Facebook@ICLR2021 比GNN快100倍的标签传播

图神经网络(GNN)是学习图的主要技术,并且已经得到非常广泛的应用。但是GNN训练往往需要大量的参数且训练时间很长。这里我们可以通过组合忽略图结构的浅层模型和利用标签结构相关性的两个简单后处理步骤,来获得GNN性能的提升。例如,在OGB-Products数据集上,相对性能最好的GNN模型,我们将参数减少137倍,训练时间减少超过100倍,还能获得更好的性能。
(1)“误差相关性”,它分散训练数据中的残留错误以纠正测试数据中的错误
(2)“预测相关性”,它使测试数据上的预测变平滑。我们称此过程为“纠正和平滑”(C&S)
后处理步骤是通过从早期基于图的半监督学习方法对标准标签传播技术进行简单修改而实现的。我们的方法在各种各样的网络上都超过或接近了最新的GNN的性能基准,并且参数和运行时间大大减小。我们将标签信息直接整合到学习算法中,从而获得简单而可观的性能提升。我们还将该技术融合到大型GNN模型中,从而获得性能的提升。
01
前言
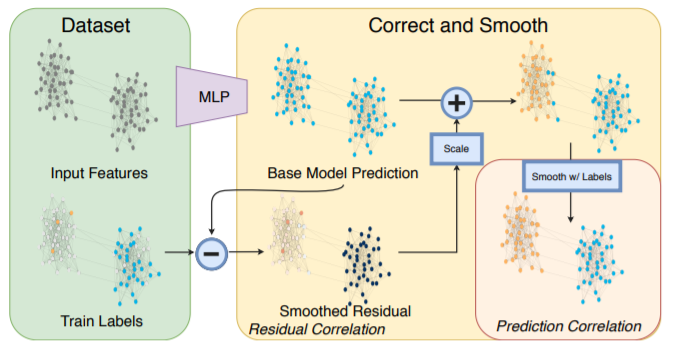
02
纠正和平滑模型
03
实验
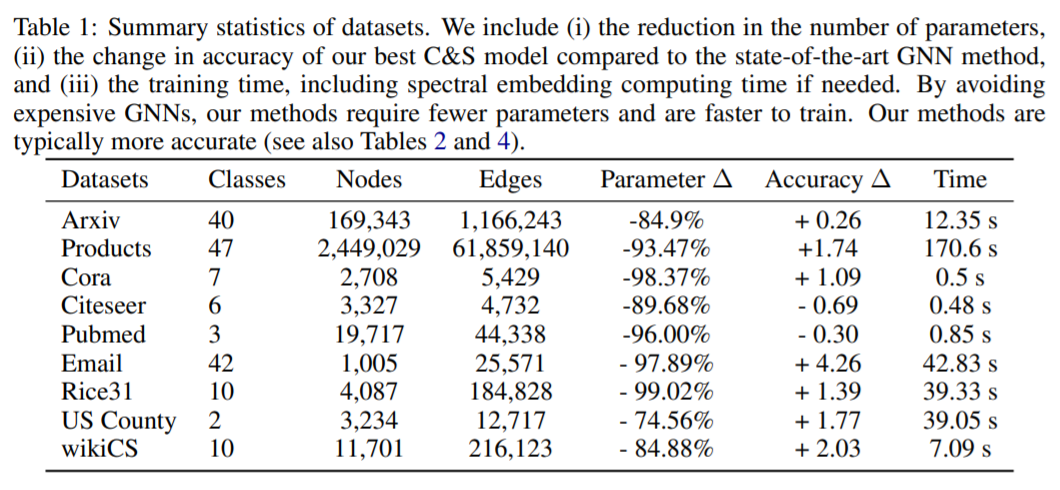
表1
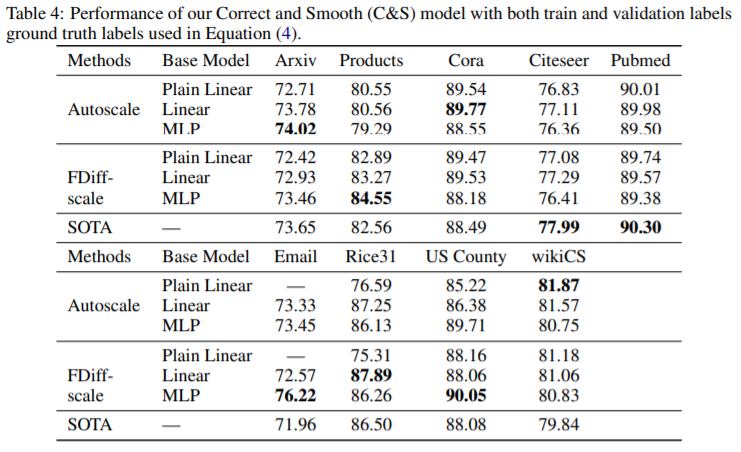
表4
1.大而难以训练的GNN在节点分类中不是必要的。
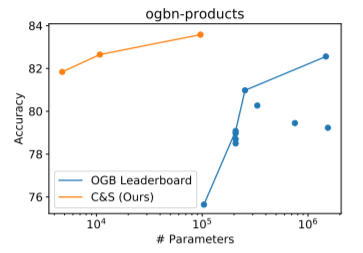
图2
04
总结



登录查看更多
相关内容
Arxiv
9+阅读 · 2019年10月12日


相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2019年10月12日