3倍加速CPU上的BERT模型部署
BERT模型 [1] 是由Google在2018年提出,由于其在各类NLP的任务上出色性能,一经推出便获得了很多的关注。但是BERT模型的缺点是计算量过于庞大,对于推理部署有着很大的挑战。最近我们看到越来越多的产品开始从一些轻量级的模型转向使用BERT,所以BERT模型的部署性能变得越来越重要。
最近,在学术界和工业界,大家都在加紧研发深度学习编译器用于优化模型部署的性能,比如TVM [2], MLIR [3], 和Glow [4]。并且一些近期的成果[2,5] 也证明了深度学习编译器可以有效地降低模型推理的时间。在AWS,我们在积极地对开源项目Apache TVM做开发和贡献,并且将TVM用于优化各种平台下的模型部署,其中也包括了BERT模型。同时,我们提供了一个非常简单易用的模型优化服务——Amazon SageMaker Neo。
在这篇文章中,我们想展示一下我们最新的BERT模型在CPU上部署优化的成果,并且手把手教你如何复现这一优化结果。我们可以在Amazon EC2 c5.9xlarge的服务器上将BERT模型的推理时间降低高达2.9倍,以及取得至多2.3倍更高的吞吐量。我们得到的fp32的BERT模型推理性能是目前已知在CPU上最好的。TVM之所以可以取得高性能主要源于三个点:
TVM将小算子融合在一起,可以大大提高缓存的使用效率
TVM既可以自己代码生成高性能的算子,又可以利用高性能的第三方库
TVM能够对计算图进行优化,同时也可以将一些计算速度较慢的数学运算替换成更快的近似计算
更重要的是,这一优化效果只需要十几行代码便可完成,完整复现代码文末可见,欢迎试用。另外,我们所有的优化代码也已全部开源。
BERT模型优化效果
我们使用了BERT base模型和DistilBERT模型来展示我们的优化性能。其中BERT base模型有12层transformer层,而DistilBERT只有6层,因此DistilBERT在推理时运行得更快。我们使用了GluonNLP (0.9.1)的模型库中提供的这两个模型,然后用TVM对其进行编译优化。所有的模型都使用fp32的精度。
下表比较了MXNet(mkl 1.6.0)和TVM优化过后的两个模型在c5.9xlarge上的运行时间。我们可以看到TVM可以降低2.1倍到2.9倍的运行时间。值得注意的是,DistilBERT模型在序列长度128的时候,在CPU上只需要9.5ms的推理时间。相比之下,之前ONNX runtime在类似的CPU上将BERT模型减少到只有3层才取得了9ms的推理时间。相对于TensorFlow和PyTorch实现的BERT模型,我们在CPU上也有相应的性能加速。
| model | batch | seq length | MXNet lat. (ms) | TVM lat. (ms) | speedup |
| BERT | 1 | 64 | 26.1 | 12.6 | 2.1 |
| BERT | 1 | 128 | 45.8 | 19.2 | 2.4 |
| BERT | 1 | 256 | 99.4 | 35.3 | 2.8 |
| DistilBERT | 1 | 64 | 13.4 | 6.2 | 2.2 |
| DistilBERT | 1 | 128 | 23.2 | 9.5 | 2.5 |
| DistilBERT | 1 | 256 | 50.1 | 17.5 | 2.9 |
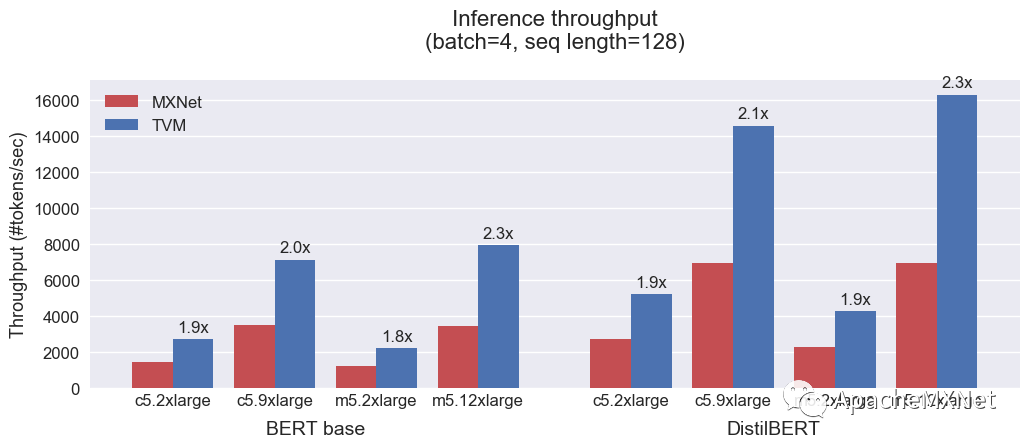
同时我们也在更多的EC2云服务器上(c5.2xlarge, c5.9xlarge, m5.2xlarge, m5.12xlarge)评测了BERT模型在batch 4和序列长度128下的吞吐量。下图显示TVM能够在各类型的服务器上将BERT和DistilBERT模型取得平均2倍更高的吞吐量。
如何复现这一结果?
