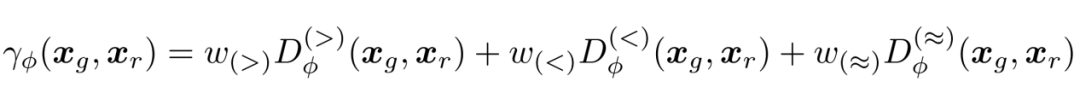本文为大家介绍的是微软亚洲研究院入选 ICLR 2020的 4 篇精选论文,研究主题分别为BERT 在机器翻译中的应用,有理论保障的对抗样本防御模型 MACER,一种新的基于自我博弈的文本生成对抗网络(GAN)训练算法,以及可广泛应用于视觉-语言任务的预训练通用特征表示 VL-BERT。
论文链接:https://arxiv.org/pdf/2002.06823.pdf
BERT 在自然语言理解任务如文本分类、阅读理解上取得了巨大的成功,然而在机器翻译等文本生成任务上的应用仍缺乏足够的探索。
本篇论文研究了如何有效地将 BERT 应用到神经机器翻译(NMT)中。
在文本分类任务中, 通常有两种方法利用预训练模型;一种是利用 BERT 初始化下游任务的模型权重;另一种是让预训练模型给下游任务模型提供 contextual embedding。在初步尝试中,我们发现:(1)用 BERT 初始化 NMT 模型不能给机器翻译带来显著提升;(2)利用 BERT 提供 contextual embedding,在机器翻译上这个任务上更加有效。结果见表1。因此,本文将探索重点放在第二类方法上。
表1:利用预训练的不同方式在 IWSTL14 英德翻译的结果
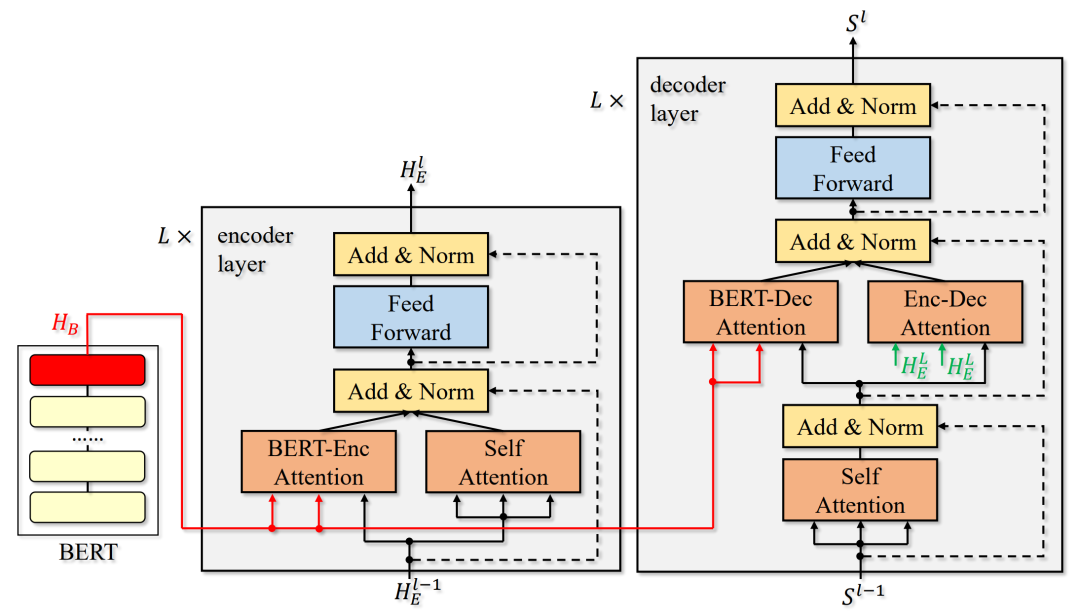
先将源语言句子输入 BERT 模型进行编码,得到输入序列的 BERT 模型特征。Transformer 的编码器和译码器的每一层都引入一个额外的注意力机制,让编码器和译码器去主动地去选取 BERT 模型特征中有用的信息。这种处理方式有效地解决了BERT 模型和机器翻译模型的分词方式不同产生的矛盾,也让 BERT 提取的特征更加有效、完全地融合到机器翻译这个任务中去。另外,我们还提出了 drop-net 的 trick,随机丢弃 Transformer 中原有的注意力分支或引入的额外注意力分支,能够有效地提高模型的泛化能力,提升机器翻译的效果。模型框架如图1所示。
