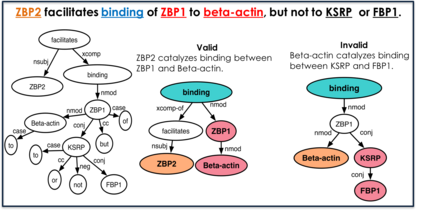
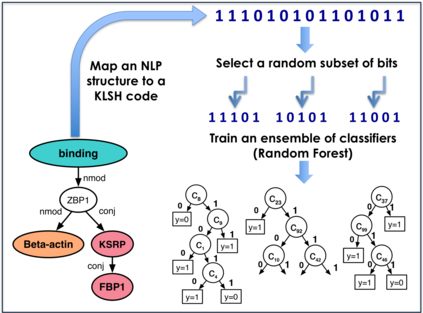
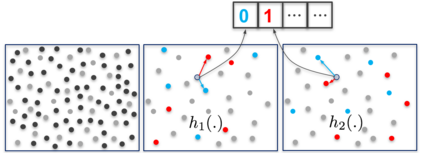
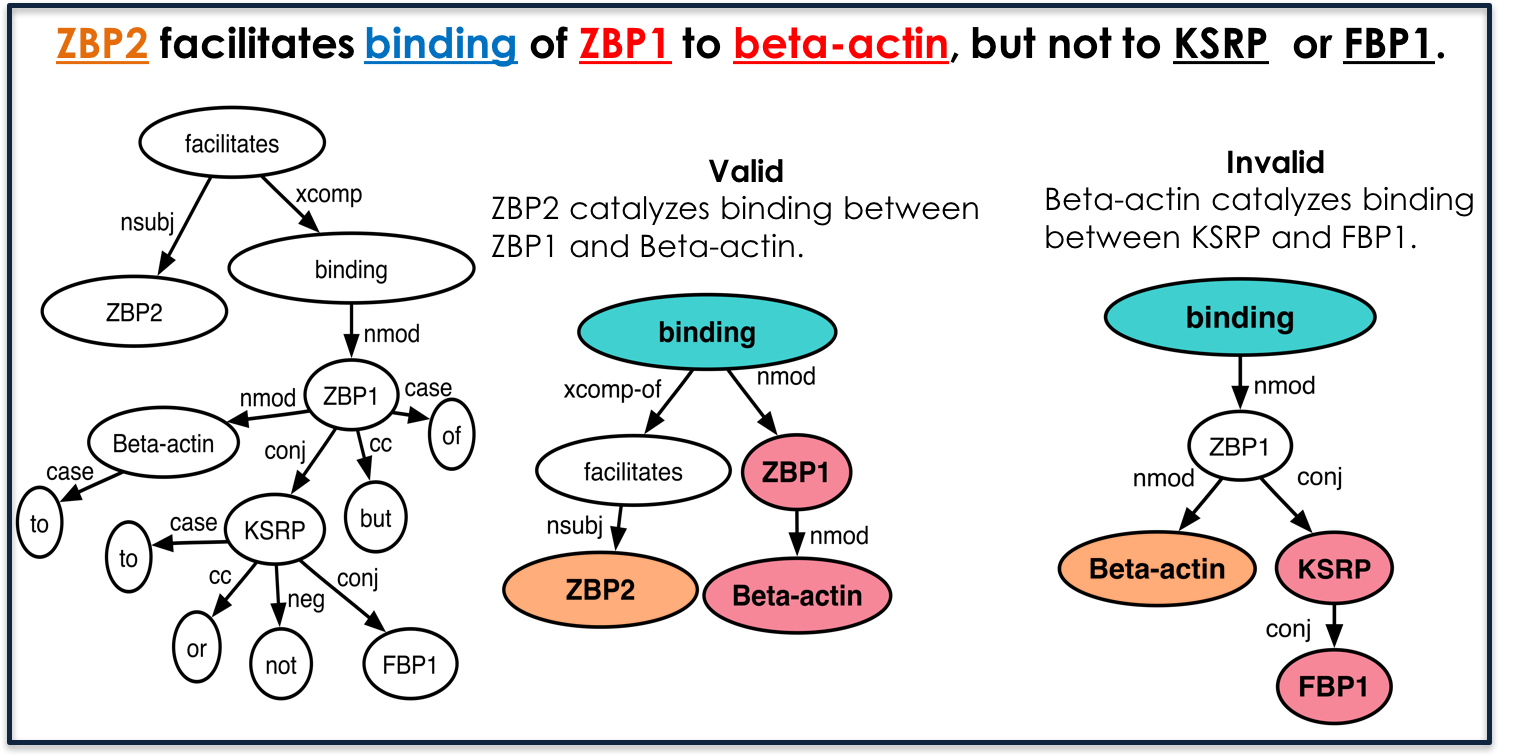
Kernel methods have produced state-of-the-art results for a number of NLP tasks such as relation extraction, but suffer from poor scalability due to the high cost of computing kernel similarities between discrete natural language structures. A recently proposed technique, kernelized locality-sensitive hashing (KLSH), can significantly reduce the computational cost, but is only applicable to classifiers operating on kNN graphs. Here we propose to use random subspaces of KLSH codes for efficiently constructing an explicit representation of NLP structures suitable for general classification methods. Further, we propose an approach for optimizing the KLSH model for classification problems by maximizing a variational lower bound on mutual information between the KLSH codes (feature vectors) and the class labels. We evaluate the proposed approach on biomedical relation extraction datasets, and observe significant and robust improvements in accuracy w.r.t. state-of-the-art classifiers, along with drastic (orders-of-magnitude) speedup compared to conventional kernel methods.
翻译:内核方法已经为一些NLP任务(如关系提取)产生了最先进的结果,但由于离散自然语言结构之间计算内核相似性的成本高昂,其可扩展性较差。最近提出的一种技术,即内核对地敏感的散列(KLSH),可以显著降低计算成本,但只适用于以 kNNT 图形操作的分类人员。我们在这里提议使用KLSH 编码随机的子空间,以高效地构建适合一般分类方法的NLP结构的明确代表性。此外,我们提议了一种优化 KLSH 分类问题模型的方法,即最大限度地降低KLSH 代码(特性矢量)和类标签之间对相互信息的变式限制。我们评估了拟议的关于生物医学关系提取数据集的方法,并观察到在准确性 w.r.t. 上的重大和有力的改进,以及相对于常规内核方法而言的快速(放大)速度。