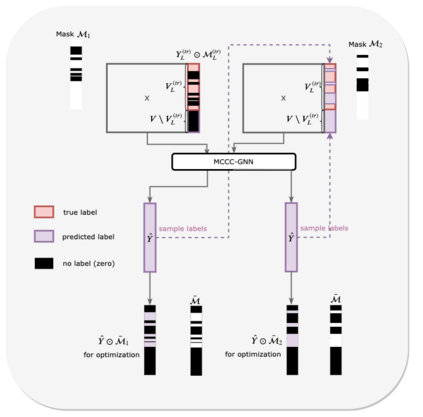
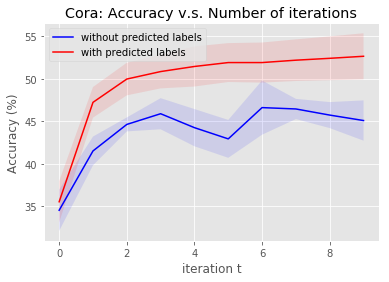
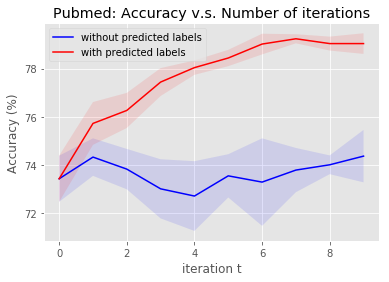
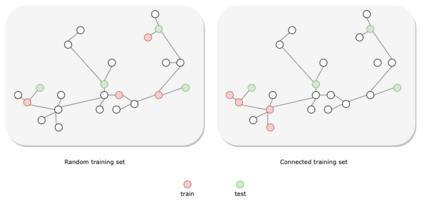
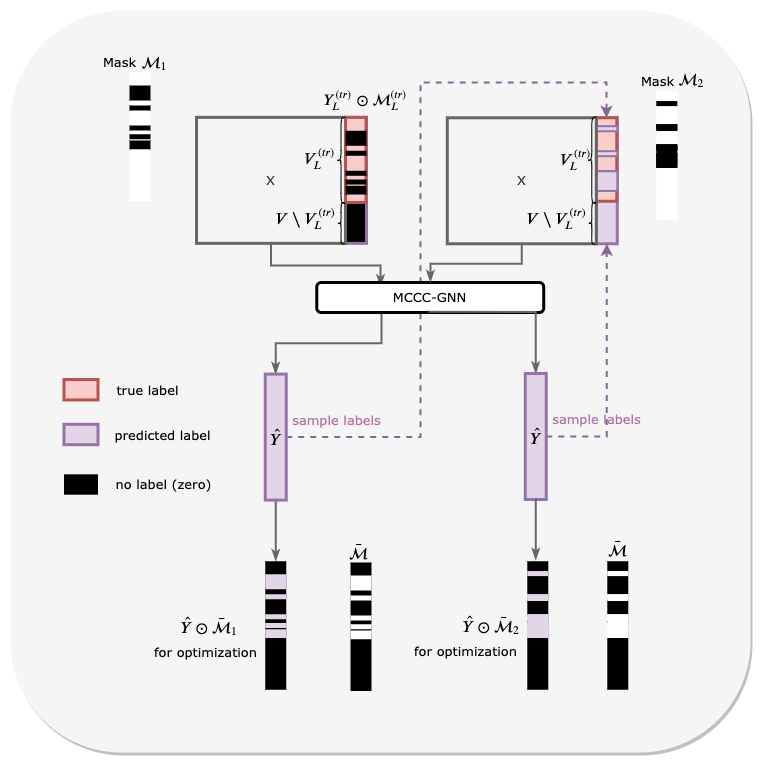
Graph Neural Networks (GNNs) have recently been used for node and graph classification tasks with great success, but GNNs model dependencies among the attributes of nearby neighboring nodes rather than dependencies among observed node labels. In this work, we consider the task of inductive node classification using GNNs in supervised and semi-supervised settings, with the goal of incorporating label dependencies. Because current GNNs are not universal (i.e., most-expressive) graph representations, we propose a general collective learning approach to increase the representation power of any existing GNN. Our framework combines ideas from collective classification with self-supervised learning, and uses a Monte Carlo approach to sampling embeddings for inductive learning across graphs. We evaluate performance on five real-world network datasets and demonstrate consistent, significant improvement in node classification accuracy, for a variety of state-of-the-art GNNs.
翻译:最近,在节点和图表分类任务中,GNNS(GNNs)最近被成功使用,但GNNs模型在附近相邻节点的属性之间而不是观察到的节点标签之间的依赖性。在这项工作中,我们考虑将GNNs用于监管和半监管环境中的感应节点分类任务,目的是纳入标签依赖性。由于目前的GNNs不是普遍性的(即,最明显的)图形表达,我们建议采用一般的集体学习方法,以提高任何现有的GNN的表示力。我们的框架将集体分类的观点与自我监督的学习结合起来,并使用蒙特卡洛方法取样嵌入的嵌入,用于跨图层的感应学习。我们评估五个真实世界网络数据集的性能,并表明,对于各种最先进的GNNNs来说,节点分类准确性得到了一致、显著的提高。