我们将该方法作用到有监督翻译(句子级别翻译和文档翻译)、半监督机器翻译、无监督机器翻译中,都得到了显著的结果提升,在多个任务上都取得了 SOTA 的结果,说明了该方法的有效性。我们的算法在 WMT14 英德翻译和英法翻译的结果见表2。
表2:我们的算法在 WMT14 英德和英法翻译任务的结果。
论文链接:https://openreview.net/pdf?id=rJx1Na4Fwr
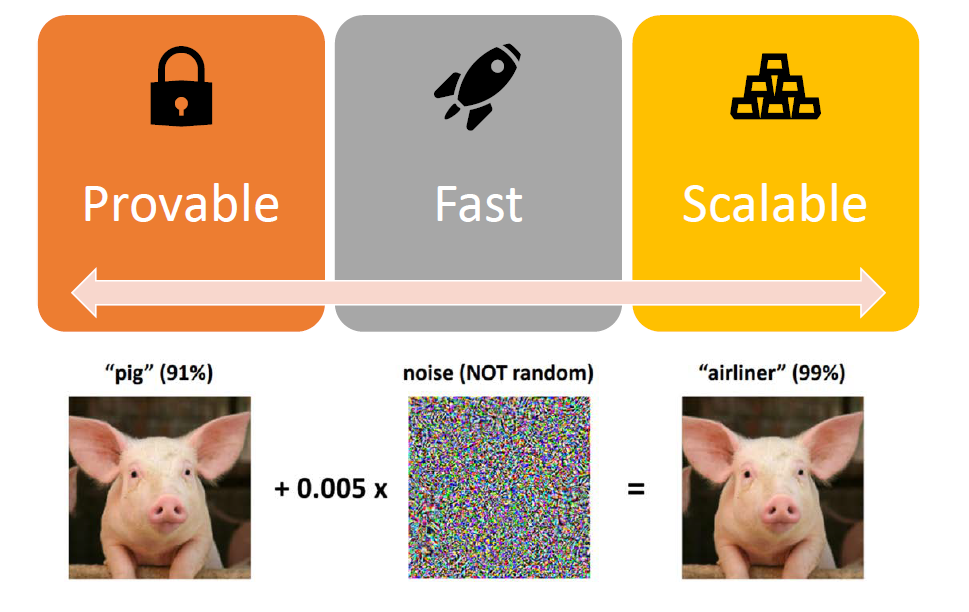
深度神经网络在很多领域都取得了成功,但它有一个致命的弱点:无法承受对抗样本的攻击。例如给定一张狗的图片,一个神经网络可以准确地将其分类为狗。但攻击者可以给这张图片加一个人类难以察觉的特殊噪音,使得神经网络把它分类成猫、树、车及任何其它物体。这样加过噪音的图片被称为对抗样本。这个弱点使得神经网络难以被应用到注重安全的领域,例如自动驾驶中。
如何防御对抗样本一直是研究人员关心的话题。目前最主流的防御方法是对抗训练,即在训练的每一次迭代中,先在线地生成对抗样本,再在这些对抗样本上训练神经网络。这样训练出来的网络可以一定程度地防御对抗样本的攻击。然而,对抗训练有两个缺点:一,这种防御是没有理论保证的,即我们不知道攻击者能否设计更聪明的攻击方法绕开这种防御;二,因为生成对抗样本很慢,所以对抗训练非常慢。
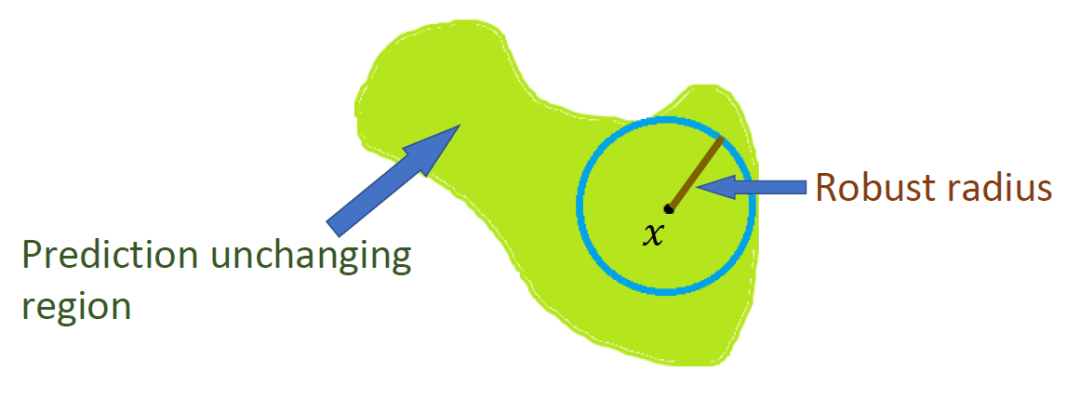
本文设计了一种算法去训练有理论保证的防御模型,能保证任何攻击都无法绕开这种防御。我们首先引入防御半径的概念。一个图片的可防御半径指的是半径内任何一个图片的预测都不发生变化。对于光滑模型,我们可以用高效的计算方法得到该半径的一个下界。而我们提出的算法 MACER(MAximize the Certified Radius)正是通过最大化该半径来学习有理论保证的防御模型。
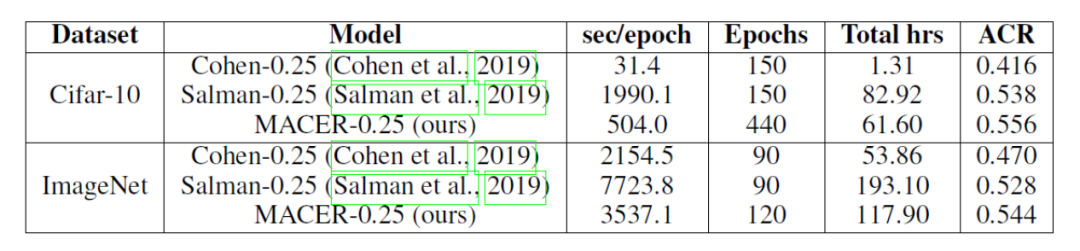
