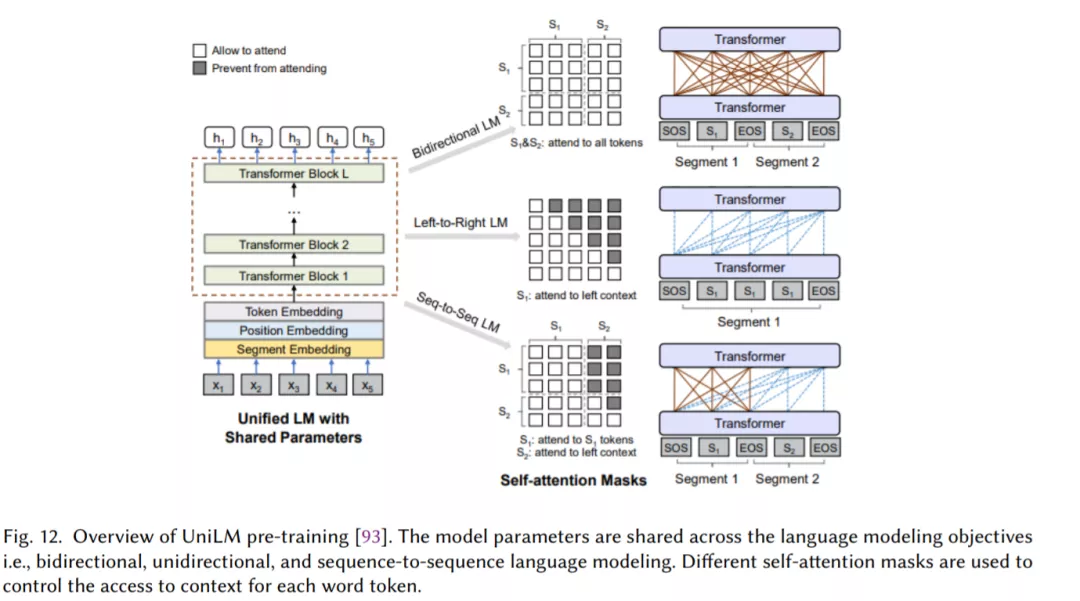
Transformer,它允许比RNNs更多的并行化,使得使用GPU集群有效地(预先)训练非常大的语言模型成为可能(章节2.7)。
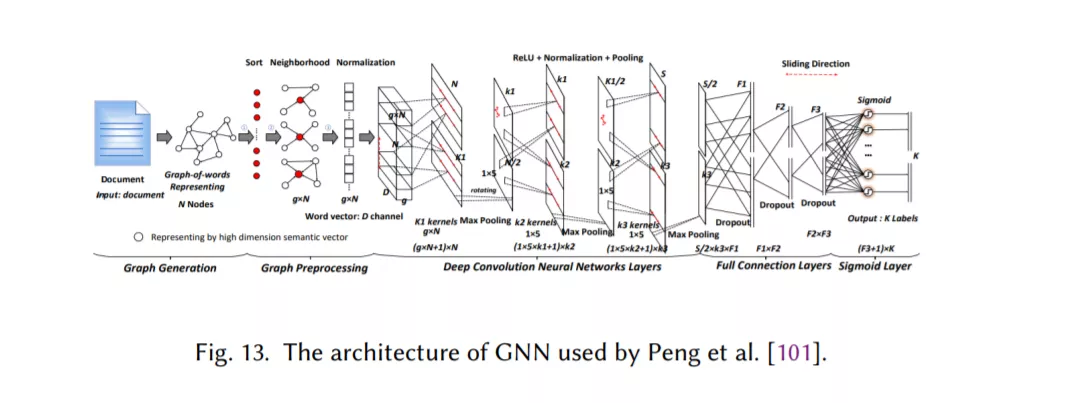
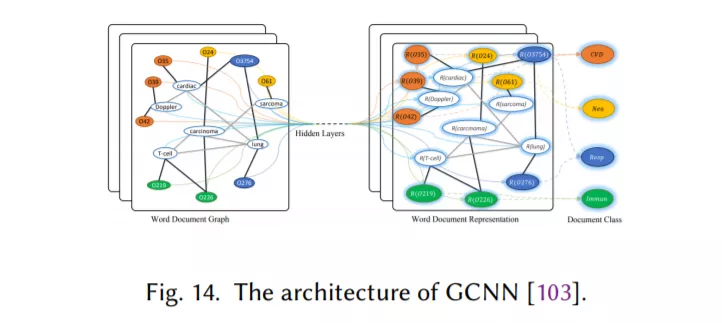
图神经网络,用于捕获自然语言的内部图结构,如语法和语义解析树(第2.8节)。
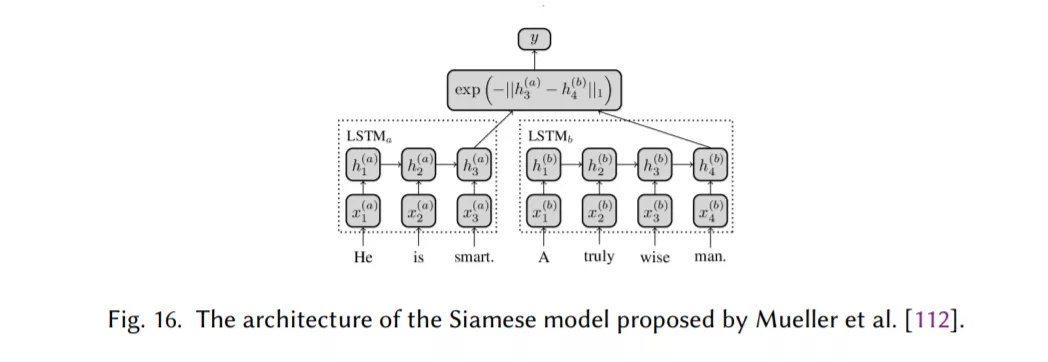
设计用于文本匹配的Siamese神经网络,文本分类的一个特例(第2.9节)。
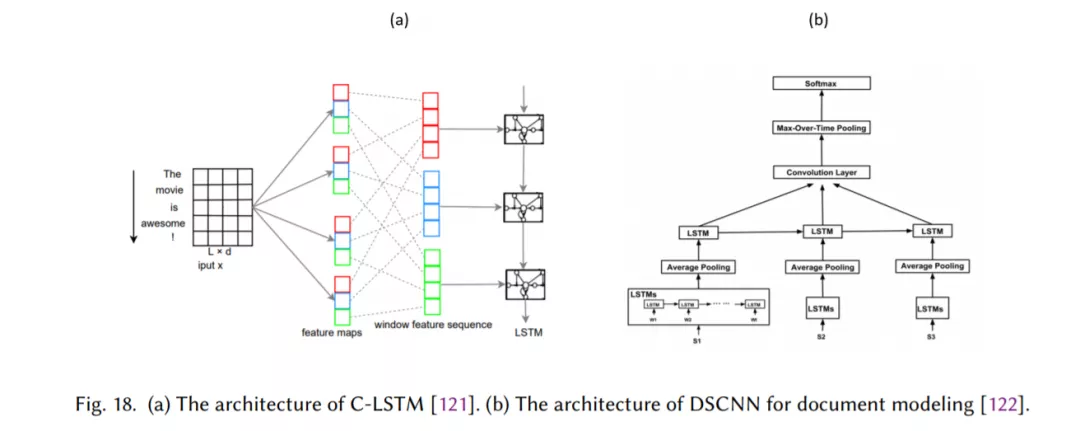
混合模型,将注意力、RNNs、CNNs等结合起来,以捕获句子和文档的局部和全局特征(第2.10节)。