接下来我们将一步步地教你如何来复现上面的优化结果。
首先,我们需要在Amazon EC2上使用AWS Deep Learning AMI, Ubuntu 18.04来创建一个CPU服务器。在我们ssh到这个服务器后,我们先要将conda环境切换成mxnet_p36,然后安装GluonNLP的python模块。
source activate mxnet_p36
pip install gluonnlp==0.9.1
然后,我们需要安装TVM。这里提供的TVM python模块是针对Deep Learning AMI编译的,有可能无法兼容其它的系统和运行环境。我们会在附录教大家如何手动编译及安装TVM。
pip install https://tvm-build-public.s3-us-west-2.amazonaws.com/dlami-cpu-mkl/tvm-0.7.dev1-cp36-cp36m-linux_x86_64.whl
pip install https://tvm-build-public.s3-us-west-2.amazonaws.com/dlami-cpu-mkl/topi-0.7.dev1-py3-none-any.whl
接下来,我们将使用TVM对BERT模型进行优化。在这里我们省去了如何用GluonNLP来训练和精调BERT模型,你可以参考GluonNLP网站上的教程。在我们载入BERT模型后,我们首先将BERT模型从MXNet转换到TVM Relay语言。Relay语言是TVM中用于表示模型的计算图的一种中间表达。
# Load model from GluonNLP
...
mx_model = nlp.model.BERTClassifier(...)
# Convert MXNet model to TVM
shape_dict = {
'data0': (batch, seq_length),
'data1': (batch, seq_length),
'data2': (batch,)
}
mod, params = relay.frontend.from_mxnet(mx_model, shape_dict)
在编译模型时,我们需要定义编译目标和优化级别。EC2上的c5和m5服务器的CPU都支持Intel的AVX-512指令,这类指令通过向量化来加速浮点运算。因此,我们在编译目标中加入了CPU架构(-mcpu=skylake-avx512)来使用这类指令。此外,我们也使用了Intel MKL的库来加速矩阵乘法等算子。第三,我们在编译时打开了一个优化选项叫“FastMath”。这个优化告诉TVM来用近似计算去替代一些较慢的数学运算,如erf。经过我们的验证,使用这类近似计算并不会影响最终的准确性。
target = "llvm -mcpu=skylake-avx512 -libs=cblas"
with relay.build_config(opt_level=3, required_pass=["FastMath"]):
graph, lib, cparams = relay.build(mod, target, params=params)
最后我们创建一个轻量级的TVM运行时来执行编译优化后的BERT模型,并检测它的输出是否和MXNet一致。
ctx = tvm.cpu()
rt = runtime.create(graph, lib, ctx)
rt.set_input(**cparams)
rt.set_input(data0=inputs, data1=token_types, data2=valid_length)
rt.run()
out = rt.get_output(0)
print(out.ansumpy())
# verify the correctnesstvm.testing.assert_allclose(out.asnumpy(),mx_out.asnumpy(),rtol=1e-3,atol=1e-3)
完整的复现代码可见于
https://gist.github.com/icemelon9/860d3d2c9566d6f69fa8112840dd95c1.
结论
综上,我们看到TVM可以显著地加速BERT模型在CPU上的推理性能。运行时间可以被降低至多2.9倍,而吞吐量可以被提高至2.3倍。值得注意的是,现在的这个BERT解决方案只适用于固定长度,我们还在继续开发TVM来支持动态的序列长度。
附录:从源代码编译TVM
TVM官方网站提供了一份详细的编译TVM指南。这里我们简单描述一下我们所使用的编译配置,以获得最佳的BERT推理性能。
首先,除了安装编译TVM所必须的依赖库以外,你还需要安装LLVM(>=6.0)和Intel MKL库(安装教程可见这个链接)。接下来,我们就可以编译TVM的C++库。
git clone --recursive https://github.com/apache/incubator-tvm.git tvm
cd tvm && mkdir build && cd build
cmake -DUSE_LLVM=/path/to/llvm-config -DUSE_BLAS=mkl -DUSE_OPENMP=intel ..
make -j4
然后,我们便可以安装TVM和Topi的python模块。
cd python; python setup.py install --user; cd ..
cd topi/python; python setup.py install --user; cd ../..
引用
[1] Jacob Devlin, et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. arXiv pre-print arXiv:1810.04805 (2018).
[2] Tianqi Chen, et al. “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.” 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), 2018.
[3] Chris Lattner, et al. “MLIR: A Compiler Infrastructure for the End of Moore’s Law”. arXiv preprint arXiv:2002.11054, 2020.
[4] Nadav Rotem, et al. “Glow: Graph Lowering Compiler Techniques for Neural Networks”. CoRR, abs/1805.00907, 2018.
[5] Liu, Yizhi, et al. "Optimizing CNN Model Inference on CPUs."2019 USENIX Annual Technical Conference (USENIX ATC 19). 2019.
[6] Sanh, Victor, et al. "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter." arXiv preprint arXiv:1910.01108 (2019).