MACER 算法的思路非常简单,设计却相当具有挑战性。第一个挑战是设计优化目标函数。我们通过数学推导将目标函数定为模型准确度和模型防御成功率的结合,并证明它是防御效果的上界;第二,我们提出了梯度软随机光滑化,这个变体可以提供可导的损失函数;第三,我们通过巧妙地设计损失函数,避免梯度爆炸问题。实验表明 MACER 可以取得比目前主流可验证防御算法更大的平均验证半径,且训练速度有数倍的提升。
MACER 算法主要带给我们两个启发:一是 MACER 完全与攻击无关,这不仅使得 MACER 运行相当快,而且可以让模型有效地防御任何攻击;二是 MACER 是一个有理论保证的防御算法,能够让实际应用有可靠的保障。
3、基于 Self-Play 的文本生成对抗网络(GAN)模型
论文链接:https://openreview.net/pdf?id=B1l8L6EtDS
本文介绍了一种新的基于自我博弈的文本生成对抗网络(GAN)训练算法。目前大多数文本生成任务,如机器翻译、文本摘要、对话系统等,都采用序列到序列模型(seq2seq),并通过最大似然估计(MLE)进行模型训练。这种训练方式存在 exposure bias 的问题,使得模型在训练和推断时单词的分布不一致,因此会影响生成质量。此前的工作如 SeqGAN 等,尝试通过 GAN 来训练文本生成模型。
GAN 在文本生成中的应用主要受限于两个问题,一是奖励稀疏(reward sparsity),即训练中判别器往往远强于生成器,因此生成器在训练过程中得到的奖励信号通常很低;二是模式崩溃(mode collapse),即生成的文本通常较为单一。本文中我们借鉴深度强化学习中常用的自我博弈(self-play)机制,提出了自对抗学习(SAL)范式来改进文本 GAN 的训练。
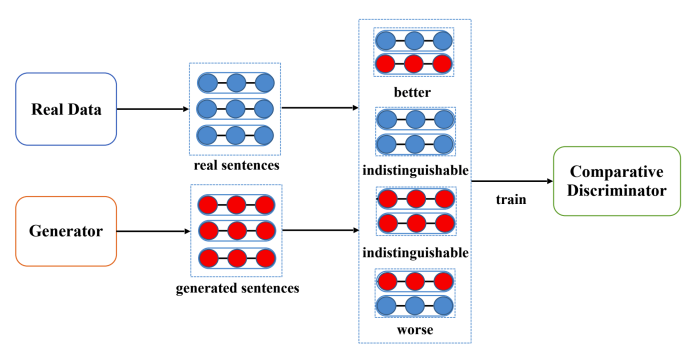
与传统的 GAN 中判别器对于给定样本输出其真/假标签不同,自对抗学习中采用一种新的基于比较的判别器,其输入是两个样本 A 和 B,输出标签包含三类,分别对应样本 A 的质量比 B 优(>),差(<),和无法区分(~=)。基于比较的判别器的训练过程如图3所示。