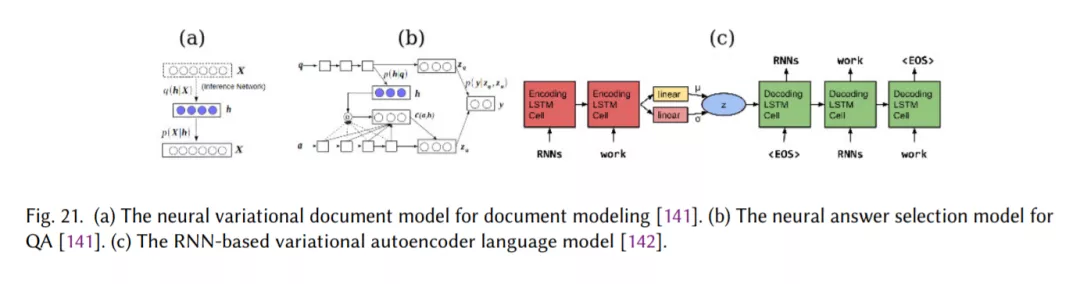
最后,在第2.11节中,我们回顾了监督学习之外的建模技术,包括使用自动编码器和对抗性训练的非监督学习和增强学习。
- 文本分类数据集
- 结果比较
- 未来方向
在基于深度学习模型的帮助下,文本分类在过去几年里取得了很大的进展。在过去的十年中,人们提出了一些新的思想(如神经嵌入、注意力机制、自注意、Transformer、BERT和XLNet),并取得了快速的进展。尽管取得了所有这些进展,但我们面前仍有几项挑战需要解决。本节将介绍其中的一些挑战,并讨论我们认为有助于推进该领域的研究方向。
- 用于更有挑战性任务的数据集
- 对常识进行建模
- 可解释的深度学习模型
- 记忆效率模型
- 小样本学习和零样本学习