和 SeqGAN、LeakGAN 等文本 GAN 模型一样,SAL 通过 REINFORCE 算法对生成器进行训练。在训练期间,SAL 通过比较判别器,将生成器当前生成的样本与其自身先前生成的样本进行比较。当发现其当前生成的样本比其先前的样本质量更高时,赋予生成器正奖励,反之则奖励为负,两者质量无法区分时奖励为0。奖励的具体计算公式如图4公式所示。
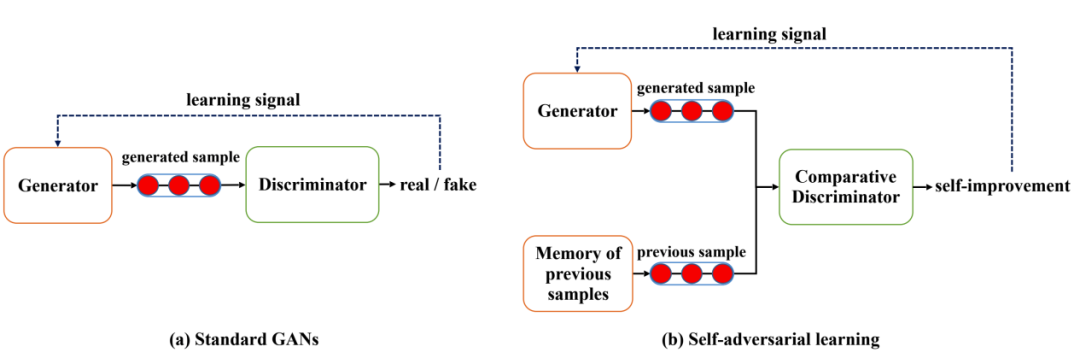
在文本生成 GAN 的早期训练阶段,当生成的样本质量远远低于真实样本的质量时,SAL 的自我对抗机制使得生成器不需要成功欺骗判别器、使其误将生成样本判断为真实样本才能获得奖励。相反的,SAL 会在生成器成功生成比之前更好的样本时就赋予其奖励信号,这种自我对抗的奖励机制使生成器更易于接收非稀疏奖励,从而有效缓解了奖励稀疏性问题。而在训练后期,SAL 可以防止开始高频出现的模式继续获得较高的奖励,因为包含这些经常出现的模式的句子经常会和相似的句子进行比较,因此在自我对抗中取胜也将变得越来越困难,从而防止生成器塌缩到有限的模式中。自对抗学习的示意和算法流程分别如图5和表4所示:
图5 : 自对抗学习(SAL)与传统 GAN 的对比
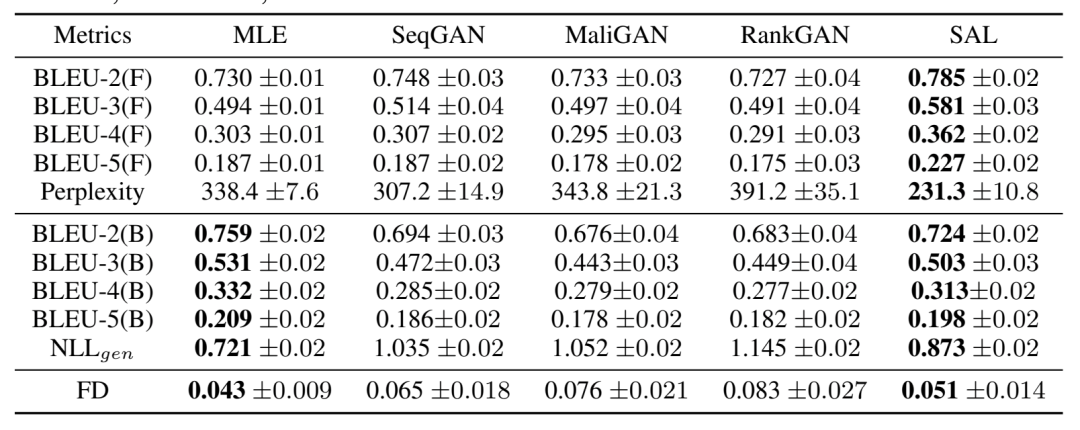
本文在模拟数据集(Synthetic Dataset)和真实数据集(COCO & EMNLP WMT17)上进行了文本生成的实验,并与之前的文本生成 GAN 模型的效果进行比较,结果如表5、6所示。可以看到,本文提出的 SAL 算法在反应生成文本的质量和多样性的众多指标上比此前的文本 GAN 模型都有显著的提升。在未来,我们希望探索 SAL 训练机制在图像生成 GAN 领域的应用。
表5:不同文本 GAN 模型在模拟数据集上的表现比较
表6:不同文本 GAN 模型在真实数据集上的表现比较
论文地址:https://openreview.net/forum?id=SygXPaEYvH
适用于下游任务的通用特征表示预训练是深度网络成功的标志之一。在计算机视觉领域,深度网络在 ImageNet 数据集进行图像分类的预训练过程,被发现可广泛提高多种图像识别任务的效果。在自然语言处理领域中,Transformer 模型在大规模语料库中使用语言模型进行预训练的过程,也被证明可广泛提高多种自然语言处理任务的效果。
但对于计算机视觉和自然语言处理领域交叉的任务,例如图像标题生成、视觉问答、视觉常识推理等,缺少这种预训练的通用多模态特征表示。一般来说,此前的视觉-语言模型分别使用计算机视觉或自然语言处理领域中的预训练模型进行初始化,但如果目标任务数据量不足,模型容易过拟合从而损失性能。并且对于不同的视觉-语言任务,其网络架构一般是经过特殊设计的,因此很难通过视觉-语言联合预训练的过程帮助下游任务。
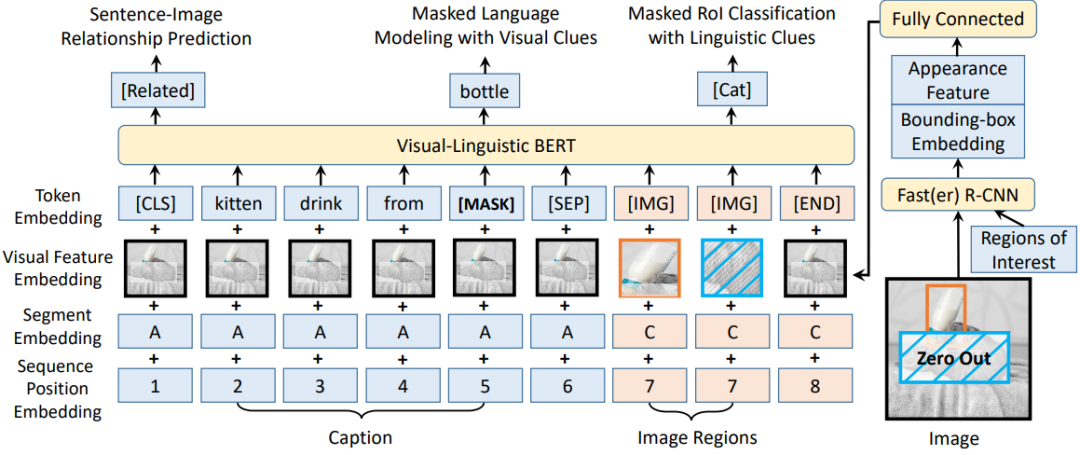
本文提出了一种可广泛应用于视觉-语言任务的预训练通用特征表示,称为 Visual-Linguistic BERT,简称 VL-BERT,其架构如下图所示:
VL-BERT 的主干网络使用 Transformer Attention 模块,并将视觉与语言嵌入特征作为输入,其中输入的每个元素是来自句中单词或图像中的感兴趣区域(Region of Interests,简称 RoIs)。在模型训练的过程中,每个元素均可以根据其内容、位置、类别等信息自适应地聚合来自所有其他元素的信息。在堆叠多层 Transformer Attention 模块后,其特征表示即具有更为丰富的聚合、对齐视觉和语言线索的能力。
为了更好地建模通用的视觉-语言表示,本文在大规模视觉-语言语料库中对 VL-BERT进行了预训练。采用的预训练数据集为图像标题生成数据集 Conceptual Captions,其中包含了大约330万个图像-标题对。在预训练结束后,使用微调来进行下游任务的训练。实验证明此预训练过程可以显著提高下游的视觉-语言任务的效果,包括视觉常识推理(Visual Commonsense Reasoning)、视觉问答(Visual Question Answering)与引用表达式理解(Referring Expression Comprehension)。
疫情严重,ICLR2020 将举办虚拟会议,非洲首次 AI 国际顶会就此泡汤
疫情影响,ICLR 突然改为线上模式,2020年将成为顶会变革之年吗?
1、直播
回放 | 华为诺亚方舟ICLR满分论文:基于强化学习的因果发现
16. 华盛顿大学:图像分类中对可实现攻击的防御(视频解读)
17. 超越传统,基于图神经网络的归纳矩阵补全
18. 受启诺奖研究,利用格网细胞学习多尺度表达(视频解读)
19. 神经正切,5行代码打造无限宽的神经网络模型
1、ACL 2020 - 复旦大学系列解读
直播主题:不同粒度的抽取式文本摘要系统
主讲人:王丹青、钟鸣
直播时间:4月 25 日,(周一晚) 20:00整。
直播主题:结合词典的中文命名实体识别【ACL 2020 - 复旦大学系列解读之(二)】
主讲人:马若恬, 李孝男
直播时间:4月 26 日,(周一晚) 20:00整。
直播主题:ACL 2020 | 基于对抗样本的依存句法模型鲁棒性分析
【ACL 2020 - 复旦大学系列解读之(三)】
主讲人:曾捷航
直播时间:4月 27 日,(周一晚) 20:00整。
2、ICLR 2020 系列直播
直播主题:ICLR 2020丨Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
主讲人:王维埙
回放链接:http://mooc.yanxishe.com/open/course/793
直播主题:ICLR 2020丨通过负采样从专家数据中学习自我纠正的策略和价值函数
主讲人:罗雨屏
回放链接:http://mooc.yanxishe.com/open/course/802(回放时间:4月25日上午10点)
直播主题:ICLR 2020丨分段线性激活函数塑造了神经网络损失曲面
主讲人:何凤翔
直播时间:4月24日 (周五晚) 20:00整
扫码关注[ AI研习社顶会小助手] 微信号,发送关键字“ICLR 2020+直播” 或 “ACL 2020+直播”,即可进相应直播群,观看直播和获取课程资料。
![]()